






大型语言模型(如GPT-4、Qwen2和LLaMA)在自然语言处理领域取得了革命性的进展,但它们可能面临领域特定知识的缺乏、信息更新不及时等问题。
GraphRAG通过利用图结构信息,提供了一种解决方案,以更精确和全面的方式检索信息,生成更准确、上下文相关的回答。
直接语言模型(Direct LLM)、检索增强型语言模型(RAG)和图检索增强型语言模型(GraphRAG)之间的比较。在给定用户查询的情况下,直接语言模型(LLMs)可能因为回答浅显或缺乏具体性而受到影响。检索增强型语言模型(RAG)通过检索相关文本信息来解决这个问题,一定程度上缓解了这个问题。然而,由于文本的长度和实体关系的自然语言表达的灵活性,RAG在强调问题核心的“影响”关系方面存在困难。而图检索增强型语言模型(GraphRAG)方法利用图数据中明确的实体和关系表示,通过检索相关的结构化信息,能够提供精确的答案。
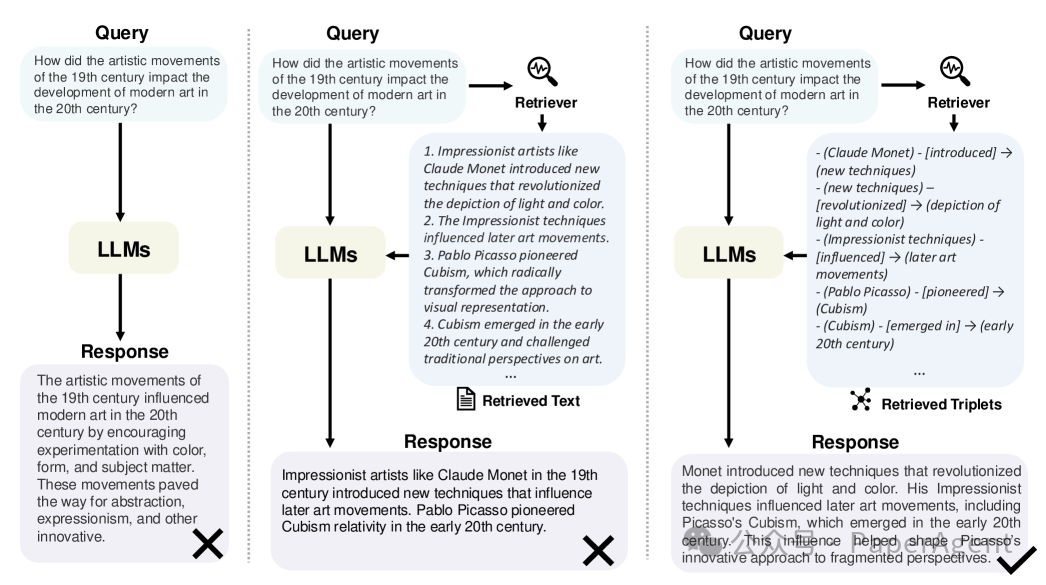
GraphRAG与相关技术
与RAG(Retrieval-Augmented Generation)相比,GraphRAG特别关注从图数据库中检索相关的关系知识,而不仅仅是文本。
与基于图的大型语言模型(LLMs on Graphs)和知识库问答(KBQA)技术相比,GraphRAG专注于检索外部图结构数据库中的相关图元素。
GraphRAG概述
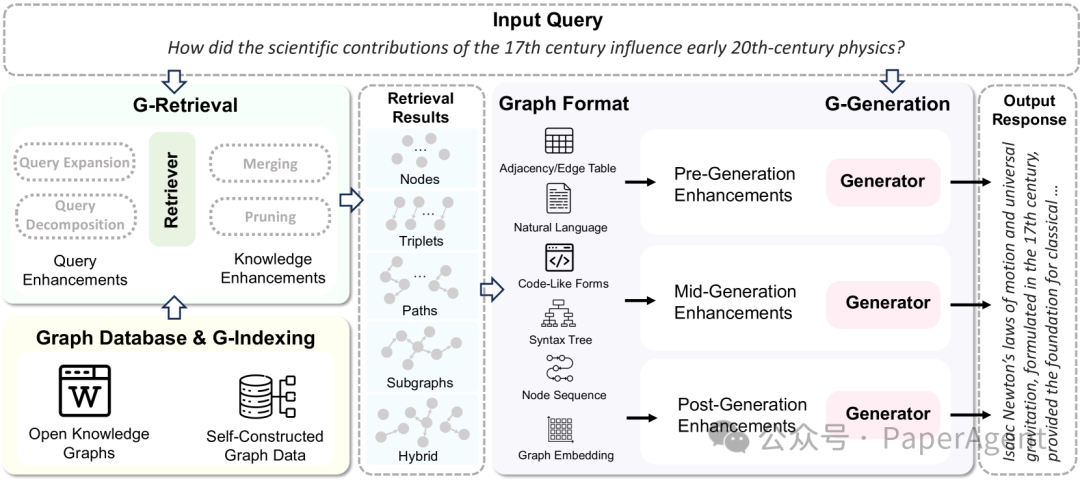
GraphRAG框架利用外部结构化知识图谱来提高语言模型的上下文理解能力,并生成更有信息量的回答。
问题回答任务的GraphRAG框架概述。将GraphRAG分为三个阶段:G-索引(G-Indexing)、G-检索(G-Retrieval)和G-生成(G-Generation)。将检索来源归类为开源知识图谱和自构建的图数据。为了提高结果的相关性,可能采用各种增强技术,如查询增强和知识增强。与直接使用检索到的文本进行生成的RAG不同,GraphRAG需要将检索到的图信息转换成生成器可接受的模式,以提高任务性能。
基于图的索引(Graph-Based Indexing)
讨论了构建和索引图数据库的方法,包括公开知识图谱和自构建图数据。
-
图数据库的构建和索引:图数据库的质量和结构直接影响GraphRAG的性能。图数据库可以来源于公开的知识图谱、图数据,或者基于专有数据源(如文本或其他形式的数据)构建。
