






高斯混合模型
给定变量 x x x 的有限个观测数据 x 1 , x 2 , x 3 , ⋯ , x n x_1,x_2,x_3,\cdots,x_n x1,x2,x3,⋯,xn,对变量 x x x 的概率分布 p ( x ) p(x) p(x) 进行建模的过程称为对变量 x x x 的密度估计,高斯混合模型(Gaussian Mixture Model,GMM)是一种得到了广泛使用且非常有效的密度估计方法,高斯混合模型是用来表示在总分布中含有 K K K 个高斯分布的概率模型,各个高斯分布称为总分布的子分布。混合高斯模型在计算观测数据在总体分布中的概率时,不需要观测数据提供关于子分布的信息。
高斯分布,也称正态分布,是自然界中广泛存在的一种数据分布形式,其概率密度函数公式如 \href \href{#label}{公式1.1} \href 所示
N
(
x
∣
μ
,
σ
2
)
=
1
2
σ
2
π
e
−
(
x
−
μ
)
2
2
σ
2
(1.1)
N\left(x \mid \mu, \sigma^{2}\right)=\frac{1}{\sqrt{2 \sigma^{2} \pi}} e^{-\frac{(x-\mu)^{2}}{2 \sigma^{2}}} \tag{1.1}
N(x∣μ,σ2)=2σ2π1e−2σ2(x−μ)2(1.1)
其中,参数
u
u
u 表示变量
x
x
x 的期望,参数
σ
\sigma
σ 表示变量
x
x
x 的标准差,更一般的情况下,当变量是多维数据时,即
x
\boldsymbol{x}
x 的维度
d
>
1
d>1
d>1 时,多元高斯分布的概率密度函数如
\href
\href{#公式1.2}{公式1.2}
\href 所示:
N
(
x
;
μ
,
Σ
)
=
1
(
2
π
)
d
det
(
Σ
)
exp
[
−
1
2
(
x
−
μ
)
Σ
−
1
(
x
−
μ
)
T
]
(1.2)
N(\boldsymbol{x}; \boldsymbol{\mu}, \Sigma)=\frac{1}{\sqrt{(2 \pi)^{d} \operatorname{det}(\Sigma)}} \exp \left[-\frac{1}{2}(\boldsymbol{x}-\mu) \Sigma^{-1}(\boldsymbol{x}-\mu)^{T}\right] \tag{1.2}
N(x;μ,Σ)=(2π)ddet(Σ)1exp[−21(x−μ)Σ−1(x−μ)T](1.2)
其中,
μ
\boldsymbol{\mu}
μ 是一个
d
d
d 维向量,代表了
x
\boldsymbol{x}
x 各个维度的的数学期望,
Σ
\Sigma
Σ 是一个
d
×
d
d\times d
d×d 的矩阵,表示了变量
x
\boldsymbol{x}
x 各个维度之间的协方差矩阵。高斯混合模型可以看作
K
K
K 个高斯分布的组合,其概率分布形式如
\href
\href{#公式1.3}{公式1.3}
\href 所示:
P
(
x
∣
θ
)
=
∑
k
=
1
K
α
k
ϕ
(
x
∣
θ
k
)
(1.3)
P(\boldsymbol{x}\mid \theta)=\sum_{k=1}^{K} \alpha_{k} \phi\left(\boldsymbol{x}\mid \theta_{k}\right)\tag{1.3}
P(x∣θ)=k=1∑Kαkϕ(x∣θk)(1.3)
其中,
α
k
⩾
0
\alpha_{k} \geqslant 0
αk⩾0 ,
∑
k
=
1
K
α
k
=
1
\sum\limits_{k=1}^{K} \alpha_{k}=1
k=1∑Kαk=1 ,
θ
=
(
α
1
,
α
2
,
…
,
α
K
,
θ
1
,
θ
2
,
…
,
θ
K
)
\boldsymbol{\theta}=(\alpha_1,\alpha_2,\dots,\alpha_K,\theta_1,\theta_2,\dots,\theta_K)
θ=(α1,α2,…,αK,θ1,θ2,…,θK) 表示GMM模型的参数,
θ
k
\boldsymbol{\theta}_k
θk 表示GMM第
k
k
k 个高斯分布的参数,当
x
