







文章目录
transformer整体模型
transformer做了一件什么事情呢?

为什么要提出transformer,RNN有什么问题?
传统的RNN
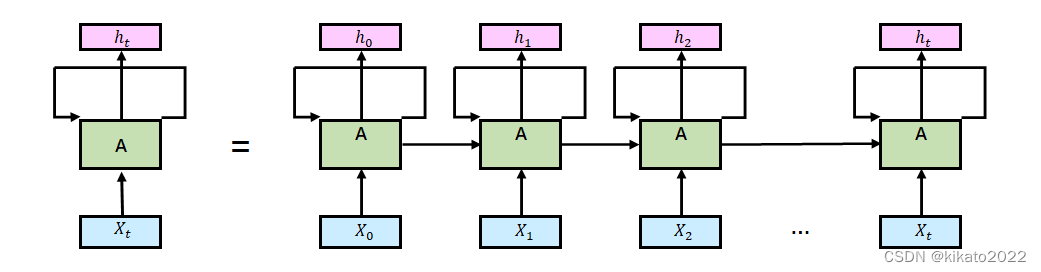
每一个
X
i
X_i
Xi的计算都需要依赖之前的计算所得到的中间结果。
transformer
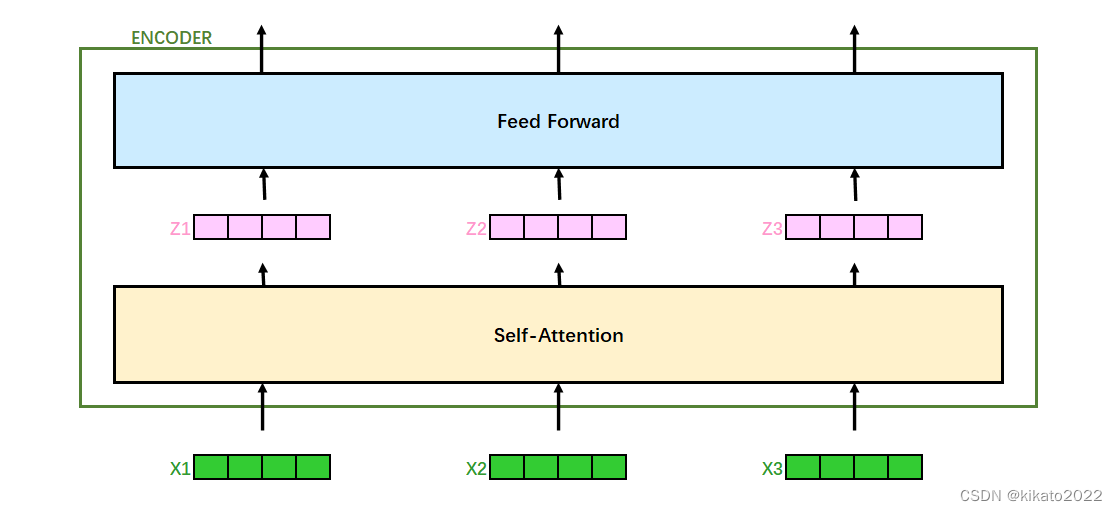
使用Self-Attention机制来并行计算,输出结果是同时被计算出来的。
Self-Attention
传统的word2vec
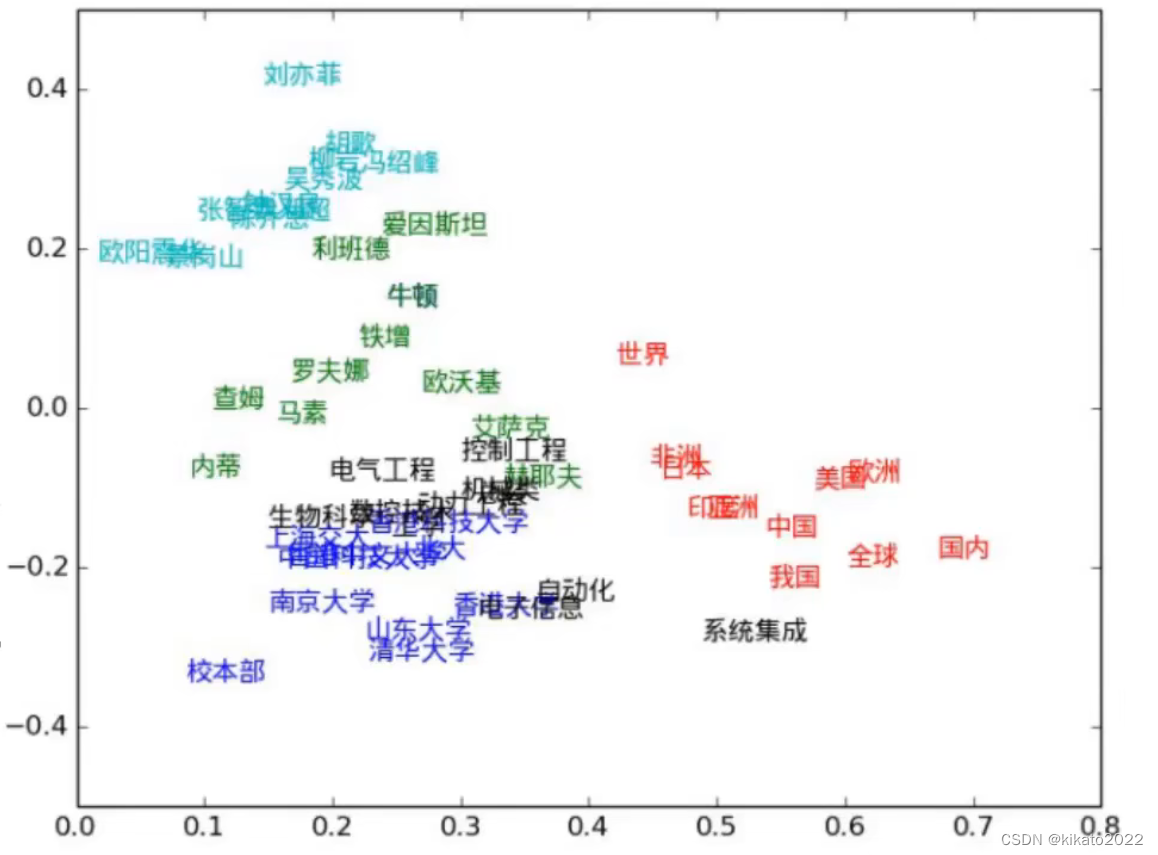
需要先训练好词向量,再将语料库转换成词向量,输入到RNN的模型基本不变。但实际情况中,同样的词在不同的语境中含义有可能不同,而且这在自然语言处理当中非常常见。
