







目录
系统环境:
- Ubuntu 18.04
- Cuda 11.3
- Cudnn 8.4.1
重要: cuda,cudnn,tensorRT要用deb装就都用deb,要用压缩包装就都用压缩包(cuda用*.run)
0、C++ 调用Python模型
0.1 库安装
下载libtorch,可官网
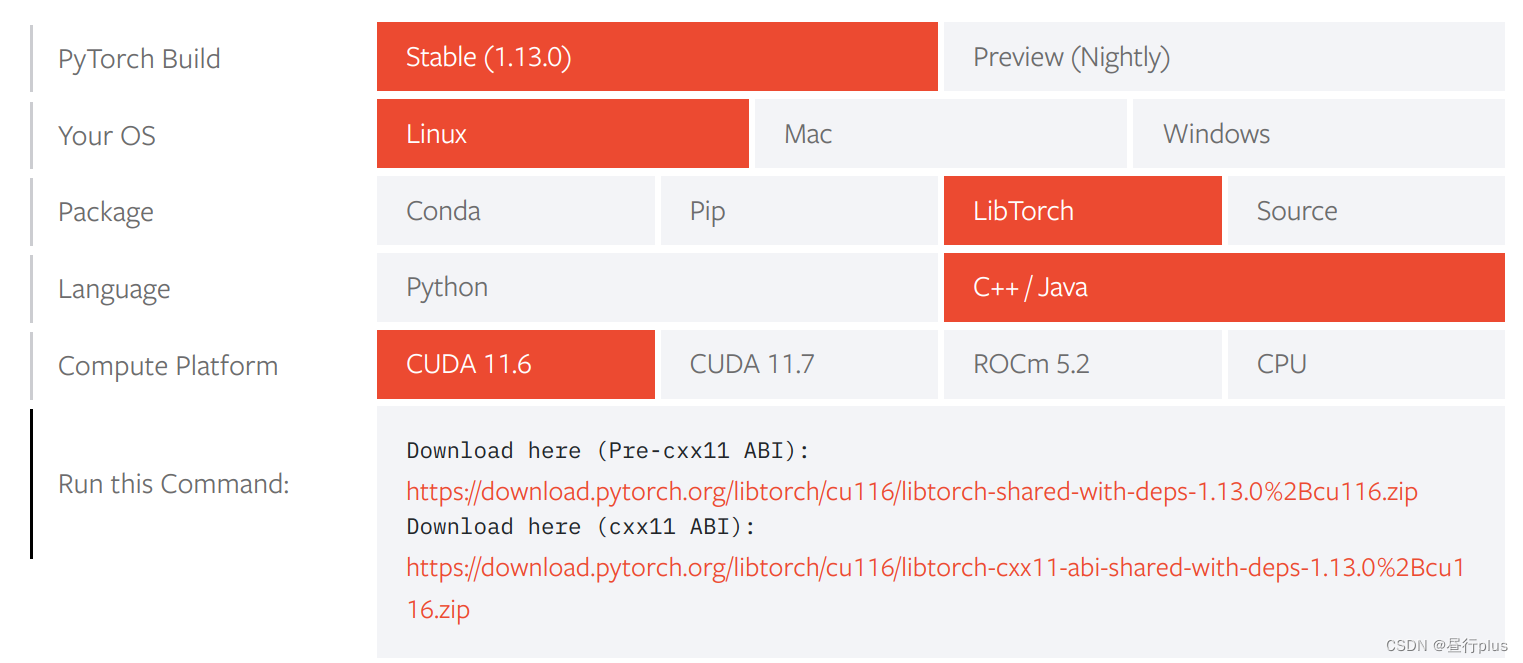
但官网可能没有你期望的cuda版本,我找到了一位做过历史版本统计的大神,复制链接到浏览器网址即可下载
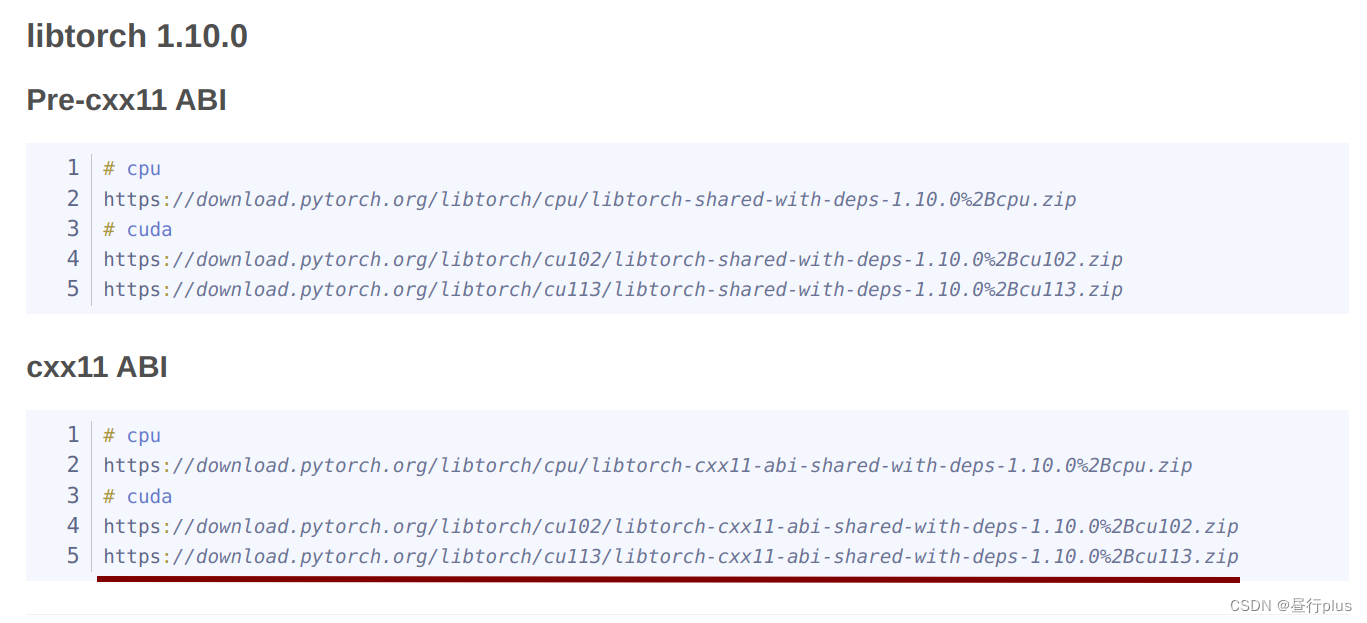
下载完成后解压即可
0.1 Cmake测试
test.cpp
//
// Created by daybeha on 2022/12/13.
//
#include <iostream>
#include "torch/torch.h"
using namespace std;
int main(){
torch::Tensor tensor = torch::eye(3);
cout << tensor <<endl;
return 0;
}
CmakeList.txt
cmake_minimum_required(VERSION 3.5)
project(dcgan LANGUAGES CXX)
set(CMAKE_CXX_STANDARD 14) # 我的版本下,调用 libtorch C++11版本不行
set(CMAKE_CXX_STANDARD_REQUIRED ON)
set(Torch_DIR /home/datbeha/libtorch/share/cmake/Torch) # 我的 libtorch 的路径
find_package(Torch REQUIRED)
add_executable(test test.cpp)
target_link_libraries(test ${TORCH_LIBRARIES})
