







文献: 在线链接 🧃 本地链接1 🍹 ICJAI 2021

引言
🍍 现有问题
现有研究多是针对静态HIN的节点嵌入或特定快照内的节点嵌入,少有研究能够兼顾整个网络在演进过程中的动态变化。
🍓 解决问题面临的挑战
-
如何有效地保持时序HIN结构和语义的动态性?
How to effectively preserve the structural and semantic dynamics in temporal HINs?
现有模型 (如DHNE [Yin et al., 2019]) 研究时序HIN时,通过简单地将时间划分为几个时间段,以获取网络快照,这将失去网络快照之间的动态关联。
-
如何捕获异质节点之间的相互影响?
How to capture the temporal influence between heterogeneous nodes?
现有模型 (如HDGAN [Li et al., 2020], DyHNE [Wang et al., 2020]) 研究时序HIN时,往往仅考虑同一类型节点之间的影响。
🌲 应对方法
1️⃣首先定义多种元路径来捕获HIN的语义和结构特征。2️⃣然后对于特定的下游任务,生成与该任务相关的候选元路径集。基于Hawkes过程建模节点之间的时序影响,利用两级注意力机制区分不同方面的权重(一是不同类型的元路径,二是邻居节点的距离),得到每个节点的嵌入向量。
预备知识
时序HIN
时序HIN: G = ( V , E , T , ϕ , φ ) \mathcal{G}=(\mathcal{V}, \mathcal{E}, \mathcal{T}, \phi, \varphi) G=(V,E,T,ϕ,φ) ,依次表示节点集、边集、时间戳集, ϕ : V → A , φ : E → R \phi: \mathcal{V} \rightarrow \mathcal{A}, \varphi:\mathcal{E} \rightarrow \mathcal{R} ϕ:V→A,φ:E→R , A , R \mathcal{A},\mathcal{R} A,R 分别表示节点和边的类型集;且满足 ∣ A ∣ + ∣ R ∣ > 2 |\mathcal{A}|+|\mathcal{R}|>2 ∣A∣+∣R∣>2
节点对的影响
节点对的影响表示两个节点对两者之间建立连边的贡献。计算如下:
η
x
,
y
=
−
∥
u
x
−
u
y
∥
2
\eta_{x, y}=-\left\|u_{x}-u_{y}\right\|^{2}
ηx,y=−∥ux−uy∥2
其中,
u
x
u_x
ux 和
u
y
u_y
uy 表示节点
v
x
v_x
vx 和节点
v
y
v_y
vy 的嵌入向量。
元路径
候选元路径集
时序边 e i j t ∈ E e_{i j}^{t} \in \mathcal{E} eijt∈E 的候选元路径集是,包含所有包含源节点 v i v_i vi 并且在时间 t t t 之前生成的路径实例的集合。
时序HIN嵌入——问题定义
给定时序HIN: G = ( V , E , T , ϕ , φ ) \mathcal{G}=(\mathcal{V}, \mathcal{E}, \mathcal{T}, \phi, \varphi) G=(V,E,T,ϕ,φ) ,学习映射关系 f : V → R d , where d ≪ ∣ V ∣ f: \mathcal{V} \rightarrow \mathbb{R}^{d}, \text { where } d \ll|\mathcal{V}| f:V→Rd, where d≪∣V∣ ,函数 f f f 不仅需要捕捉网络的时间动态性,还需要考虑不同类型节点之间的相互影响。
