






本篇为“揭秘AI智算中心网络流量“系列的第三篇,前篇请参阅:
01、生成式AI对数据存储有哪些需求?
对于较小规模的AI模型,本地连接的磁盘存储可能就足够;进入大模型时代,则通常需要基于对象存储或并行文件系统的共享存储。一个完整的生成式AI的工作流的各阶段对存储有不同需求,具体可拆解如下:
- 数据挖掘:需要从多个来源收集非结构化的数据,一般与混合云集成,用数据湖作为存储平台;
- 数据准备:进行数据汇总、标准化和版本控制,关注存储的效率和灵活的数据管理能力,多采用统一存储平台;
- 模型训练和微调:在智算中心内部,结合GPU服务器本地内存和远端的并行/分布式存储系统。因为GPU的投入巨大,需要高性能存储来高效地提供数据,并在整个过程中保持高利用率;
- 推理阶段:该阶段旨在利用已训练好的模型实时生成输出,需要将输入模型和推理生成的文字/图片/视频流存储下来作为备份。
02、智算中心的存储网络
我们大致可将AI智算中心内部的数据存储系统进行简单的层次分类,主要包括GPU内存、存储网和存储设备。
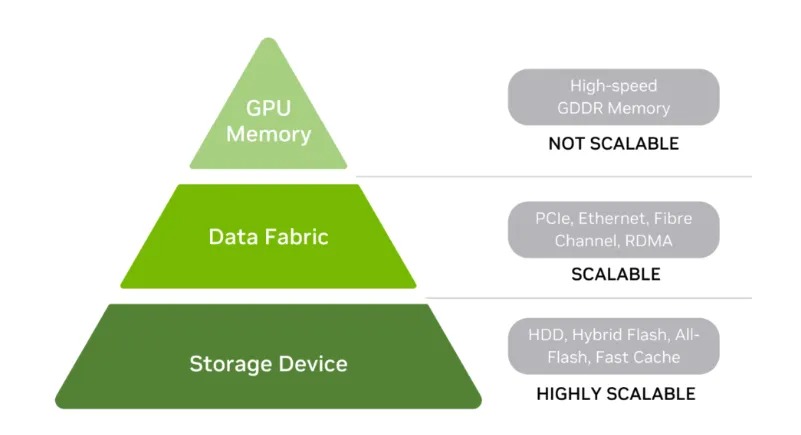
| 图片引自 NVIDIA技术博客
一般来说,在存储层次结构中位置越高,其存储性能(尤其是延迟)就越快。因为本文的定位在分析网络流量,我们将聚焦于存储网络(data fabric)层次,即智算中心内部GPU服务器内存与远端存储服务器之间传输的数据。
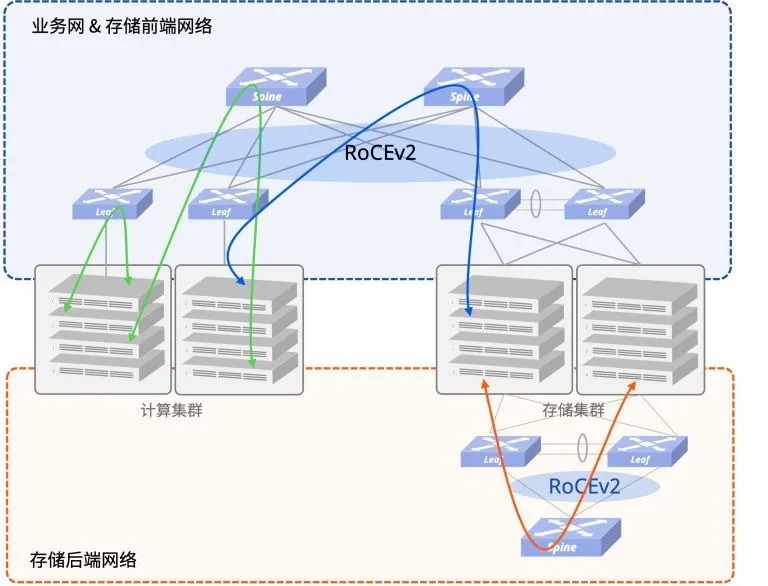
在一个计算和存储分离的部署场景中,一般推荐部署2张Spine-Leaf架构的物理网:前端网和后端网。其中,存储前端网和业务网共用一张物理网。
存储后端网则单独使用一张物理网,以保证分布式存储集群能够快速无阻塞地完成多副本同步、故障后数据重建等任务。存储节点对网络接入侧的可靠性要求相对较高,因此推荐使用双归(MC-LAG)或者多归(EVPN-Multihoming)接入。
存储网络流量主要发生在模型训练的场景,它是一种单播流量,逻辑上仅需要以存储服务器为中心的星型连接。
- 一是从存储服务器中分批加载训练数据集到GPU内存。
- 二是训练的中间结果(定期保存的参数和优化器状态,即Check Point)要在存储服务器共享,并通过网络读写。
⑴ 数据集加载流量分析
在一个epoch中,整个训练集被遍历一次,如果进行评估,验证集也将被遍历一次。以下假设在每个epoch中进行评估,整个数据集的存储大小为D。
- 数据并行时,整个数据集从网络存储读取,通过scatter操作分别加载到不同的GPU上,总网络流量为D。
- 张量并行时,整个数据集从网络存储读取,通过broadcast操作发送给所有GPU,总的网络流量为 D x G。
- 流水线并行时,整个数据集从网络存储读取,喂给流水线上第一个GPU,总网络流量为D。
- 3D并行时,整个数据集从网络存储读取,在数据并行维度上分配,在张量并行维度上广播,总网络流量为D x G(tp) 。