\boldsymbol{x}
x 维度为1时,
θ
k
=
(
μ
k
,
σ
k
2
)
\boldsymbol{\theta}_k=(\mu_k,\sigma_k^2)
θk=(μk,σk2) ,
ϕ
(
x
∣
θ
k
)
\phi\left(\boldsymbol{x}\mid \boldsymbol{\theta}_{k}\right)
ϕ(x∣θk) 由公式
\href
\href{#1.1}{公式1.1}
\href 给出;当
x
\boldsymbol{x}
x 维度大于1时,
θ
k
=
(
μ
k
,
Σ
k
)
\boldsymbol{\theta}_k=(\boldsymbol{\mu_k},\Sigma_k)
θk=(μk,Σk) ,
ϕ
(
x
∣
θ
k
)
\phi\left(\boldsymbol{x}\mid \boldsymbol{\theta}_{k}\right)
ϕ(x∣θk) 由公式
\href
\href{#1.2}{公式1.2}
\href 给出。对于GMM模型的观测数据
x
i
,
i
=
1
,
2
,
3
…
,
n
\boldsymbol{x}_i \;,i=1,2,3\dots,n
xi,i=1,2,3…,n ,可以认为是经过两个采样步骤生成的:第一步,按照概率
α
k
\alpha_k
αk 选择第
k
k
k 个高斯分布
ϕ
(
x
∣
θ
k
)
\phi(\boldsymbol{x}|\boldsymbol{\theta}_k)
ϕ(x∣θk) ,第二步,按照第
k
k
k 个高斯分布
ϕ
(
x
∣
θ
k
)
\phi(\boldsymbol{x}|\boldsymbol{\theta}_k)
ϕ(x∣θk) 采样生成观测数据
x
i
\boldsymbol{x}_i
xi ,这里需要重点理解的是,我们并不知道观测数据
x
i
\boldsymbol{x}_i
xi 来自于哪个高斯分布,记
ω
i
,
k
∈
[
1
,
2
,
3
…
,
K
]
\omega_{i,k}\in [1,2,3\dots,K]
ωi,k∈[1,2,3…,K] 表示第
i
i
i 个观测数据
x
i
\boldsymbol{x}_i
xi 来自第
k
k
k 个高斯分布的概率,
ω
i
,
k
\omega_{i,k}
ωi,k 是未知的,一般将其称为隐变量。下面将介绍利用期望极大算法估计GMM模型参数的思路。
期望极大(Expectation Maximum,EM)算法是1977年由Dempster等人1 总结提出的,EM算法是含有隐变量的概率模型参数的极大似然估计法。关于EM算法本身正确性及收敛性的证明可以参考文献2 ,本文只介绍利用EM算法估计GMM模型参数的简要思路:
步骤 1:赋予GMM模型参数初值 θ 0 \boldsymbol{\theta}^0 θ0 ,初值的选择是任意的,但需要注意的是,EM算法只能收敛到局部最优解,所以EM算法对初值是敏感的。
步骤 2:利用当前GMM的模型参数为 θ t \boldsymbol{\theta}^t θt,求隐变量 ω i , k \omega_{i,k} ωi,k 的期望。
当 θ t \boldsymbol{\theta}^t θt 给定时,对于 \href \href{#公式1.3}{公式1.3} \href 而言, K K K 个高斯分布 ϕ ( x ∣ θ k ) \phi\left(\boldsymbol{x}\mid \boldsymbol{\theta}_{k}\right) ϕ(x∣θk) 都是确定的,因此可以求出观测数据 x i , i = 1 , 2 , 3 … , n \boldsymbol{x}_i \;,i=1,2,3\dots,n xi,i=1,2,3…,n 属于第 k k k 个高斯分布的概率,如 \href \href{#1.4}{公式1.4} \href 所示:
ω
i
,
k
t
=
α
k
t
ϕ
(
x
∣
θ
k
)
∑
k
=
1
K
α
k
t
ϕ
(
x
∣
θ
k
)
(1.4)