1 、Pytorch -> ONNX
网上相关流程很多,我就不重复了
可以参考Pytorch分类模型转onnx以及onnx模型推理
或者直接看Pytorch官方怎么干的。
最主要是是这个函数:
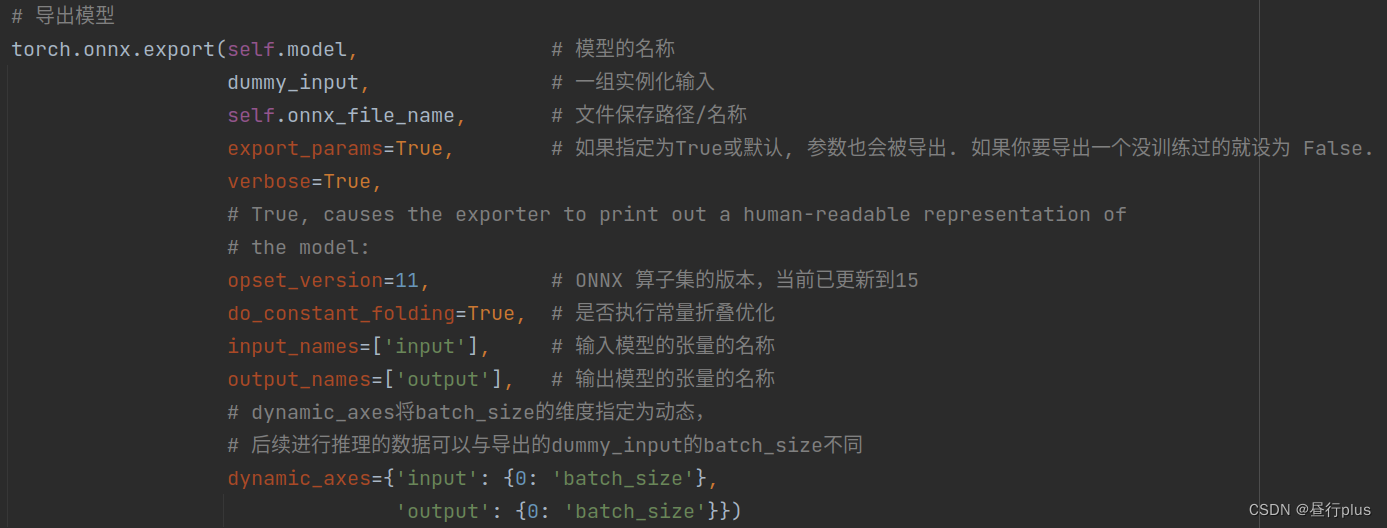
onnxruntime调用onnx模型推理时有一个provider的参数,可选 [‘TensorrtExecutionProvider’, ‘CUDAExecutionProvider’, ‘CPUExecutionProvider’],不知道是还需要其他设置还是怎样,'TensorrtExecutionProvider’和’CPUExecutionProvider’的推理速度是一样的,只有’CUDAExecutionProvider’相对比另两者快一个数量级。
但不如原本的Pytroch模型推理快……, 这肯定是不能采用的!
2、 ONNX -> TensorRT
TensorRT是英伟达官方出的,自己的模型调自己的显卡,应当是最优的吧?网上很多帖子确实也都是这么写的。抱着这个期望,再来研究研究怎么转到TensorRT进行部署。
2.1 库安装
TensorRT 提供C++和Python版本的API,并且二者相互独立。
我们大可只装其一。我这里介绍pip wheel 、debian和tar包的安装方法,其他如rpm、zip的可以移步官方安装教程(英文)。
TensorRT – Python
仅用python的话这一块就足够了,不用下载deb、tar 或者 zip文件。 如果你还想试试C++,并且你还比较喜欢Cmake的话,建议 直接跳去 TensorRT – C++ tar 的一节
TensorRT 8.5 以上的版本用以下命令装:
pip install --upgrade tensorrt
# pip install --upgrade tensorrt==8.5.1.7
我装的是8.4,用这种命令装:
pip install --upgrade setuptools pip