-
图数据的分类:作者将图数据分为两类:
-
开放知识图谱:指从公开可获取的存储库或数据库中获取的图数据,可以进一步分为通用知识图谱和领域知识图谱。
-
自构建图数据:允许研究者根据特定任务的需求定制和整合专有或领域特定的知识。
-
-
通用知识图谱:存储一般性、结构化的知识,通常依赖于全球社区的集体输入和更新,以确保信息的全面性和持续更新。例如,Wikidata、Freebase、DBpedia和YAGO等。
-
领域知识图谱:针对特定领域构建的知识图谱,它们提供了特定领域的专业知识,帮助模型更深入地了解复杂专业关系。
-
自构建图数据:研究者常常从多个来源(如文档、表格和其他数据库)构建图,并利用GraphRAG来提升任务性能。这些自构建的图与特定方法的设计紧密相关。
-
索引方法:为了提高查询操作的效率和速度,图数据库采用了多种索引方法,包括图索引、文本索引和向量索引:
-
图索引:保持图的完整结构,便于访问任何给定节点的所有边和邻接节点。
-
文本索引:将图数据转换为文本描述,以优化检索过程。
-
向量索引:将图数据转换为向量表示,以提高检索效率。
-
-
索引的重要性:索引不仅影响检索方法和粒度,还直接影响到检索阶段的效率。
图引导的检索(Graph-Guided Retrieval)
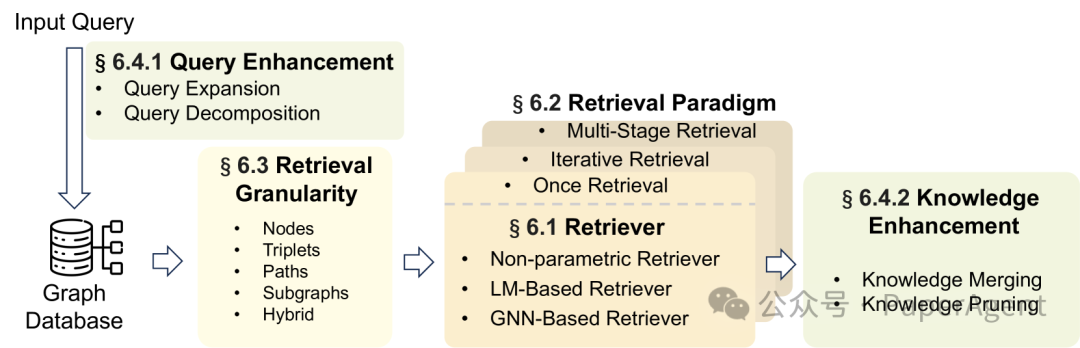
介绍了检索过程中的关键技术,包括检索器的选择、检索范式、检索粒度和有效的增强技术。
基于图的检索的通用架构
-
检索器(Retriever)的分类:根据底层模型,检索器被分为三类:
-
非参数检索器(Non-parametric Retriever):基于启发式规则或传统图搜索算法,不依赖深度学习模型,具有高检索效率。
-
基于语言模型的检索器(LM-based Retriever):利用语言模型的自然语言理解能力,处理和解释多样化的自然语言查询。
-
基于图神经网络的检索器(GNN-based Retriever):利用图神经网络理解复杂图结构的能力,编码图数据并根据与查询的相似性进行评分。
-
-
检索范式:讨论了不同的检索范式,包括一次性检索(Once Retrieval)、迭代检索(Iterative Retrieval)和多阶段检索(Multi-Stage Retrieval),它们在提高检索信息的相关性和深度方面起着重要作用。