THINE Model
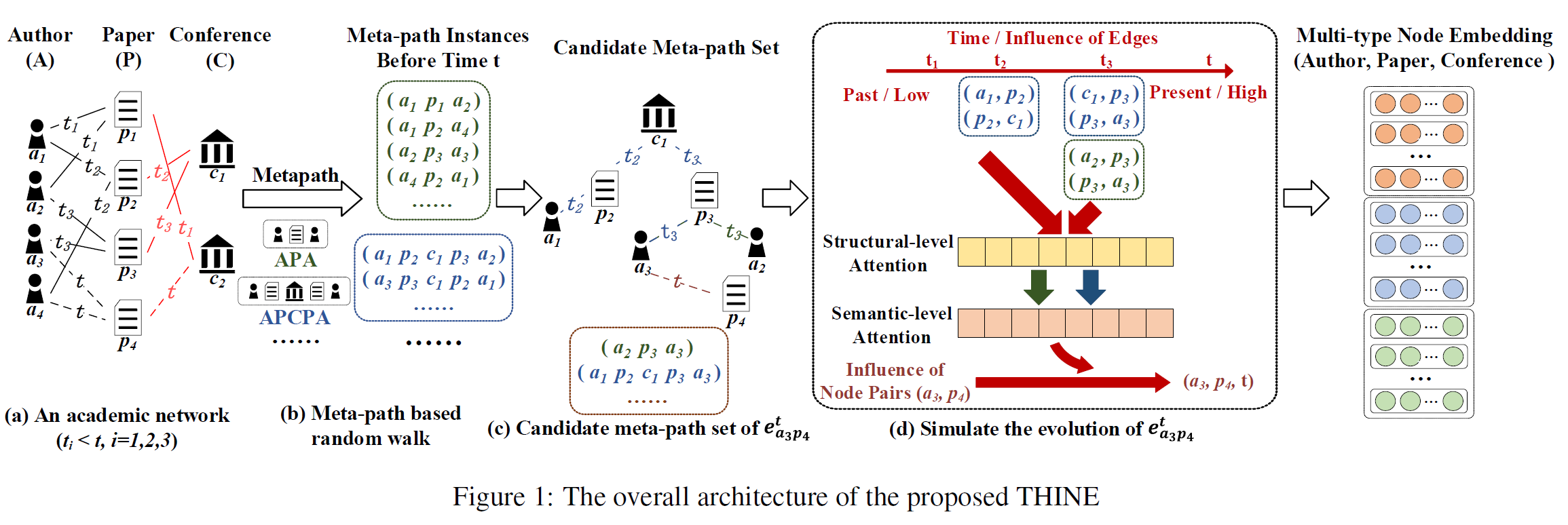
🌴 THINE总述
THINE可以捕捉HIN的结构和语义特征,同时考虑了时序动态性的影响。通过基于随机游走的元路径获取不同类型节点结构之间的交互。通过Hawkes过程获得每个边的候选元路径集来建模时序HIN的动态结构和语义特征。在此基础上,利用结构级和语义级的注意力机制进行优化,以区分不同类型关系的影响,并对每个节点的影响进行聚合,获得多类型节点的嵌入。
利用元路径捕获语义
网络中的节点和边受节点本身和相关的候选元路径集的影响,因此,基于节点对的影响,我们对候选集的影响进行建模,以理解时序HIN。
候选元路径集的动态建模
我们利用霍克斯过程,模拟候选元路径集的影响,以捕获时序HIN的语义和结构特征。
通常,Hawkes过程用来模拟过去事件对现在的影响,时间差越大,对当下的影响就越小。
结合注意力机制的优化
语义级注意力机制
由于不同类型的元路径对特定任务的影响不同,为了捕捉这种微妙的区别,应用了一种语义级的注意力机制。形式上,定义不同类型元路径的权重如下:
ω
b
=
e
ω
b
∑
c
e
ω
c
\omega_{b}=\frac{e^{\omega_{b}}}{\sum_{c} e^{\omega_{c}}}
ωb=∑ceωceωb
其中,
c
c
c 是所有元路径的集合,
ω
b
\omega_{b}
ωb 表示第
b
b
b 个元路径的权重,考虑不同元路径的语义,将候选元路径集的影响进一步表示为:
η
s
(
t
)
=
∑
t
m
<
t
ω
M
×
η
m
(
t
)
\eta_{s}(t)=\sum_{t_{m}<t} \omega_{\mathcal{M}} \times \eta_{m}(t)
ηs(t)=tm<t∑ωM×ηm(t)
其中,
ω
M
\omega_{\mathcal{M}}
ωM 是元路径
M
\mathcal{M}
M 的权重,
m
m
m 是元路径
M
\mathcal{M}
M 的实例。
结构级注意力机制
显然,由于到训练边的跳数不同,每个边对训练边的影响应该是不同的,因此,使用结构级的注意力机制,以捕捉这种差异,与跳数相关的权重为:
θ
h
o
q
=
e
θ
h
o
q
∑
z
′
e
θ
h
\theta_{h_{o q}}=\frac{e^{\theta_{h_{o q}}}}{\sum_{z^{\prime}} e^{\theta_{h}}}
θhoq=∑z′eθheθhoq
其中,
h
o
q
h_{oq}
hoq 表示边
e
o
q
e_{oq}
eoq 到源节点的跳数,
z
′
z^{\prime}
z′ 是候选边
z
z
z 的数量2,因此,将一个元路径实例的影响重新定义为:
η
m
(
t
)
=
∑
e
i
j
∈
m
θ
h
i
j
×
η
e
i
j
(
t
)
\eta_{m}(t)=\sum_{e_{i j} \in m} \theta_{h_{i j}} \times \eta_{e_{i j}}(t)
ηm(t)=eij∈m∑θhij×ηeij(t)
时序边产生的强度