pip install nvidia-pyindex
pip install --upgrade nvidia-tensorrt
# pip install --upgrade nvidia-tensorrt==8.4.3.1
pip install pycuda
测试一下:
python3
>>> import tensorrt
>>> print(tensorrt.__version__)
>>> assert tensorrt.Builder(tensorrt.Logger())
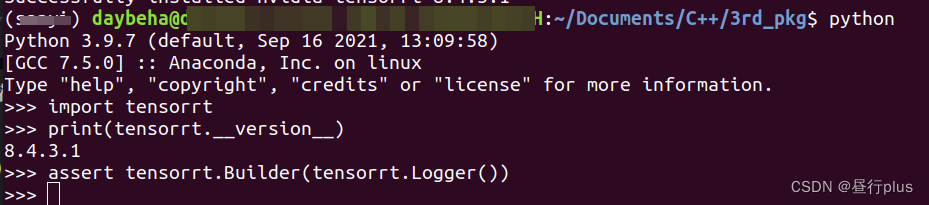
因为我这边对耗时要求较高,时间较紧,主要测了C++版本,Python的实际调用可以参考官方的Demo
TensorRT – C++ deb
这种方法没有给库文件一个单独的文件夹,导致CMake调用很不优美。难过能力有限,最终还是用的这种……
官网下载cuda对应版本的TensorRT库(看名就知道了)。 我下载的是面前最新的 TensorRT 8 (保险起见不用目前最新的8.5)
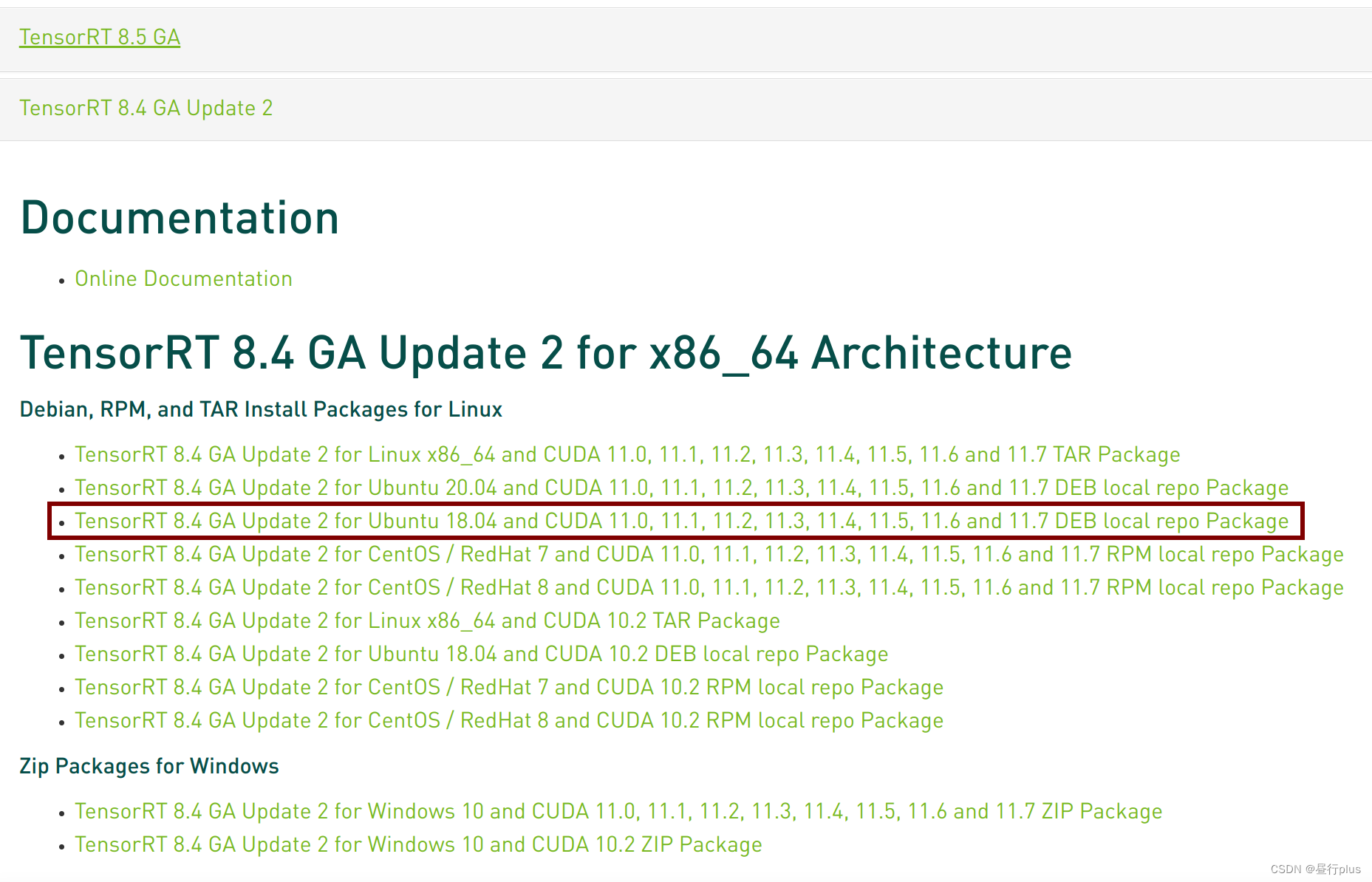
os="ubuntuxx04"
tag="cudax.x-trt8.x.x.x-ea-yyyymmdd"
sudo dpkg -i nv-tensorrt-repo-${os}-${tag}_1-1_amd64.deb
# sudo dpkg -i nv-tensorrt-repo-ubuntu1804-cuda11.6-trt8.4.3.1-ga-20220813_1-1_amd64.deb
sudo apt-key add /var/nv-tensorrt-repo-${tag}/7fa2af80.pub
# sudo apt-key add /var/nv-tensorrt-repo-ubuntu1804-cuda11.6-trt8.4.3.1-ga-20220813/c1c4ee19.pub
sudo apt-get update
