





备份:banQ/pythonProject/TensorRT_demo
1.根据pytorch保存权重的方法保存
两种方法
#第一种方法
'''保存weight等信息'''
state = {‘net':model.state_dict(), 'optimizer':optimizer.state_dict(), 'epoch':epoch}
torch.save(state, dir)
'''读取方法'''
checkpoint = torch.load(dir)
model.load_state_dict(checkpoint['net'])
optimizer.load_state_dict(checkpoint['optimizer'])
start_epoch = checkpoint['epoch'] + 1
#第二种方法
'''只保存weight信息'''
torch.save(net.state_dict(), Path)
'''读取方法'''
model.load_state_dict(torch.load(Path))2.将.pth文件转成.onnx的通用格式
代码如下:主要流程就是定义好输入、创建并载入模型后,即可用pytorch的onnx接口转将.pth转成.onnx
#定义参数
input_name = ['input']
output_name = ['output']
'''input为输入模型图片的大小'''
input = torch.randn(1, 3, 32, 32).cuda()
# 创建模型并载入权重
model = MobileNetV2(num_classes=4)
model_weight_path = "./MobileNetV2.pth"
model.load_state_dict(torch.load(model_weight_path))
model.cuda()
#导出onnx
torch.onnx.export(model, input, 'mobileNetV2.onnx', input_names=input_name, output_names=output_name, verbose=True)
3.将onnx转换成engine
(1)下载好TensorRT库
(2)进入~/samples/trtexec,运行
make 在~/bin下面会多出trtexec和trtexec_debug两个文件
(3)在TensorRT的目录下运行
'''半精度导出'''
./bin/trtexec --onnx=~.onnx --fp16 --saveEngine=~.engine
'''全精度导出'''
./bin/trtexec --onnx=~.onnx --saveEngine=~.engine 其中‘./bin/trtexec’为刚刚生成的trtexec所在路径,~.onnx为onnx文件所在路径,~.engine为engine的生成路径
4.用tensorRT自带的API,看engine做inference的时间
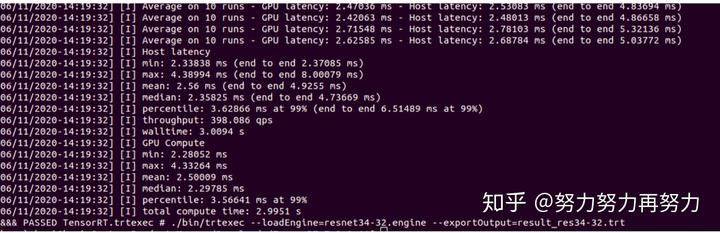
trtexec --loadEngine=32.engine --exportOutput=~.trt 其中~.engine为engine文件的路径,~.trt为输出的文件路径。(实测环境1660显卡,resnet34在pytorch的inference时间为6.66ms,tensorRT FP32:2.5ms,tensorRT FP16:1.28ms)
5.用.engine文件,做inference
代码如下:
import torchvision
import torch
from torch.autograd import Variable
import onnx
from model import MobileNetV2
from torchvision import transforms
import pycuda.autoinit
import numpy as np
import pycuda.driver as cuda
import tensorrt as trt
import torch
import os
import time
from PIL import Image
import cv2
import torchvision
#数据转换
data_transform = transforms.Compose(
[transforms.Resize(40),
transforms.CenterCrop(32),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
# 创建模型[图片]
model = MobileNetV2(num_classes=4)
model_weight_path = "./MobileNetV2.pth"
model.load_state_dict(torch.load(model_weight_path))
model.cuda()
filename = './0.jpg'
# img = Image.open(filename)
# img = data_transform(img)
# img=img.unsqueeze(0).cuda()
# t1=time.time()
# for i in range(100):
# model(img)
# t2=time.time()
# print('inference time : ',(t2-t1)*1000/100 ,'ms')
filename = './0.jpg'
max_batch_size = 1
onnx_model_path = 'mobilenetV2.onnx'
TRT_LOGGER = trt.Logger() # This logger is required to build an engine
def get_img_np_nchw(filename):
img = Image.open(filename)
img = data_transform(img)
img = torch.unsqueeze(img, dim=0)
img=img.numpy()
return img
class HostDeviceMem(object):
def __init__(self, host_mem, device_mem):
"""Within this context, host_mom means the cpu memory and device means the GPU memory
"""
self.host = host_mem
self.device = device_mem
def __str__(self):
return "Host:n" + str(self.host) + "nDevice:n" + str(self.device)
def __repr__(self):
return self.__str__()
def allocate_buffers(engine):
inputs = []
outputs = []
bindings = []
stream = cuda.Stream()
for binding in engine:
size = trt.volume(engine.get_binding_shape(binding)) * engine.max_batch_size
dtype = trt.nptype(engine.get_binding_dtype(binding))
# Allocate host and device buffers
host_mem = cuda.pagelocked_empty(size, dtype)
device_mem = cuda.mem_alloc(host_mem.nbytes)
# Append the device buffer to device bindings.
bindings.append(int(device_mem))
# Append to the appropriate list.
if engine.binding_is_input(binding):
