







什么是过拟合,欠拟合?
1.过拟合:学习器把训练样本学得"太好了",很可能已经把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质,这样就会导致泛化能力下降,这就是过拟合。
换一种说法就是模型过度拟合,在训练集(training set)上表现好,但是在测试集上效果差,也就是说在已知的数据集合中非常好,但是在添加一些新的数据进来训练效果就会差很多,造成这样的原因是考虑影响因素太多,超出自变量的维度过于多了。
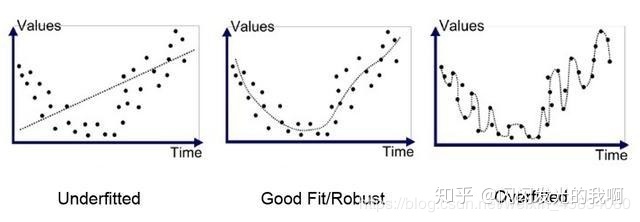
上图第三幅图则为过拟合。
2.欠拟合:就是模型没有很好地捕捉到数据特征,不能够很好地拟合数据。
上图第一幅图则为欠拟合。常见引起过拟合的原因
- 建模样本选取有误,如样本数量太少,选样方法错误,样本标签错误等,导致选取的样本数据不足以代表预定的分类规则;
- 样本噪音干扰过大,使得机器将部分噪音认为是特征从而扰乱了预设的分类规则;
- 假设的模型无法合理存在,或者说是假设成立的条件实际并不成立;
- 参数太多,模型复杂度过高。
常见引起过拟合的处理方法
过拟合是无法彻底避免的,我们所能做的只是“缓解”。
- 在神经网络模型中,可使用权值衰减的方法,即每
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3662
3662











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









