






GPT-4 Turbo具有更便宜的API和更长的128K上下文窗口。
微信搜索关注《Python学研大本营》,加入读者群,分享更多精彩

一、简介
在发布GPT-4(点击了解GPT-4)仅仅八个月后,OpenAI推出了更新的模型GPT-4 Turbo,该模型具有可以在一次提示中容纳300页书的上下文窗口,并且提供更便宜的API访问。
《GPT-4已来,Python API使用最新版GPT》(点击查看GPT-4 API)
【GPT-4 Turbo】:https://openai.com/blog/new-models-and-developer-products-announced-at-devday

二、GPT-4 Turbo的新功能有哪些?
以下是GPT-4 Turbo的主要特点:
-
128K上下文窗口(比GPT-4大16倍)。
-
与GPT-4相比,输入token的价格降低了3倍,输出token的价格降低了2倍。
-
它具有截至2023年4月的知识(GPT-4的知识截止日期为2022年1月)。
【GPT-4 Turbo价格】:https://openai.com/pricing#gpt-4-turbo
三、如何访问?
对于付费用户,GPT-4 Turbo现在是ChatGPT中默认使用的模型。如果拥有OpenAI账户并已经获得了GPT-4的访问权限,可以通过在Playground上切换到gpt-4-11-6-preview模型来访问新模型。
OpenAI Playground截图
GPT-4 Turbo对于所有付费开发者来说都是可用的,可以通过在API中传递gpt-4-1106-preview来尝试。以下是使用JavaScript的聊天完成请求示例:
import OpenAI from "openai";
const openai = new OpenAI();
async function main() {
const completion = await openai.chat.completions.create({
messages: [{ role: "system", content: "You are a helpful assistant." }],
model: "gpt-4-1106-preview",
});
console.log(completion.choices[0]);
}
main();
以下是使用Python实现的方法:
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4-1106-preview",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
]
)
print(completion.choices[0].message)
四、API定价
作为开发者,降低定价是最令人兴奋的一项更新。OpenAI已将输入token的价格降低了3倍,将输出token的价格降低了2倍。这使得新模型对于规模较小的开发者和初创公司更加易于获取。
GPT-4 Turbo的API价格:

OpenAI GPT-4 Turbo定价
之前的GPT-4 API价格:

OpenAI GPT-4定价
token是用于自然语言处理的词片段。对于英文文本,1个token大约等于4个字符或0.75个单词。
此外,ChatGPT API的访问费用与ChatGPT Plus订阅费用是分开计费的。用户可以在OpenAI账户的使用页面上监控自己的使用情况。
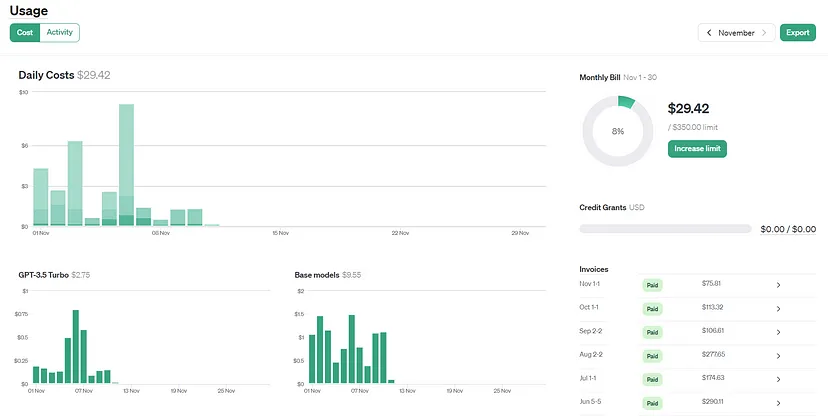
OpenAI使用情况界面
五、自动切换工具
在最新的ChatGPT用户界面中,下拉菜单已经消失了。它被替换为仅有的三个选项:GPT-4、GPT-3.5和插件。
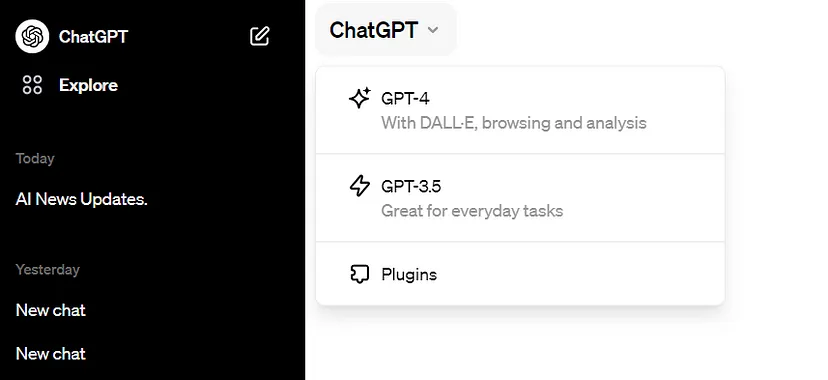
ChatGPT模型选择
现在,GPT-4 Turbo可自动为用户选择合适的工具。
“我们听到了用户的反馈。那个模型选择器真的很烦人。” —— Sam Altman
例如,如果用户要求AI生成一张图片,它现在会聪明地使用Dall-E 3来生成图片。
六、最后的思考
总的来说,很高兴看到OpenAI在语言模型方面的快速创新。它们无疑是令人兴奋的,为基于GPT的创新应用提供了广泛的可能性。
然而,思考一下OpenAI的战略方法也很有意思。最初,OpenAI发布了他们的API,允许开发者进行构建和创新,实际上承担了早期采用和用户参与的风险。事实证明,OpenAI 的这一举措是明智之举,因为它不仅培养了一个多样化的应用生态系统,还为他们提供了对最受需求的功能的洞察。
现在,OpenAI似乎正在有选择地将这些受欢迎的功能直接集成到他们的平台中,有效地精选了社区开发的最佳产品和服务。
推荐书单
《面向移动设备的深度学习—基于TensorFlow Lite,ML Kit和Flutter》
《面向移动设备的深度学习—基于TensorFlow Lite,ML Kit和Flutter》详细阐述了与移动设备深度学习开发相关的基本解决方案,主要包括使用设备内置模型执行人脸检测、开发智能聊天机器人、识别植物物种、生成实时字幕、构建人工智能认证系统、使用AI生成音乐、基于强化神经网络的国际象棋引擎、构建超分辨率图像应用程序等内容。此外,本书还提供了相应的示例、代码,以帮助读者进一步理解相关方案的实现过程。
本书适合作为高等院校计算机及相关专业的教材和教学参考书,也可作为相关开发人员的自学用书和参考手册。
《面向移动设备的深度学习—基于TensorFlow Lite,ML Kit和Flutter》 https://item.jd.com/14001258.html
https://item.jd.com/14001258.html

精彩回顾
微信搜索关注《Python学研大本营》,加入读者群,分享更多精彩
访问【IT今日热榜】,发现每日技术热点

















 315
315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









