









被迫营业的小帅酱,分享内容相当干货了,哈哈哈哈。独乐乐不如众乐乐,今天就把小技巧搬运出来给大家瞅一瞅啦!
文章来源 | 恒源云社区
原文地址 | 如何加速pytorch训练?GPU利用率过低?
原文作者 | 小帅酱
想必有时候大家在用云服务器炼丹的时候会遇到GPU利用率忽高忽低,一会0%一会100%。这其实就是对GPU资源的浪费,因为GPU在浪费很多时间在等CPU和内存加载数据进来。最主要是云服务器每时每刻都在烧money,难免不心疼。描述效果如下图:
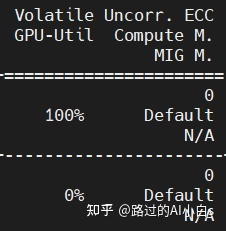
那么如何解决???
我分享一下我个人在平时用的比较多的方法:<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3643
3643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









