







循环神经网络
目录
一 RNN的结构及原理
<1> RNN的核心思想
<2>RNN的网络结构及原理
二 RNN训练
<1>RNN如何输入训练数据,格式是怎样?例子?
<2>如何训练参数?
三 RNN改进
<1>双向RNN
<2>深层双向RNN
四 LSTM(长短记忆神经网络–RNN的一种)
<1>RNN与LSTM的联系
<2>为什么要用LSTM
<3>LSTM的原理(为什么LSTM能解决该问题)
五 RNN练手项目
一 RNN的结构及原理
<1> RNN的核心思想
既然我们已经有了人工神经网络和卷积神经网络,为什么还要循环神经网络?
因为无论是卷积神经网络,还是人工神经网络,他们的前提假设都是:元素之间是相互独立的,输入与输出也是独立的。但现实世界中,很多元素都是相互连接的,比如股票随时间的变化等。RNN就是要解决这个不足。
RNN的核心思想:像人一样拥有记忆能力。用以往的记忆和当前的输入,生成输出。
<2>RNN的网络结构及原理
i>RNN的经典结构(单层)及原理
下图红色标记为RNN的基本单元(类似CNN的神经元):

其中是t时刻的输入是个序列(list);是t时刻记忆,是个矩阵;是t时刻的输出,是个序列(list);U,V,W是对应的参数,是矩阵。
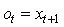 :上一个时刻的输出是这个时刻的输入。
:上一个时刻的输出是这个时刻的输入。
RNN用以往的记忆和当前的输入x,预测输出。
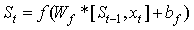
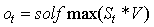
,即最终的输出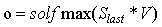
其中,f是激励函数,过滤(不重要的)信息。(理解:假如你在大学学了非常好的解题方法,那你初中那时候的解题方法还要用吗?显然是不用了的。RNN的想法也一样,既然我能记忆了,那我当然是只记重要的信息啦,其他不重要的,就肯定会忘记。至于过滤什么信息,取决于激励函数f长什么样。)
solfmax函数的作用是得到概率分布。
基本单元的内部结构和细胞内部细节图如下:


注:
1.可以把当作隐状态,捕捉了之前时间点上的信息。就像你去考研一样,考的时候记住了你能记住的所有信息。
2.是由当前时间以及之前所有的记忆得到的。就是你考研之后做的考试卷子,是用你的记忆得到的。
3.很可惜的是,并不能捕捉之前所有时间点的信息。就像你考研不能记住所有的英语单词一样。
4.和卷积神经网络一样,这里的网络中每个cell都共享了一组参数(U,V,W),这样就能极大的降低计算量了。(注意理解RNN的参数共享和CNN的参数共享的区别。)
5.输出是多或者一,根据需求而定。祥见”RNN的种类及应用”部分
ii>RNN多层网络
多层RNN神经网络结构如图:

RNN为什么要多层?
多了几层后,类似很多信息一次记不下来,要多次记忆才记得住。比如你去考研,复习考研英语的时候,背英语单词一定不会就看一次就记住了所有要考的考研单词,你应该也是带着先前几次背过的单词,然后选择那些背过,但不熟的内容,或者没背过的单词来背吧。
iii>RNN的种类及应用