inputs.append(HostDeviceMem(host_mem, device_mem))
else:
outputs.append(HostDeviceMem(host_mem, device_mem))
return inputs, outputs, bindings, stream
def get_engine(max_batch_size=1, onnx_file_path="", engine_file_path="",
fp16_mode=False, int8_mode=False, save_engine=False,
):
"""Attempts to load a serialized engine if available, otherwise builds a new TensorRT engine and saves it."""
def build_engine(max_batch_size, save_engine):
"""Takes an ONNX file and creates a TensorRT engine to run inference with"""
with trt.Builder(TRT_LOGGER) as builder,
builder.create_network() as network,
trt.OnnxParser(network, TRT_LOGGER) as parser:
builder.max_workspace_size = 1 << 30 # Your workspace size
builder.max_batch_size = max_batch_size
# pdb.set_trace()
builder.fp16_mode = fp16_mode # Default: False
builder.int8_mode = int8_mode # Default: False
if int8_mode:
# To be updated
raise NotImplementedError
# Parse model file
if not os.path.exists(onnx_file_path):
quit('ONNX file {} not found'.format(onnx_file_path))
print('Loading ONNX file from path {}...'.format(onnx_file_path))
with open(onnx_file_path, 'rb') as model:
print('Beginning ONNX file parsing')
parser.parse(model.read())
print('Completed parsing of ONNX file')
print('Building an engine from file {}; this may take a while...'.format(onnx_file_path))
engine = builder.build_cuda_engine(network)
print("Completed creating Engine")
if save_engine:
with open(engine_file_path, "wb") as f:
f.write(engine.serialize())
return engine
if os.path.exists(engine_file_path):
# If a serialized engine exists, load it instead of building a new one.
print("Reading engine from file {}".format(engine_file_path))
with open(engine_file_path, "rb") as f, trt.Runtime(TRT_LOGGER) as runtime:
return runtime.deserialize_cuda_engine(f.read())
else:
return build_engine(max_batch_size, save_engine)
def do_inference(context, bindings, inputs, outputs, stream, batch_size=1):
# Transfer data from CPU to the GPU.
[cuda.memcpy_htod_async(inp.device, inp.host, stream) for inp in inputs]
# Run inference.
context.execute_async(batch_size=batch_size, bindings=bindings, stream_handle=stream.handle)
# Transfer predictions back from the GPU.
[cuda.memcpy_dtoh_async(out.host, out.device, stream) for out in outputs]
# Synchronize the stream
stream.synchronize()
# Return only the host outputs.
return [out.host for out in outputs]
def postprocess_the_outputs(h_outputs, shape_of_output):
h_outputs = h_outputs.reshape(*shape_of_output)
return h_outputs
#图像预处理
img_np_nchw = get_img_np_nchw(filename)
img_np_nchw = img_np_nchw.astype(dtype=np.float32)
#fp16
fp16_mode = True
int8_mode = False
trt_engine_path = './model_fp16_{}_int8_{}.trt'.format(fp16_mode, int8_mode)
engine_file_path='./resnet34-32.engine'
# 创建engine
engine = get_engine(max_batch_size, onnx_model_path,engine_file_path, trt_engine_path, fp16_mode, int8_mode)
context = engine.create_execution_context()
inputs, outputs, bindings, stream = allocate_buffers(engine) # input, output: host # bindings
shape_of_output = (max_batch_size, 4)
inputs[0].host = img_np_nchw.reshape(-1)
t1 = time.time()
for i in range(100):
trt_outputs = do_inference(context, bindings=bindings, inputs=inputs, outputs=outputs, stream=stream) # numpy data
t2 = time.time()
feat = postprocess_the_outputs(trt_outputs[0], shape_of_output)
print('feat 16:',feat)
print("Inference time with the TensorRT FP16 engine: {} ms".format((t2-t1)*1000/100))如果内容有帮助到您,希望大家多多点赞+收藏+关注!!!
经常会在知乎中分享自己的学习笔记,和大家一起学习进步!!!
有问题大家可以在评论区打出,一定及时给大家回复!!!














 8394
8394











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