transformer是通过self-attention来做到这一件事情的
self-attention
对于输入的数据,如何才能让计算机关注到想要关注的有价值的信息.
也就是说,计算机如何通过上下文,有侧重地选出最重要的信息。

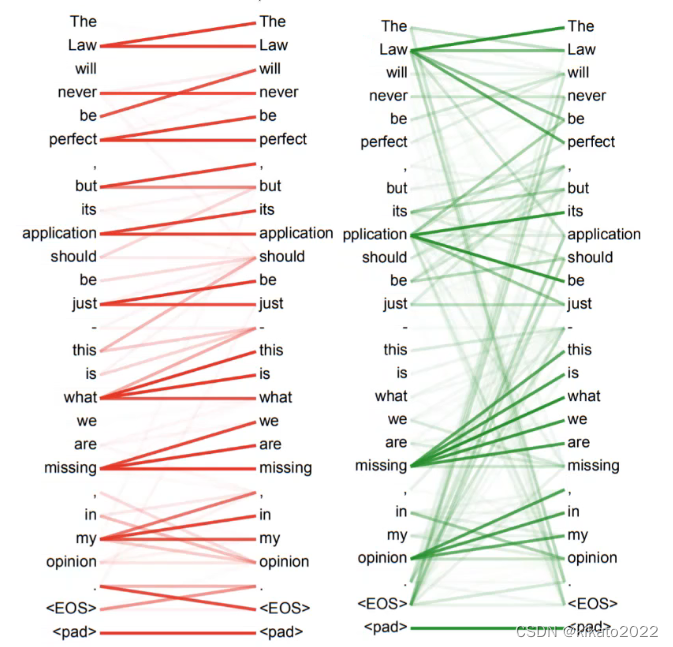
同样的it,第一句话指代animal,第二句话指代street。
对于animal,用上下文融合信息,每个单词都往animal里加信息,只是每个词往animal加入的信息多少不一样。
最后达到的效果,用热度图来表示就是:

这就是self-attention要做的事情。也就是说当对词进行编码的时候,不仅仅要考虑当前的词,还要考虑当前词所处的上下文语境,将上下文语境融入要编码的词向量中。
self-attention如何计算