sudo apt-get install tensorrt
虽然命令行显示的是cuda11.6,不过没关系,上面官网不是写着11.0-11.6都适用嘛。
pip install numpy
sudo apt-get install python3-libnvinfer-dev
然后安装执行onnx的相关库:
pip install onnx
sudo apt-get install onnx-graphsurgeon
如果你还打算用TensorFlow,执行下面命令,否则不用。
pip install protobuf
sudo apt-get install uff-converter-tf
检查下安装是否成功:
dpkg -l | grep TensorRT

卸载方法
sudo apt-get purge "libnvinfer*"
sudo apt-get purge "nv-tensorrt-repo*"
sudo apt-get purge onnx-graphsurgeon
sudo pip3 uninstall tensorrt
sudo pip3 uninstall uff
sudo pip3 uninstall graphsurgeon
sudo pip3 uninstall onnx-graphsurgeon
TensorRT – C++ tar (推荐)
tar的安装方法对库的路径更自由些,对使用者的要求也更高点
安装还是去官网

tar -xzvf TensorRT-8.4.3.1.Linux.x86_64-gnu.cuda-11.6.cudnn8.4.tar.gz
cd TensorRT-8.4.3.1.Linux.x86_64-gnu.cuda-11.6.cudnn8.4
# 个人习惯,也可以不做copy,只是后面的路径也要注意
cp -r TensorRT-8.4.3.1 /usr/local/include/TensorRT-8.4.3.1