以C4数据集为例,数据集的大小约38.5 TB,假设张量并行GPU数量为8,3D并行时每个epoch中加载数据集产生的网络流量为308TB。
⑵ Checkpoint存储流量分析
Checkpoint中存储了模型参数、优化器状态和其它训练状态(包括模型配置、训练的超参数、日志信息等)。优化器包含了梯度、动量和二阶矩估计等,每一种数据大小都等于模型参数。其它训练状态的大小可以忽略不计。假设模型参数为P,数据格式为BFLOAT16,优化器为Adam/AdamW,则checkpoint总大小为:
2 x P + 2 x P x 3 = 8 x P
这个checkpoint要保存在存储服务器中,虽然在张量并行、流水线并行和3D并行时,这些数据从多个GPU上通过gather操作汇聚到存储服务器,但无论如何,数据总量是一个checkpoint大小。假设每个epoch存储一次。这样,每个epoch产生的流量为:
8 x P
以Llama3-70B模型为例,假设每个epoch均存储,则产生的网络存储流量为560GB。
03、存储网设备选型:RoCE还是InfiniBand
相比训练场景,在智算中心存储网传输的流量与并行计算完全不在一个量级——虽然对链路带宽要求不那么高,但仍需满足高速分布式存储业务中所需的高吞吐、低时延、无损传输特性,并灵活满足存储集群规模调整所需的高可扩展性。
NVIDIA DGX SuperPOD™ 的方案在存储网采用的是200G的InfiniBand交换机。而事实上,随着近年来AI以太网技术的进步,RoCE与IB在转发时延上的细微差异,对分布式存储业务性能几乎没有影响。结合科学的网络参数调优,我们已在多个客户现场稳定测得了运行RoCEv2协议的交换机端到端性能全面优于IB交换机的结果。RoCE交换机作为IB平替已是不争的事实。
星融元 CX664P-N 是一款专为智算/超算中心设计的超低时延RoCE交换机,凭借以下特性在存储场景中脱颖而出。
- CX-N系列一贯的超低延迟特性,端到端性能可媲美IB*(*测试数据详见方案手册)
- 12.8Tbps 的线速 L2/L3 交换性能,提供高密度 200G/100G 以太网接口,满足主流存储网络需求并兼顾未来升级空间;另有两个 10G 端口用于管理网接入
- 支持基于 RDMA 的 NVMe-oF (全端口标配RoCEv2)和EVPN-Multihoming → 什么是EVPN多归属,和MC-LAG的区别?
- 搭载持续进化的企业级SONiC——AsterNOS网络操作系统,其开放的软件架构通过REST API开放全部网络功能给AI智算中心管理系统,实现无损以太网的自动化极简部署 → Easy RoCE:一键启用无损以太网
除存储网之外,基于通用、解耦、高性能的以太网硬件和开放软件框架,星融元可为大模型算力中心提供10G-800G的全场景互联能力。
关注vx公号“星融元Asterfusion”,获取更多技术分享和最新产品动态。















 935
935

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