构建三个矩阵来分别查询当前词跟其它词的关系,以及特征向量的表达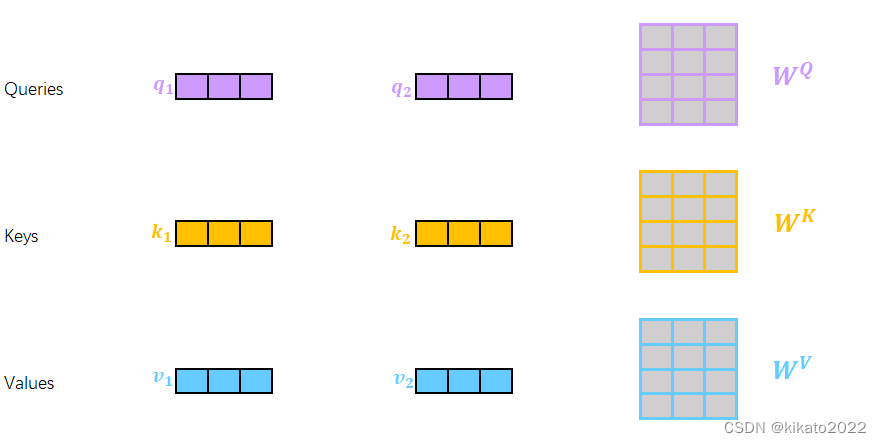
self-sttention如何计算?
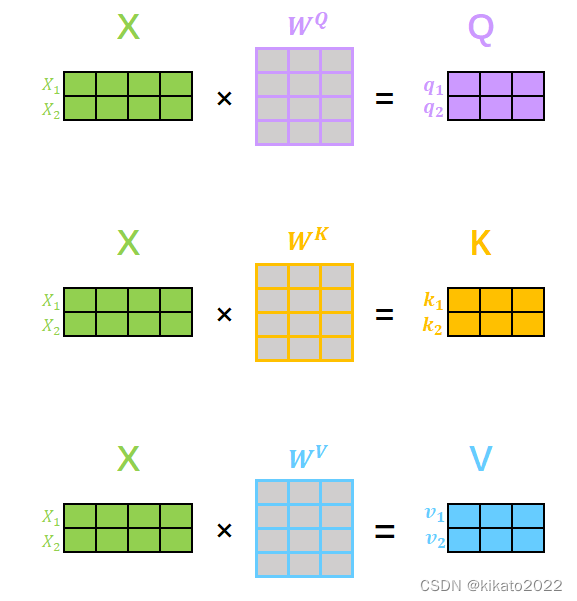
三个需要训练的矩阵:
Q: query,要去查询的
K: key,等着被查的
V: value,实际的特征
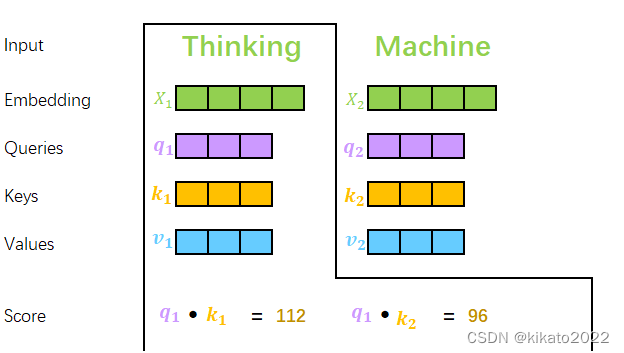
q与k的内积越大,表示它们越匹配。
最后的Score经过softmax,就是最终上下文结果
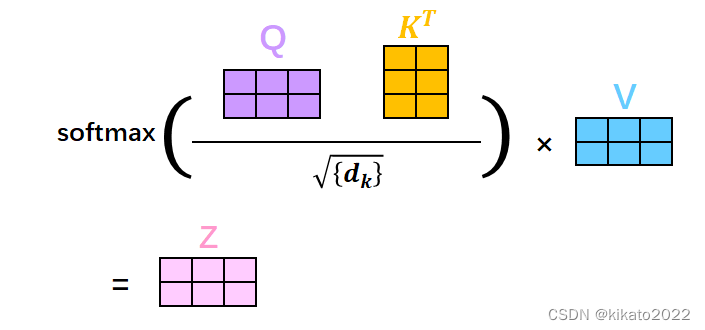
要除
d
k
\sqrt{d_k}
dk的原因是要刨除向量维度大小的影响
softmax的做法:

单独抽离出来看看每个词的Attention计算:每个词的Q会跟整个序列中的每一个K计算得分,然后基于得分再分配特征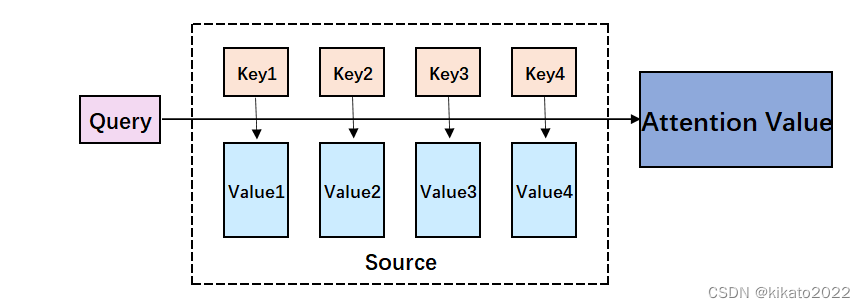
再来整体看一下self-attention的计算流程
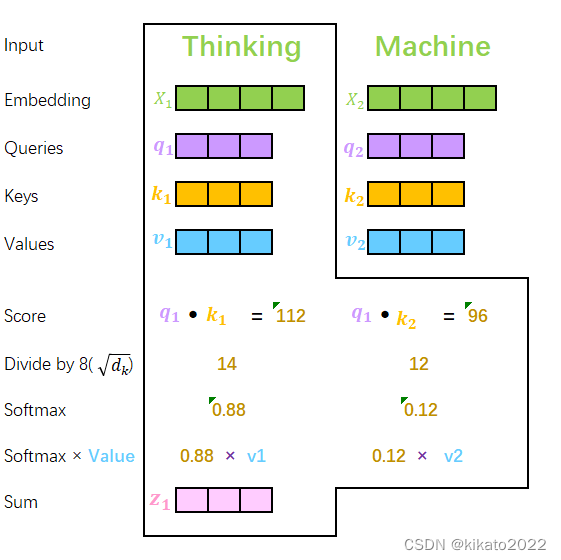
z
1
=
0.88
v
1
+
0.12
v
2
z_1=0.88v_1+0.12v_2
z1=0.88v1+0.12v2,
d
k
=
8
\sqrt{d_k}=8
dk=8是假设的维度
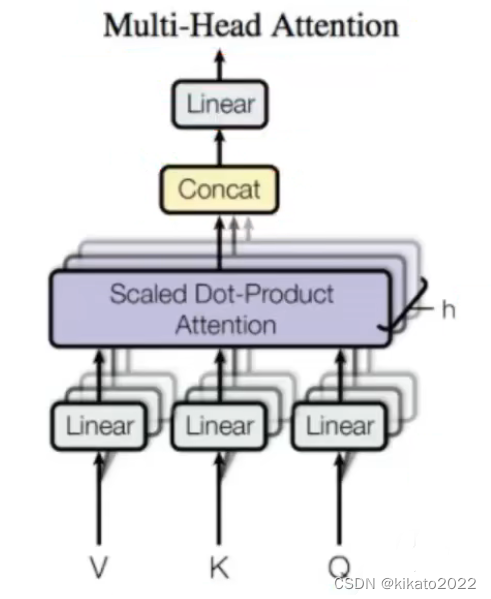
self-attention的multi-headed机制
通过不同的head得到多个特征表达,
将所有特征表达拼接在一起,
可以通过再一层全连接来降维全连接是神经网络里的概念(大概是通过乘一个全连接矩阵来降维)