修改环境变量:
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/usr/local/include/TensorRT-8.4.3.1/lib
alias trtexec="/usr/local/include/TensorRT-8.4.3.1/bin/trtexec"
# 如果是 deb 安装的,则可能是:
alias trtexec="/usr/src/tensorrt/bin/trtexec"
# or
alias trtexec="/usr/local/tensorrt/bin/trtexec"
之后 source ~/.bashrc
然后装 python 库:
cd TensorRT-8.4.3.1/python
conda activate tensorrt_env
# 根据 python版本选择,我的是python3.9
pip install tensorrt-8.4.3.1-cp39-none-linux_x86_64.whl
cd ../graphsurgeon
pip install graphsurgeon-0.4.6-py2.py3-none-any.whl
cd ../onnx_graphsurgeon
pip install onnx_graphsurgeon-0.3.12-py2.py3-none-any.whl
pip install 'pycuda<2021.1'
2.2 ONNX转TensorRT
通过下面一行命令就可以转换TensorRT格式了:
trtexec --onnx=2Dmodel.onnx --saveEngine=2Dmodel.trt
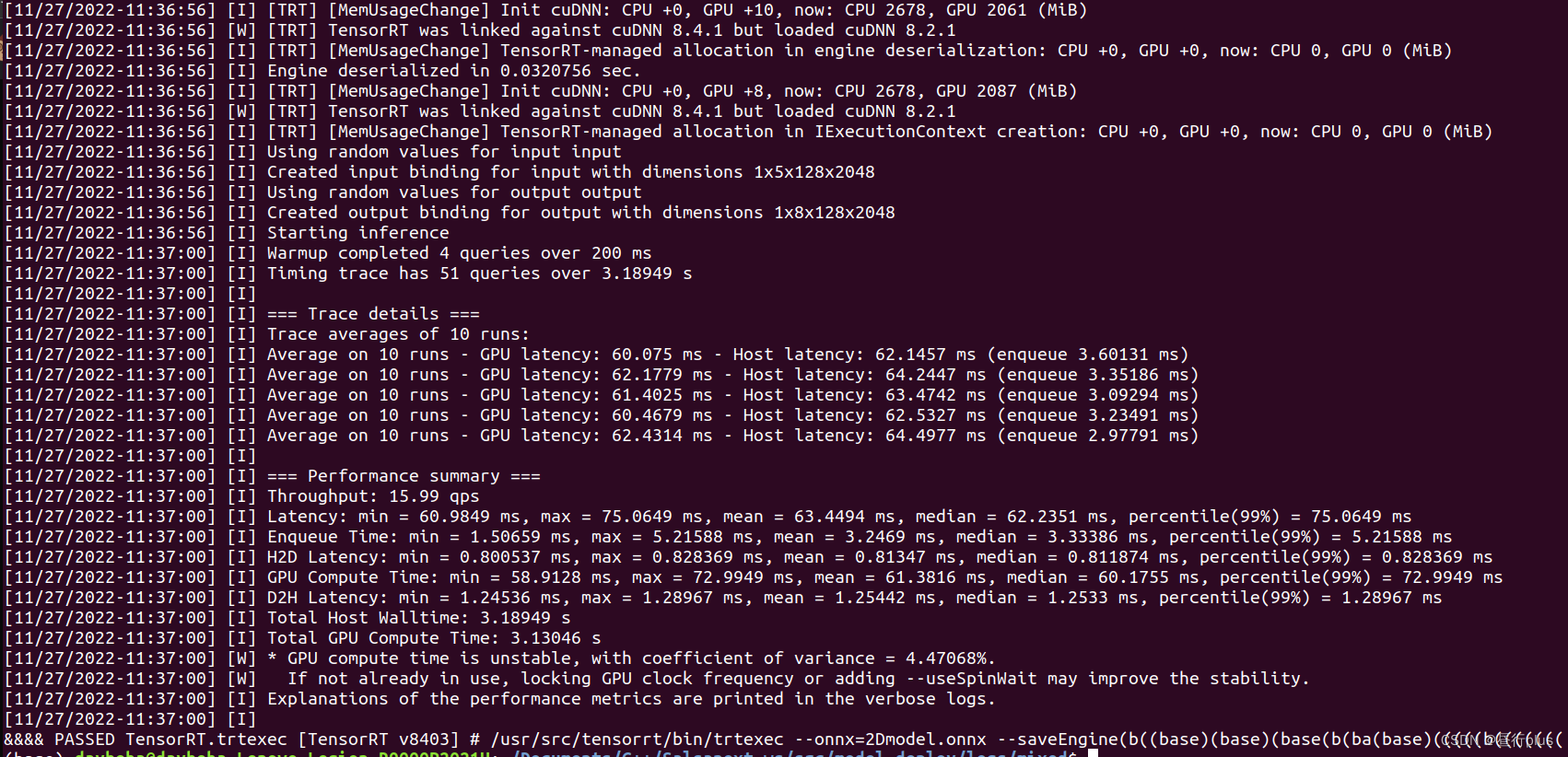
trtexec的更多参数参考这里
需要注意的是,**一定要保证你转换模型的显卡和调用的显卡具有相同算力!!!**不然要重新转换。
如你在2060转的trt模型,但是拷贝到了3080上去用,就会出现算力不匹配的问题:
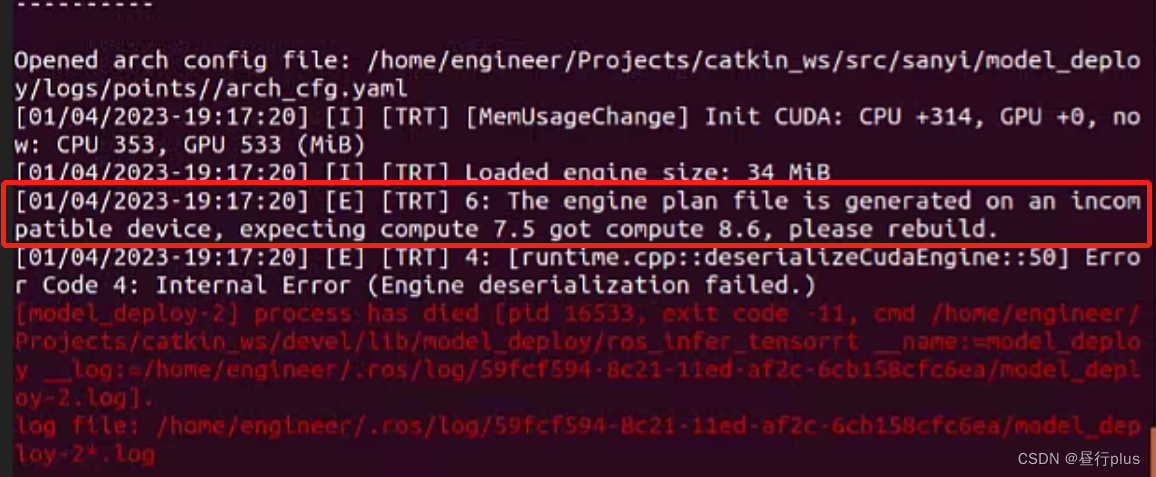
2.3 TensorRT部署
github 找到 TensorRT/quickstart/common
把common整个文件夹copy到 include下
├── include
│ ├── common
│ │ ├── logger.cpp
│ │ ├── logger.h
│ │ ├── logging.h
│ │ ├── util.cpp
│ │ └── util.h
│ └── others
是的,库文件我们只要这么多就行了。
CmakeList.txt
cmake_minimum_required(VERSION 3.13)
project(model_deploy)
#set(CMAKE_BUILD_TYPE Release)
set(CMAKE_BUILD_TYPE Debug)
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fexceptions" )
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
set(CMAKE_CXX_EXTENSIONS OFF)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11 -pthread -std=c++0x -fexceptions -no-pie -O3")
# CUDA
include_directories(CUDA_INCLUDE_DIRS "/usr/local/cuda-11.3/include")
set(CUDA_LIB "/usr/local/cuda-11.3/lib64/libcudart.so")
# TensorRT
## 这块 Developer API 用的,弄好了可以直接用TensorRT写网络而不是转换过来,可惜没跑通
#set(TensorRT_INCLUDE_DIRS "/usr/local/include/TensorRT-8.4.3.1/include"