\omega_{i, k}^{t}=\frac{\alpha_{k}^{t} \phi\left(\boldsymbol{x}\mid \boldsymbol{\theta}_{k}\right)}{\sum\limits_{k=1}^{K}\alpha_{k}^{t} \phi\left(\boldsymbol{x}\mid \boldsymbol{\theta}_{k}\right)} \tag{1.4}
ωi,kt=k=1∑Kαktϕ(x∣θk)αktϕ(x∣θk)(1.4)
步骤 3:基于当前的隐变量
ω
i
,
k
\omega_{i,k}
ωi,k 的值,利用极大似然估计法更新GMM的模型参数为
θ
(
t
+
1
)
\boldsymbol{\theta}^{(t+1)}
θ(t+1) 。
当隐变量
ω
i
,
k
\omega_{i,k}
ωi,k 给定时,此时估计GMM模型参数就退化为一个不含隐变量的概率模型参数估计问题,可以利用极大似然估计法求得当前步骤模型参数的相合估计量,如下式所示:
当
d
=
1
时
,
{
α
k
t
+
1
=
∑
i
=
1
N
ω
i
,
k
t
N
μ
k
t
+
1
=
∑
i
=
1
N
ω
i
,
k
t
x
i
∑
i
=
1
N
ω
i
,
k
t
(
σ
k
2
)
t
+
1
=
∑
i
=
1
N
ω
i
,
k
(
x
i
−
μ
k
t
+
1
)
2
∑
i
=
1
N
ω
i
,
k
当
d
>
1
时
,
{
α
k
t
+
1
=
∑
i
=
1
N
ω
i
,
k
t
N
μ
k
t
+
1
=
∑
i
=
1
N
ω
i
,
k
t
x
i
∑
i
ω
i
,
k
t
Σ
k
t
+
1
=
∑
i
=
1
N
ω
i
,
k
t
(
x
i
−
μ
k
t
+
1
)
(
x
i
−
μ
k
t
+
1
)
T
∑
i
=
1
N
ω
i
,
k
t
\begin{aligned} & \text{当}\;d=1\;\text{时}, \begin{cases} \alpha_{k}^{t+1}=\frac{\sum\limits_{i=1}^N \omega_{i, k}^{t}}{N}\\\\ \mu_{k}^{t+1}=\frac{\sum\limits_{i=1}^N \omega_{i, k}^{t} x_{i}}{\sum\limits_{i=1}^N \omega_{i, k}^{t}}\\\\ \left(\sigma_{k}^{2}\right)^{t+1}=\frac{\sum\limits_{i=1}^N \omega_{i, k}\left(x_{i}-\mu_{k}^{t+1}\right)^{2}}{\sum\limits_{i=1}^N \omega_{i, k}} \end{cases} \\ & \text{当}\;d>1\;\text{时}, \begin{cases} \alpha_{k}^{t+1}=\frac{\sum\limits_{i=1}^N \omega_{i, k}^{t}}{N}\\\\ \boldsymbol{\mu}_{k}^{t+1}=\frac{\sum\limits_{i=1}^N \omega_{i, k}^{t} \boldsymbol{x}_{i}}{\sum_{i} \omega_{i, k}^{t}}\\\\ \Sigma_{k}^{t+1}=\frac{\sum\limits_{i=1}^N \omega_{i, k}^{t}\left(\boldsymbol{x}_{i}-\boldsymbol{\mu}_{k}^{t+1}\right)\left(\boldsymbol{x}_{i}-\boldsymbol{\mu}_{k}^{t+1}\right)^{T}}{\sum\limits_{i=1}^N \omega_{i, k}^{t}} \end{cases} \end{aligned}
当d=1时,⎩
⎨
⎧αkt+1=Ni=1∑Nωi,ktμkt+1=i=1∑Nωi,kti=1∑Nωi,ktxi(σk2)t+1=i=1∑Nωi,ki=1∑Nωi,k(xi−μkt+1)2当d>1时,⎩
⎨
⎧αkt+1=Ni=1∑Nωi,ktμkt+1=∑iωi,kti=1∑Nωi,ktxiΣkt+1=i=1∑Nωi,kti=1∑Nωi,kt(xi−μkt+1)(xi−μkt+1)T
为什么高斯模型混合模型(GMM)理论上可以拟合任意概率密度分布呢?
