






简化Pandas中的数据探索性分析,处理数据集形状和空值。
微信搜索关注《Python学研大本营》,加入读者群,分享更多精彩
简介
在本文中,我们将探讨数据探索性分析的两个基本方面:数据集形状和空值。我们将深入了解Pandas如何简化这些任务,重点关注需要同时分析多个表格的情况。使用的库是pandas和tabulate。
数据集形状
要检索单个表格的形状,我们可以使用.shape属性。例如,如果我们有一个名为df的DataFrame,我们可以使用df.shape访问其形状。这将返回一个包含DataFrame行数和列数的元组。
了解数据集的形状是很有价值的,因为它可以帮助我们理解其大小和结构。通过了解行的数量,我们可以估计我们正在处理的数据量,而列的数量则揭示了可用于分析的变量或特征。对形状信息的解读使我们能够对数据转换、内存需求和分析潜在限制做出明智的决策。
现在,我们将通过实际的示例来解释和利用真实世界场景中的形状信息。让我们按照以下步骤进行:
-
导入Pandas:首先导入Pandas库,这是在Python中进行数据操作和分析的强大工具:
import pandas as pd
-
读取表格:从Olist数据集中读取相关的表格,该数据集提供了巴西电子商务数据的数据集(https://www.kaggle.com/datasets/olistbr/brazilian-ecommerce)。这些表格代表了业务的不同方面,包括客户、订单、产品和评论。
customer = pd.read_csv('olist_customers_dataset.csv')
geolocation = pd.read_csv('olist_geolocation_dataset.csv')
order_items = pd.read_csv('olist_order_items_dataset.csv')
order_payments = pd.read_csv('olist_order_payments_dataset.csv')
order_reviews = pd.read_csv('olist_order_reviews_dataset.csv')
orders = pd.read_csv('olist_orders_dataset.csv')
products = pd.read_csv('olist_products_dataset.csv')
sellers = pd.read_csv('olist_sellers_dataset.csv')
-
将表格保存到字典中:将导入的表格存储在字典中。这种方法可以方便地管理和同时访问多个表格,便于跨数据集进行分析。
tables= {
"customer":customer,
"geolocation": geolocation,
"order_items":order_items,
"order_payments":order_payments,
"order_reviews":order_reviews,
"orders":orders,
"products":products,
"sellers":sellers
}
-
遍历表格:使用循环遍历字典并读取每个表格的形状。这提供了Olist数据集中每个表格的行数和列数:
for k,v in tabelas.items():
print(f'{k}:{v.shape}')

只需两行代码,我们就输出了所有的形状。
处理多个表格中的空值
识别和处理空值是数据分析中的一项关键任务,因为缺失的数据可能会影响结果的准确性和可靠性。
识别具有空值的列的最简单方法是结合使用.isna()和.sum()方法:
orders.isna().sum()
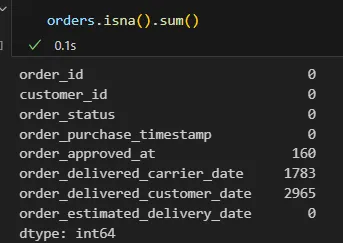
通过将每列中空值的总和除以表格中的记录总数,并将其乘以100,我们可以计算出空值的百分比。这样,就能了解每列中缺失数据的情况。分析空值的百分可使我们能够优先处理具有更高缺失值比例的列,从而提高数据分析的准确性和有效性。
orders.isna().sum()/len(orders) * 100
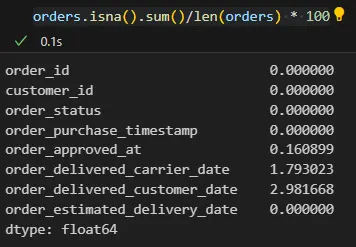
经过分析,我们发现空值最多的列,即订单表,约有3%的空值。
现在让我们对多个表格执行相同的分析操作。
通过使用以下代码,你将能够在分析中识别并显示任何数据集的空值:
from tabulate import tabulate
for k, v in tables.items():
# 用列名创建一个列表
cols = v.columns.tolist()
# 创建一个列表,列出每一列的空值的百分比
null_values = [v[col].isna().sum() / len(v) * 100 for col in cols]
# 用列名和空值创建一个列表
formatted_table = [[col, null_value] for col, null_value in zip(cols, null_values)]
# 输出格式化的表格
print(f"\nNull values in table {k.upper()}:\n")
print(tabulate(formatted_table, headers=["Column", "Percentage of Null Values"], tablefmt="grid"))
print('\n')
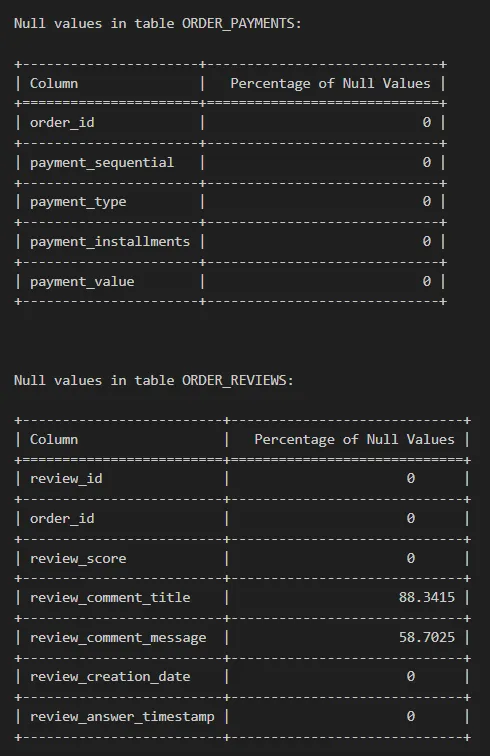
对于每个数据集,可以看到有的列的空值比例为0,而有的列具有较多的空值。
推荐书单

【秋日阅读企划】点击下方链接立享优惠,叠加五折使用
秋日阅读企划![]() https://pro.m.jd.com/mall/active/2Z3HoZGKy5i9aEpmoTUZnmcoAhHg/index.html
https://pro.m.jd.com/mall/active/2Z3HoZGKy5i9aEpmoTUZnmcoAhHg/index.html
《Pandas1.x实例精解》
《Pandas1.x实例精解》详细阐述了与Pandas相关的基本解决方案,主要包括Pandas基础,DataFrame基本操作,创建和保留DataFrame,开始数据分析,探索性数据分析,选择数据子集,过滤行,对齐索引,分组以进行聚合、过滤和转换,将数据重组为规整形式,组合Pandas对象,时间序列分析,使用Matplotlib、Pandas和Seaborn进行可视化,调试和测试等内容。此外,该书还提供了相应的示例、代码,以帮助读者进一步理解相关方案的实现过程。 《Pandas1.x实例精解》适合作为高等院校计算机及相关专业的教材和教学参考书,也可作为相关开发人员的自学用书和参考手册。
Pandas1.x实例精解![]() https://item.jd.com/13255935.html
https://item.jd.com/13255935.html

精彩回顾
微信搜索关注《Python学研大本营》,加入读者群
访问【IT今日热榜】,发现每日技术热点















 939
939











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