-
检索粒度:根据任务场景和索引类型,设计了不同的检索粒度,包括节点(Nodes)、三元组(Triplets)、路径(Paths)和子图(Subgraphs)。每种粒度都有其优势,适用于不同的实际场景。
-
检索增强技术:为了确保检索质量,提出了增强用户查询和检索到的知识的技术,包括查询扩展和查询分解,以及知识合并和知识剪枝。
图增强的生成(Graph-Enhanced Generation)
讨论了生成阶段的不同技术,包括生成器的选择、图格式的转换以及生成增强技术。
图增强生成的概述

-
生成器(Generators)的选择:根据下游任务的类型,选择合适的生成器。对于判别性任务或可以表述为判别性任务的生成性任务,可以使用图神经网络(GNNs)或判别性语言模型来学习数据的表示。对于生成性任务,则需要使用解码器。
-
图神经网络(GNNs):GNNs因其强大的图数据表示能力而适用于判别性任务。它们可以直接编码图数据,捕捉图结构中固有的复杂关系和节点特征。
-
语言模型(LMs):LMs在文本理解方面表现出色,可以作为生成器使用。在将LMs与图数据结合时,需要先将检索到的图数据转换为LMs能够理解的特定图格式。
-
混合模型(Hybrid Models):许多研究探索了将GNNs和LMs整合以生成一致响应的方法。这些方法分为两种范式:级联范式和并行范式。级联范式中,GNNs首先处理图数据,然后将转换后的数据输入LMs以生成最终文本响应。并行范式则同时使用GNN和LM的能力,将它们的输出合并以产生统一的响应。
-
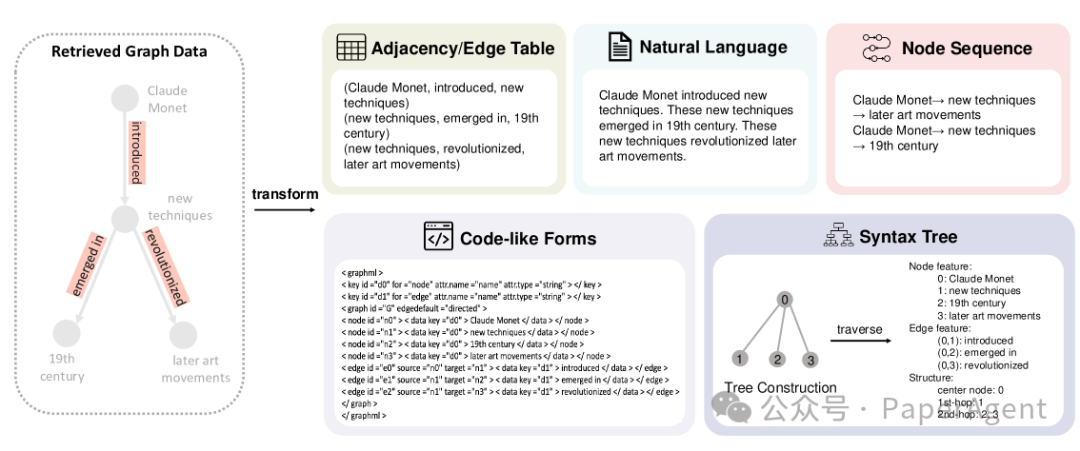
图格式(Graph Formats):当使用LMs作为生成器时,需要将图数据转换为与LMs兼容的格式。这包括图语言和图嵌入两种格式,它们帮助LMs有效地处理和利用结构化图信息。
-
图语言(Graph Languages):图语言是一套形式化的符号系统,用于描述和表示图数据。包括邻接/边表、自然语言、代码形式、语法树和节点序列等类型。
-
图嵌入(Graph Embeddings):使用GNN将图数据表示为嵌入,提供了一种避免处理长文本输入的替代方法。然而,将图嵌入与文本表示整合到统一的语义空间中是一个核心挑战。
-
生成增强(Generation Enhancement):在生成阶段,除了将检索到的图数据转换为生成器可接受的格式外,研究人员还探索了各种生成增强技术来提高输出响应的质量。这些方法可以根据应用阶段分为预生成增强、中生成增强和后生成增强。