基于元路径、两级注意力机制、Hawkes过程中,我们模拟了每个时序边的演化过程。通过这种方法,无论是静态网络还是动态网络,都可以得到保留语义和结构特征的多类型节点嵌入。基于以上公式,定义
条
件
强
度
函
数
\href{#CIF}{条件强度函数}
条件强度函数
λ
~
x
,
y
(
t
)
\tilde{\lambda}_{x, y}(t)
λ~x,y(t) 表示节点
v
x
v_x
vx 和
v
y
v_y
vy 在时刻
t
t
t 产生时序边的强度:
λ
~
x
,
y
(
t
)
=
η
x
,
y
+
η
s
(
t
)
=
η
x
,
y
+
∑
t
m
<
t
(
ω
M
×
∑
e
i
j
∈
m
θ
h
i
j
×
η
e
i
j
(
t
)
)
\begin{aligned} \tilde{\lambda}_{x, y}(t) &=\eta_{x, y}+\eta_{s}(t) \\ &=\eta_{x, y}+\sum_{t_{m}<t}\left(\omega_{\mathcal{M}} \times \sum_{e_{i j} \in m} \theta_{h_{i j}} \times \eta_{e_{i j}}(t)\right) \end{aligned}
λ~x,y(t)=ηx,y+ηs(t)=ηx,y+tm<t∑⎝⎛ωM×eij∈m∑θhij×ηeij(t)⎠⎞
考虑到条件强度函数值始终为正实数,使用指数函数对
λ
~
x
,
y
(
t
)
\tilde{\lambda}_{x, y}(t)
λ~x,y(t) 进行变换,上式可以被重新定义为
λ
x
,
y
(
t
)
=
e
x
p
(
λ
~
x
,
y
(
t
)
)
\lambda_{x, y}(t)=exp(\tilde{\lambda}_{x, y}(t))
λx,y(t)=exp(λ~x,y(t)) ,并且,
λ
x
,
y
(
t
)
\lambda_{x, y}(t)
λx,y(t) 被限制在
0
0
0 和
1
1
1 同时表示节点
v
x
v_x
vx 和
v
y
v_y
vy 之间建立连边的概率。
损失函数
节点
v
x
v_x
vx 和
v
y
v_y
vy 在时刻
t
t
t 建立连接的概率为:
p
(
v
x
,
v
y
∣
S
(
t
)
)
=
λ
x
,
y
(
t
)
∑
y
′
λ
x
,
y
′
(
t
)
p\left(v_{x}, v_{y} \mid S(t)\right)=\frac{\lambda_{x, y}(t)}{\sum_{y^{\prime}} \lambda_{x, y^{\prime}}(t)}
p(vx,vy∣S(t))=∑y′λx,y′(t)λx,y(t)
其中,
y
′
y^{\prime}
y′ 表示时序HIN中除
v
x
v_x
vx 外的所有节点。所有节点对的对数似然可以表示为:
log
L
=
∑
(
v
x
,
v
y
)
∈
E
log
p
(
v
x
,
v
y
∣
S
(
t
)
)
\log L=\sum_{\left(v_{x}, v_{y}\right) \in \mathcal{E}} \log p\left(v_{x}, v_{y} \mid S(t)\right)
logL=(vx,vy)∈E∑logp(vx,vy∣S(t))
采用负采样技术计算
p
(
v
x
,
v
y
∣
S
(
t
)
)
p\left(v_{x}, v_{y} \mid S(t)\right)