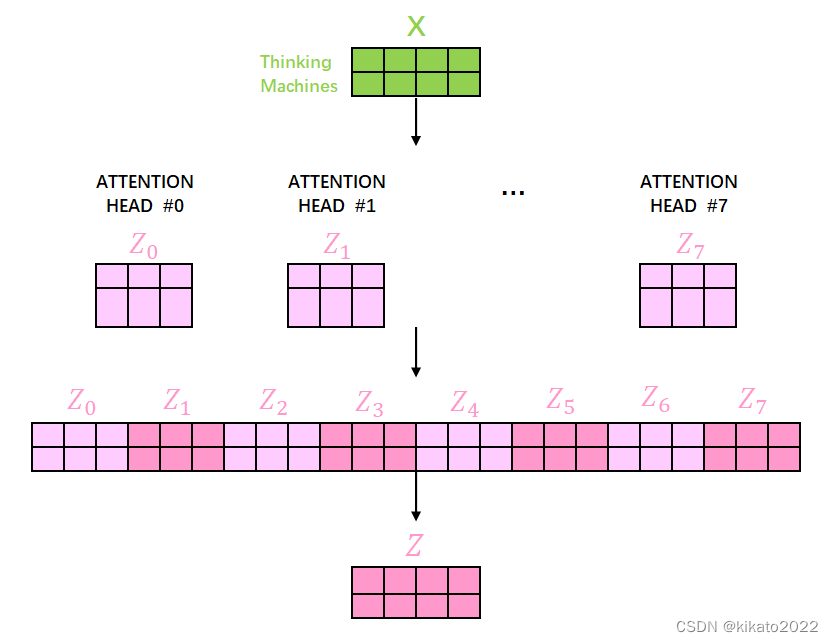
那么,transformer是如何得到多个ATTENTION HEAD的呢?
实际上是通过乘以不同组的
W
Q
,
W
K
,
W
V
W^Q, W^K, W^V
WQ,WK,WV矩阵来实现的。
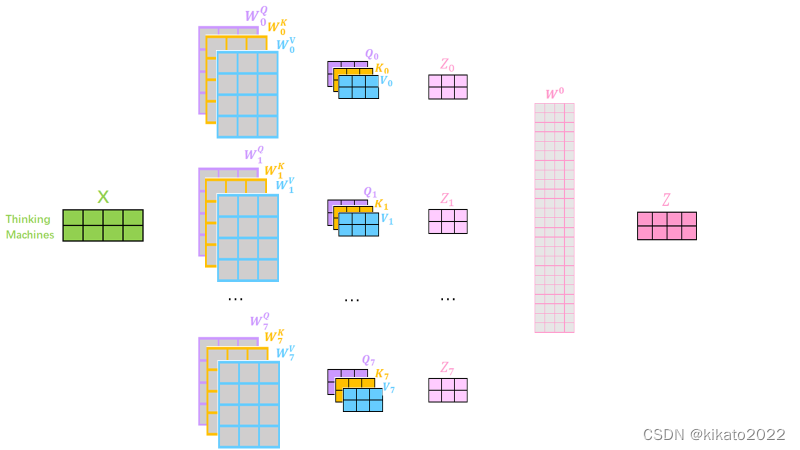
不同的multi-headed,结果不同,得到的特征向量也不同
再把不同的head经过Cancat、Linear处理,得到Self-Attetion的一个最终输出
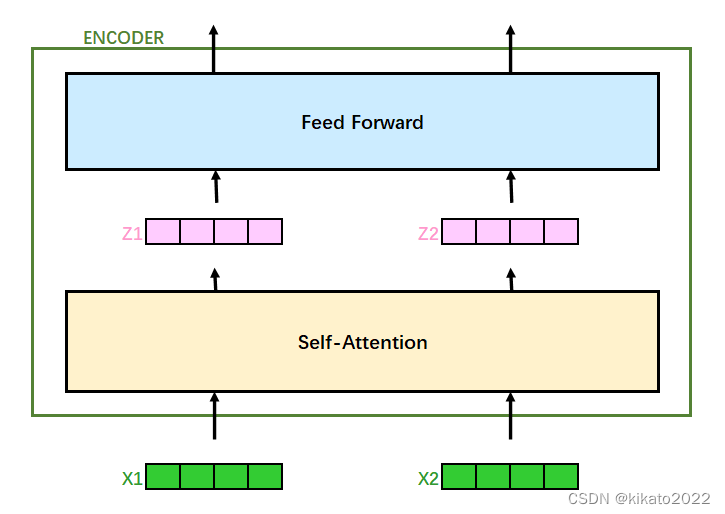
回顾之前的transformer整体结构
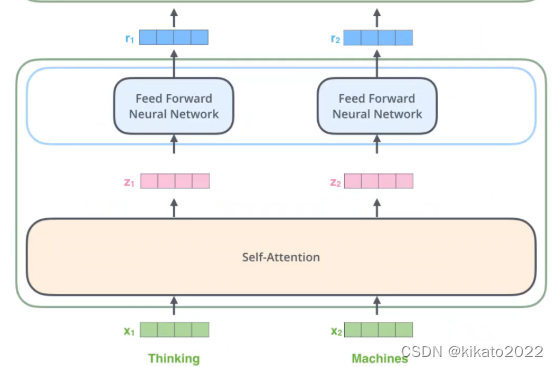
self-attetion得到结果过后,再进行Feed Forward处理,结果仍然是向量,输出结果在下图表示为
