





从第一版的yolov3(http://github.com/qqwweee/keras-yolo3)在这位q神翻译出来后,在下一直跟进yolo的发展,两年前第一次迁移了q神的keras版。最近keras版的yolov4(http://github.com/Ma-Dan/keras-yolo4)也问世了。由于tf发展到了tf2+,很多模型建立过程、命名规则、文件读取方法以及keras的支持等,都做了非常大的调整,再加上该版本的代码是延续yolov3的代码,没有使用论文的很多tricks,加上历史遗留代码存在很多的不可读因素和局部地方的小bug。因此,基于以上两点考虑,在下联合一位cv从业同学完成了基于tf2版本的、用keras编写的yolov4.
请收下传送门:https://github.com/robbebluecp/tf2-yolov4
对于这版的yolov4,我们做了如下优化:
(1)数据增强。我们在之前的resize、色彩调整、旋转的基础上,增加了mixup、mosaic、任意
角度旋转(不建议用任意角度)、背景填充、pixel等数据增强策略;
(2)模型整合。对yolo整体网络结构和局部结构做详细拆分和更详细的整合。如darknet、spp、
pan等;
(3)loss优化。ciou优化、loss代码优化;
(4)convert调整。tf1+和tf2+对darknet权重文件的读取,从二进制流和命名方法上都有很大不
的不同,tf2+转换非常快,且跟tf1不能兼容;
(5)config配置文件取代动态传参;
(6)尽可能使np和tf分离,让训练和预测在一定程度上提速;
(7)生成器兼容、数据增强模块可扩展等其他优化。
我用voc2007数据集在V100显卡上训练到160+个epochs时,loss和val_loss差不多收敛到13+,预测准确率大约在40%-85%波动。随着预训练模型的加入或者更多epoch的训练,这个值会越来越小。
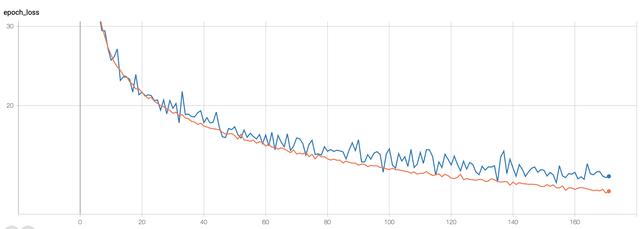
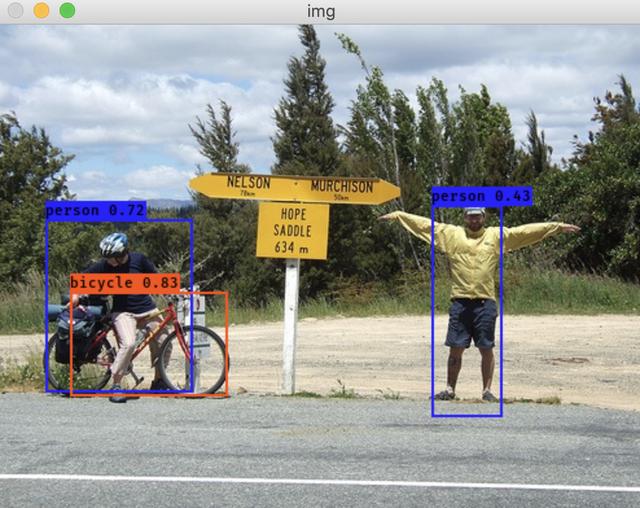
到200+epochs后,loss又进一步收敛(忘记留图了。。。)。loss收敛稳而慢,也侧面证明了我们的数据增强方案还是很有效的。以下展示以下增强效果图

rotate+mosaic
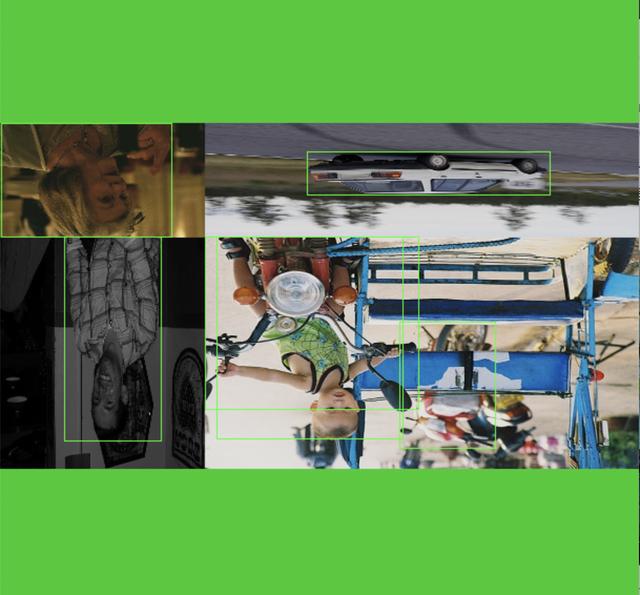
rotate+mosaic+resize

rotate+mixup+resize

flip+pixel+颜色微调
我的小伙伴说,这些增强有些过分了,尤其是mixup,甚至连人都不太分辨的处理,这些对模型训练也是有很大影响的,所以我们用了随机数控制增强频率。在Augment类中,你可以自己控制频率,可以自定义各种增强策略。增强虽好,不不要贪强奥~~
这个框架还有很多可以完善的地方,例如loss、augment、draw等等,希望各位来添砖补瓦,集思广益,哈哈哈~~欢迎各位cv、nlp爱好者戳戳戳!















 4068
4068











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