p(vx,vy∣S(t)) ,以减少模型计算开销。最终的损失函数可被重新定义为:
−
log
σ
(
λ
~
x
,
y
(
t
)
)
−
∑
k
=
1
K
E
v
k
∼
P
n
(
v
)
[
log
σ
(
−
λ
~
x
,
k
(
t
)
)
]
-\log \sigma\left(\widetilde{\lambda}_{x, y}(t)\right)-\sum_{k=1}^{K} E_{v^{k} \sim P_{n}(v)}\left[\log \sigma\left(-\widetilde{\lambda}_{x, k}(t)\right)\right]
−logσ(λ
x,y(t))−k=1∑KEvk∼Pn(v)[logσ(−λ
x,k(t))]
其中,
K
K
K 是根据
P
n
(
v
)
P_n(v)
Pn(v) 抽样的负节点数量,
P
n
(
v
)
P_n(v)
Pn(v) 与
d
v
3
/
4
d_v^{3/4}
dv3/4 正相关,
d
v
d_v
dv 为节点
v
v
v 的度。
δ
\delta
δ 是
s
i
g
m
o
i
d
sigmoid
sigmoid 函数,
σ
(
x
)
=
1
1
+
e
−
x
\sigma(x)=\frac{1}{1+e^{-x}}
σ(x)=1+e−x1 ;模型采用Adam算法进行优化。
实验结果
实验设置、实验数据、对比方法
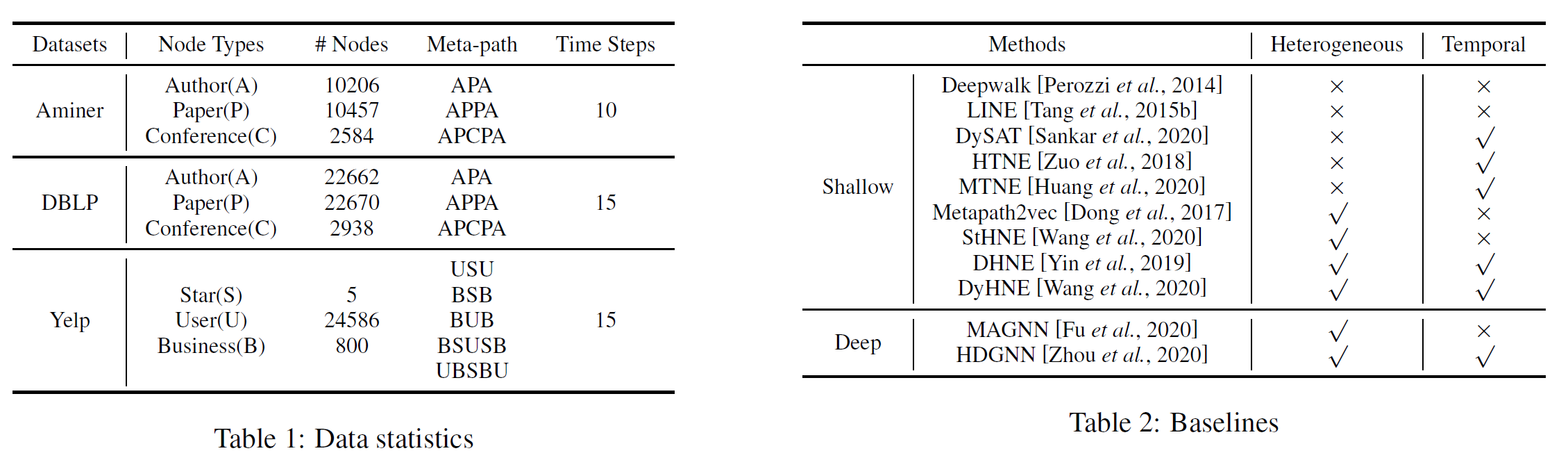
Adam 学习率 0.003 0.003 0.003 ,批处理大小 500 500 500,每节点随机游走 10 10 10 次,游走长度 30 30 30,候选元路径实例数 20 20 20。 The number z z z of candidate edges is 4 4 4, and the negative samples is set to be 5 5 5. 其他基线方法,使用默认参数。每项实验取十次结果的平均值作为最终结果。
静态任务
🍸 节点分类
🍓 链接预测
动态任务
🍐 时序链接推荐
参数分析
候选元路径实例的数量、候选边的数量、负样本的数量:

总结
论文提出了用THINE来研究时序HIN嵌入问题。利用候选元路径集捕获结构和语义特征,同时利用Hawkes过程建模网络的演化。在三个真实时序HIN上的实验表明,在静态和动态任务中,THINE有最佳的性能。
附录
条件强度函数

D:\论文\2021\Conference Paper\2021-Temporal heterogeneous information network embedding-Proceedings of the thirtieth international joint conference on artificial intelligence, IJCAI 2021, virtual event montreal, canada, 19-27 august 2021.pdf ↩︎
这里原文表述为: z ′ z^{\prime} z′ is positively related to the number of candidate edges z z z ↩︎
















 1418
1418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