# "/usr/local/include/TensorRT-8.4.3.1/samples/common"
# )
#set(TensorRT_LIB_PATH "/usr/local/include/TensorRT-8.4.3.1/lib")
#file(GLOB TRT_LIB "${TensorRT_LIB_PATH}/*.so" "${TensorRT_LIB_PATH}/stubs/*.so")
set(TRT_LIB "/usr/lib/x86_64-linux-gnu/libnvinfer.so"
# "/usr/lib/x86_64-linux-gnu/libnvinfer_plugin.so"
# "/usr/lib/x86_64-linux-gnu/libnvinfer_builder_resource.so.8"
# "/usr/lib/x86_64-linux-gnu/libnvcaffe_parser.so"
# "/usr/lib/x86_64-linux-gnu/libnvonnxparser.so"
# "/usr/lib/x86_64-linux-gnu/libnvparsers.so"
# "/usr/lib/x86_64-linux-gnu/libprotobuf.so"
# "/usr/lib/x86_64-linux-gnu/libprotobuf-lite.so"
)
message("Current CPU archtecture: ${CMAKE_SYSTEM_PROCESSOR}")
include_directories(
include
include/common
${catkin_INCLUDE_DIRS}
${CUDA_INCLUDE_DIRS}
)
# C++ branch
## TensorRT
add_executable(test_tensorrt src/test_tensorrt.cpp include/common/util.cpp include/common/logger.cpp)
target_link_libraries(test_tensorrt ${CUDA_LIB} ${TRT_LIB})
然后按照 quick start C++ 的步骤跑吧,不想copy了……
注意:
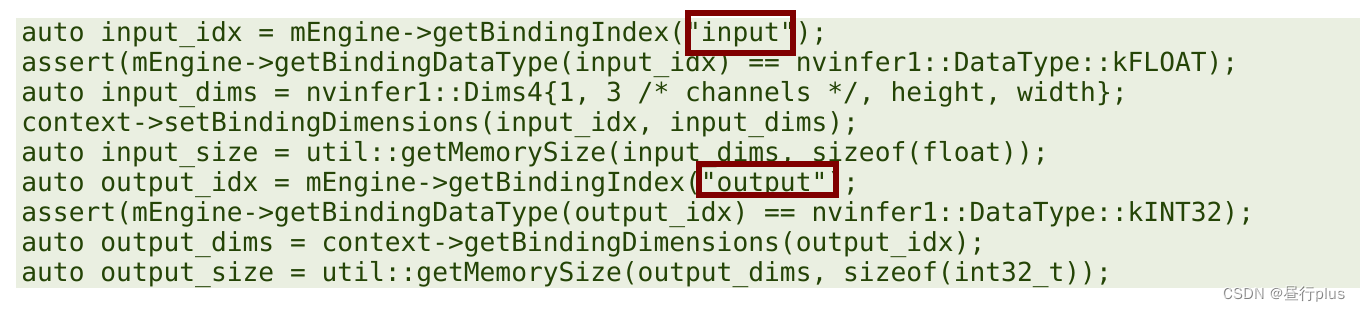
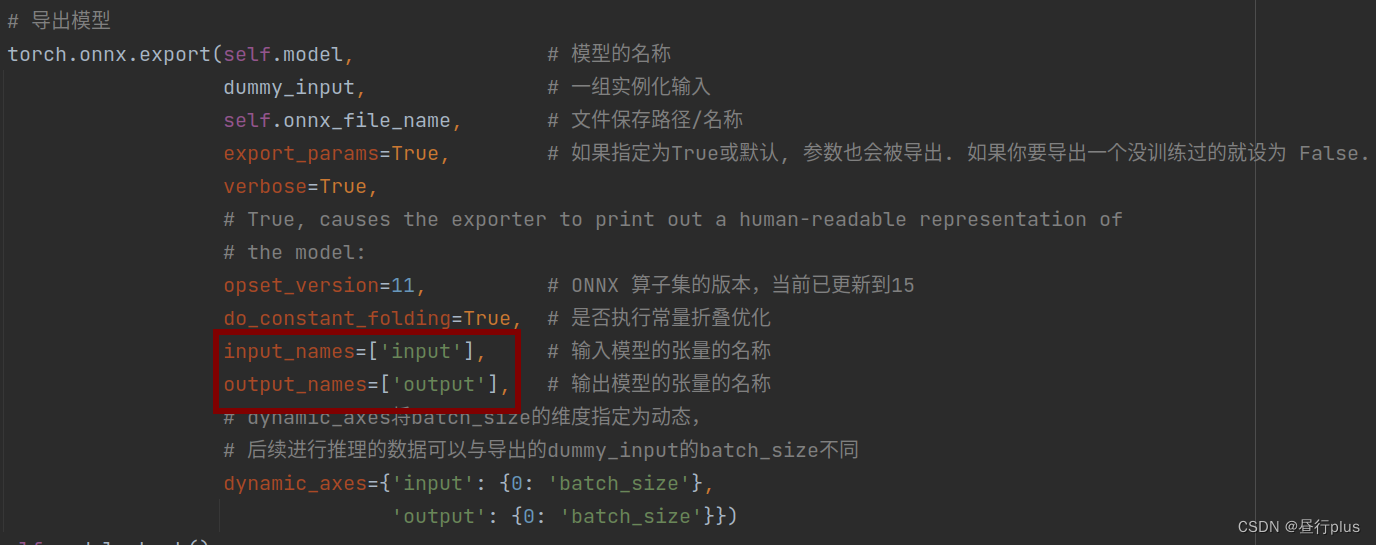
调用的时候这两个BingdingIndex是输入输出(也可以自定义其他的)
它们是与pth转onnx时的input_names, output_names对应的
除了makefile,剩下的都copy到camkeList.txt所在目录,然后就可以用Clion,或者命令行编译也行:
mkdir build
cd build
cmake ..
如果遇到下面问题
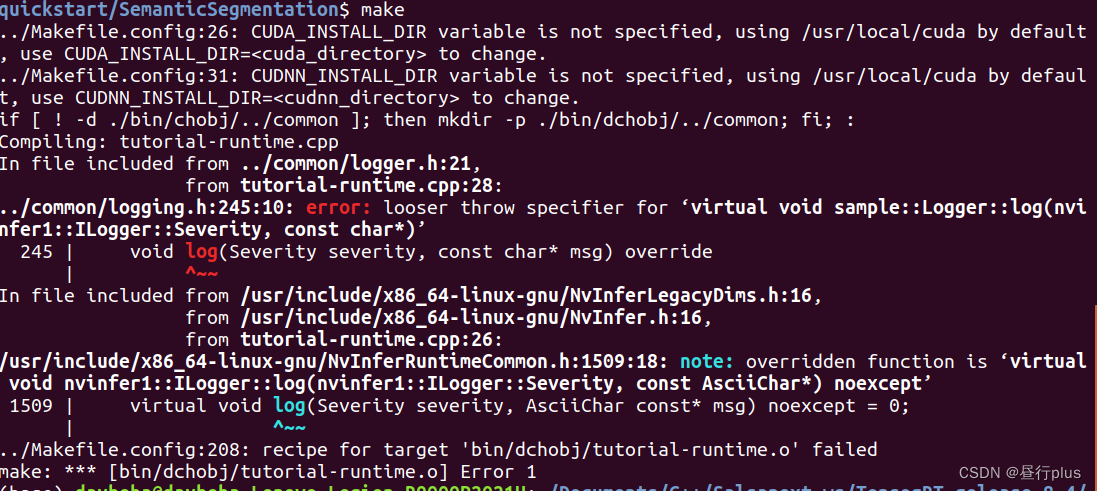
这是TensorRT版本问题,找到logging.h的245行,把 override 改成 noexcept 即可
另外更高级的使用参考Nvidia TensorRT Developer Guide,C++能力有限,想用Cmake跑,没跑通……
Reference
在Ubuntu下安装LibTorch
c++调用训练好的PyTorch模型
官方libtorch示例
Nvidia TensorRT Document
Nvidia TensorRT installation guide
Nvidia TensorRT Quick Start Guide
Nvidia TensorRT C++ API
















 1658
1658











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