r
1
r_1
r1,
r
2
r_2
r2
Transformer多层堆叠
transformer的输入和输出都是向量,可以将多个transformer堆叠,每层计算方法都是相同的。
位置信息的表达
self-attention中每个词都会考虑整个序列的加权,所以其出现位置并不会对结果产生什么影响,相当于词放在序列中的任何位置都无所谓,这跟实际有些不符,所以我们希望模型能对位置有额外的认识。
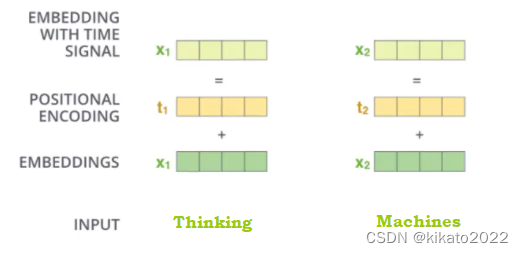
POSITIONNAL ENCODING(位置信息的编码)方法很多,常用的有正余弦函数。
Add & Normalize
(如下图中的Add&Normalize板块所示)
Normalize(归一化):
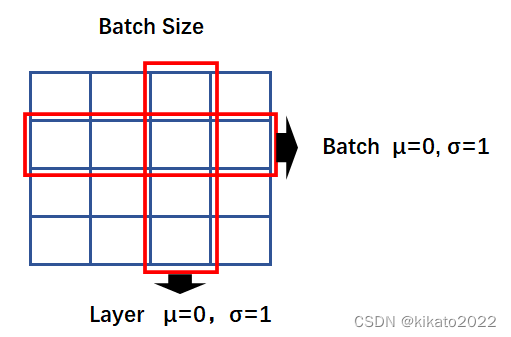