-
训练策略:总结了检索器和生成器的独立训练方法,以及它们的联合训练策略,这些方法旨在通过特定的优化来提高下游任务的性能。
图语言的说明。给定左侧部分检索到的子图,展示了如何将其转换为邻接表/边表、自然语言、节点序列、类似代码的形式和语法树,以适应不同生成器的输入形式要求。
GraphRAG应用和评估
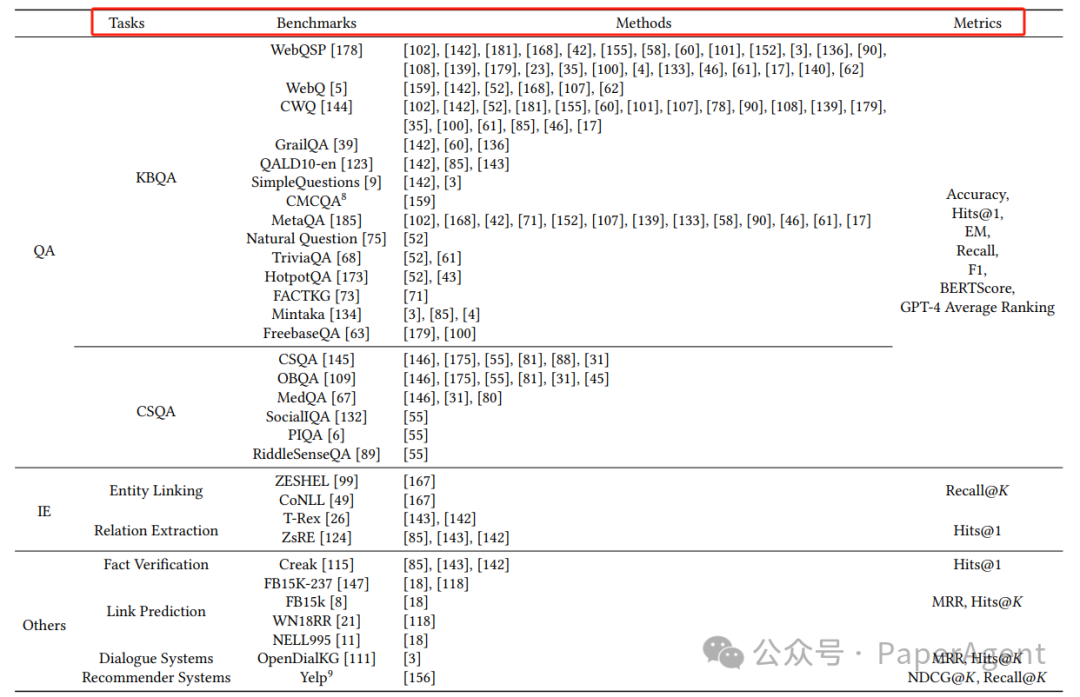
GraphRAG技术在不同领域的应用情况、基准测试、评估指标以及在工业界的应用。
-
下游任务(Downstream Tasks):
-
GraphRAG被应用于多种自然语言处理任务,主要包括知识库问答(KBQA)和常识问答(CSQA)。
-
KBQA依赖于特定知识图谱,答案通常涉及知识图中的实体、关系或实体集合之间的操作。
-
CSQA通常以多项选择题的形式出现,需要机器利用外部常识知识图谱进行推理和得出正确答案。
-
信息检索(Information Retrieval):
-
-
包括实体链接(EL)和关系提取(RE)两个子任务。
-
实体链接涉及识别文本中的实体并将其链接到知识图中的对应实体。
-
关系提取旨在识别和分类文本中实体间的语义关系。
-
-
-
评估指标(Metrics):
-
评估指标主要分为两大类:下游任务评估(生成质量)和检索质量评估。
-
例如,在KBQA中,Exact Match (EM) 和 F1 分数常用于衡量实体回答的准确性。
-
-
工业应用(GraphRAG in Industry):
-
几种工业界的GraphRAG系统,包括微软的GraphRAG、NebulaGraph的GraphRAG、蚂蚁集团的GraphRAG、Neo4j的NaLLM框架以及Neo4j的LLM Graph Builder项目。
-
GraphRAG的任务、基准测试、方法和评估指标
https://arxiv.org/pdf/2408.08921Graph Retrieval-Augmented Generation: A Survey
来源 | PaperAgent















 175
175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