百科搬运工

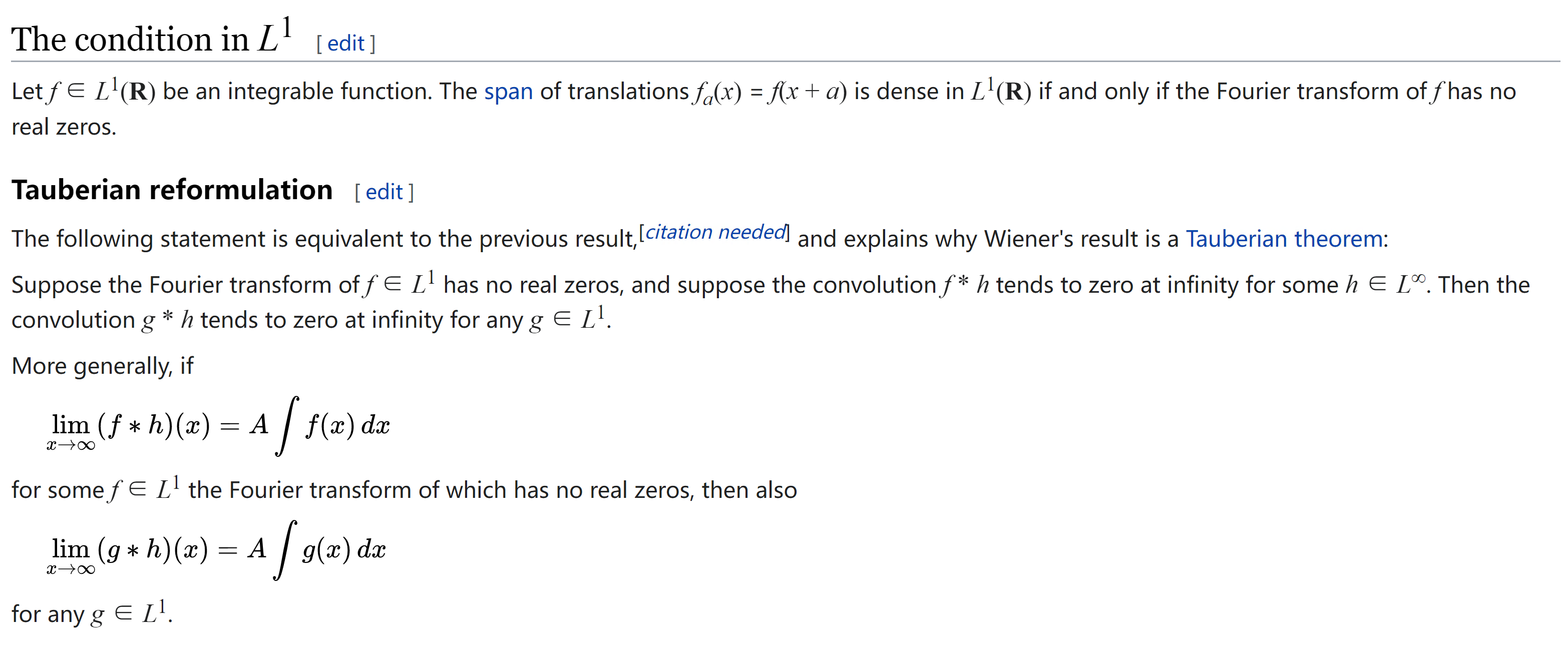


中文说明
定理实际上比GMM可以逼近任何概率分布条件要强,因为只用了平移。另外因为高斯函数的积还是高斯函数,似乎用Stone-Weierstrass定理也可以。选用高斯分布的理由其实有很多,一方面因为中心极限定理,生活中高斯分布非常多,另一方面,它实在是太好算了。其实第二个理由更充分,毕竟对任意的概率分布不可能总是高斯逼近是最好的。不过一般的GMM效果都不错。
你可能需要的参考文献
分别对应百科第一段中引用的两个参考文献:
[1] Meir, A., 1963. Tauberian theorems. Israel Journal of Mathematics 1, 29–36. https://doi.org/10.1007/BF02759798
[2] Rudin, W., 1991. Functional analysis, 2nd ed, International Series in Pure and Applied Mathematics. New York : McGraw-Hill.
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