ADD:
ADD是将self-attention前的数据与self-attention之后的数据相加,
需要将self-attetion前的的数据连接到Add&Normalize层,
采用基本的残差连接的方式
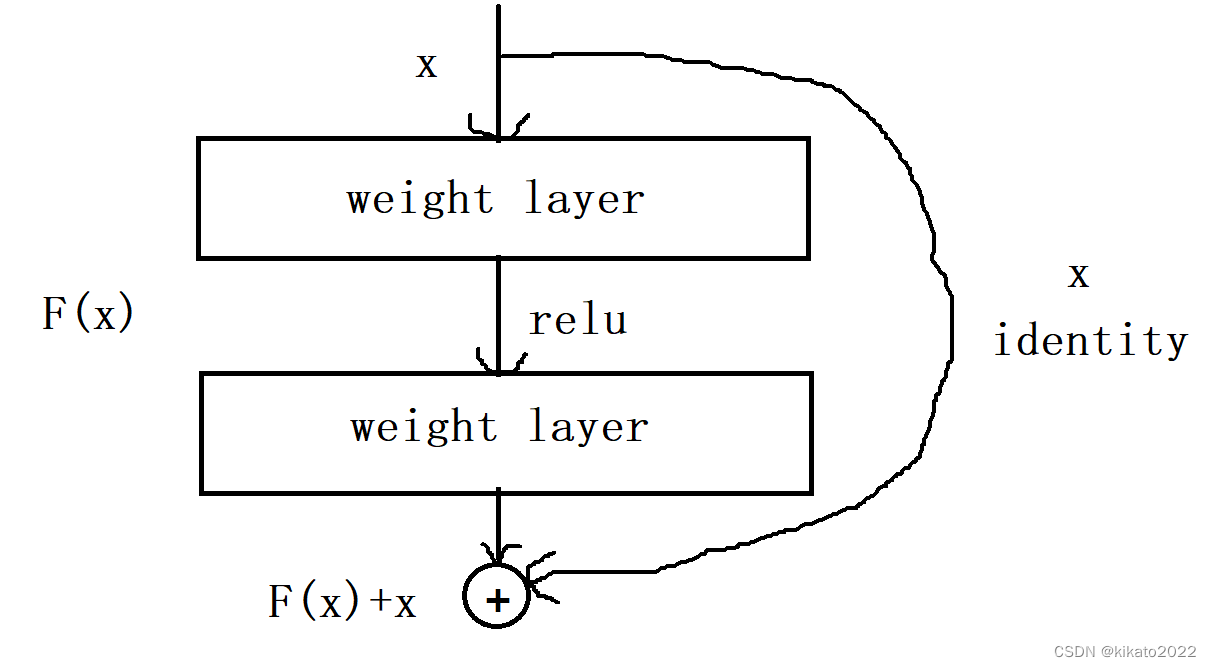
transformer中的连接见下图的虚线
做这一步的目的是因为不敢保证经过处理后的特征一定比原始的特征好。这样处理就能保证至少不比原来差。
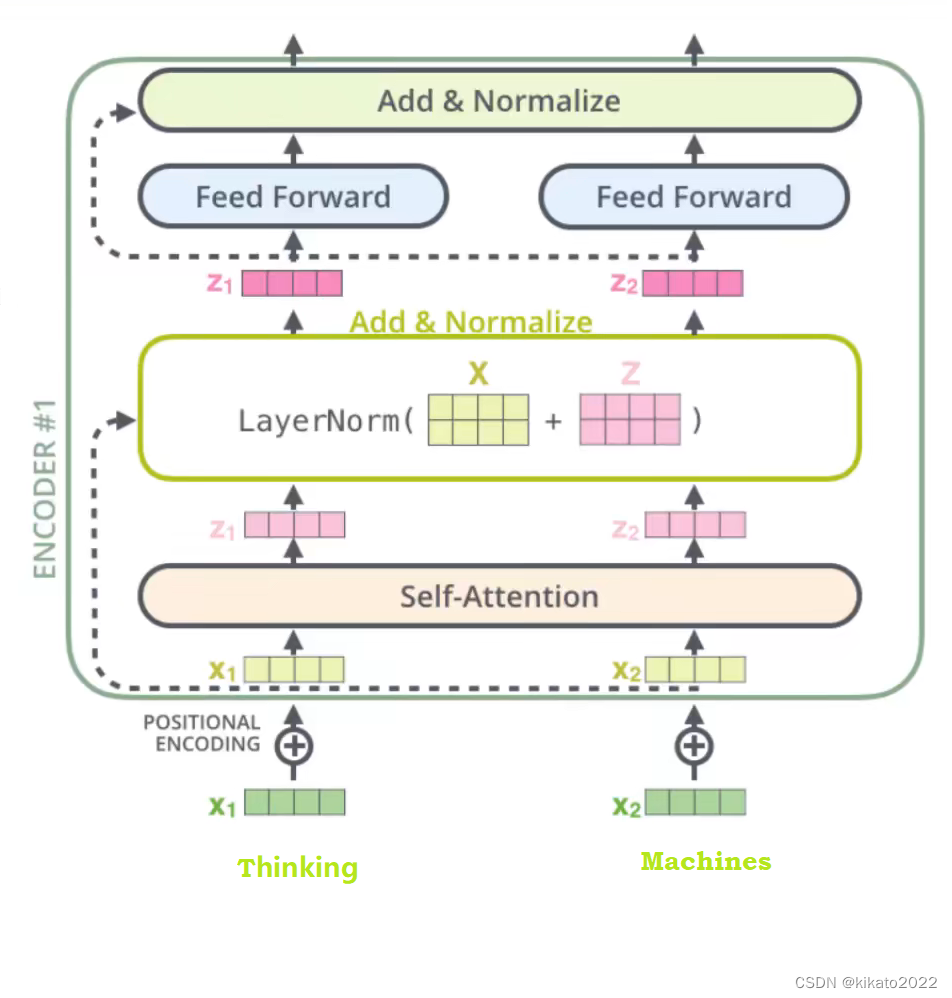
添加位置信息、Add&Normalize之后的图示:















 1932
1932











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