应用场景:
1 V N: 输入一张图片到模型中–>输出文本序列 (属于第①种)
N V 1: 文本分类,文本序列 --> 文本分类;
下一个单词预测,对模型输入”the clouds are in the”–>输出”sky” (属于第②种)
N V N: 语言翻译,一个英语句子(序列) --> 一个中文句子(序列) (属于第③种)
二 RNN训练
<1>如何训练参数?
目的:得到模型最好的参数U,V,W
思路:类似BP算法。用BPTT求权重偏导(反向),用SGD更新参数直到损失函数满足阈值停止迭代(损失函数计算是前向计算)。
损失函数:
t时刻的损失函数:
总的损失函数: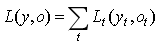
BPTT算法:(就是BP算法的延申…)
BP算法原理:进入我的博客查看《BP算法原理通俗易懂的讲解》那篇文章。
注:时序反向传播算法按照时间的逆序将错误信息一步步地往前传递过程,由链式法则求参数矩阵可知层内也会产生梯度消失和梯度爆炸。
<2>RNN如何输入训练数据,格式是怎样?例子?
给定一段文本当训练集样本,要求输入固定长度的文本序列预测下一/n个词(输入法的应用)训练细节解析(对隐藏层、基本单元更深入理解):
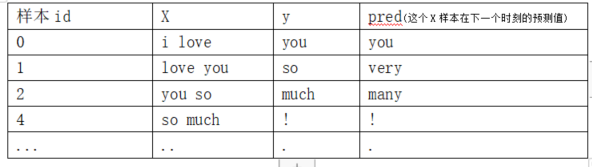
例如用一个文本训练模型,输入两个单词,模型输出这两个单词后边最有可能的一个单词:
待训练的文本为:[i love you so much! i miss you, do you love me baby?]
训练集如下:样本由文本所有单词以及标点符号、空格(本例为了表达方便,不考虑空格)组成。
对于RNN网络的理解:
(参考《RNN文本分类思路》)
RNN/CNN训练模型的大致思路为:神经网络神经元的运算本质是矩阵相乘。整个网络(不管是单层还是多层)输入x1,x2,…,xi都是针对单个样本而言,xi其实是每个输入样本的第i个特征。
网络输入n个样本个数就是在做矩阵相乘运算,[n,seq_length]=>[vocab, emb_size]–>[n,seq_length,emb_size],全连接层、softmax层之后得到输出[n, class_num],计算损失、更新损失都要用到所有输入的样本。
神经网络中的batch_size的作用是将总样本个数n每次分为batch_size个样本输入模型,为了分批加载训练数据做相应的计算避免内存报错,最后还是会汇总为[n, class_num],汇总损失,如果是用BGD更新参数,就全量样本统一做BP迭代,因为BGD每轮更新每一个参数都要用到全量的样本做计算。(一般是SGD,每轮更新每一个参数不用全量样本,所以可能不用统一做BP迭代)。
序列生成模型(正确性待进一步验证):
RNN模型如果不考虑U、V、W、st如何更新,其实就是一个黑盒子,给它一条一条样本,它就像人一样记住这些历史情况,得到下一时刻可能的情况。详细思路如下:
我们在训练和预测模型关注的是每条样本的输入和输出,每条样本的输入都要一致,每条样本的输出也要一致。对于本例,输入X格式是两个单词(或含标点符号),y格式是一个单词(或标点符号)。
而每条样本的输入对于RNN而言是有顺序的,如图结构st会记住每次输入的顺序、以及历史的输入情况(以训练更新st、U、V、W这些参数来达到“记住”这些情况),现有的这些参数就会对训练数据的下一个样本预测结果,并与真实标签对比,根据损失情况然后再更新参数(即又记住了包括最新这条样本的以往的情况)。但是,这样如果有多少条样本就要有多少个基本单元,其实本质就是更新多少次U、V、W和st。实际工程中,分批输入数据集(batch_size 参数),基本单元个数一般设置512个等取值(lstm_size参数)(*?可能等每批数据进来后(或训练数据达到基本单元个数后)更新这些基本单元但更新后的基本单元还是保留之前的记忆)
对于本例,当模型训练完后,一条全新的测试集如”so much”输入模型后,模型根据以往的知识(通过参数体现)就可能得到10维的向量(因为本例的全部不一样的单词、标点符号种类10种),表示这文本中所有可能的情况的概率,然后用一个全连接层(如sigmoid)得到概率最大的那个取值,输出对应的字符:”!”,如图:
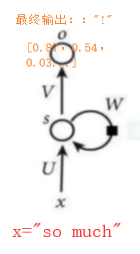
每一个单词在进行文本处理(如索引化后)之后都有一个相应的取值。假设单词的取值情况为:{you:3, so:7, much:7.2, many:9, !:12, very:7.5,…},则训练到本轮整体所有样本的损失为(3-3)+(7-7.5)+(7.2-9)+…。根据整体损失值情况再判断是否进行下一轮的迭代。
延申:如果要求输入两个单词,输出一串文本
则将第一个新的单词(或标点符号)保存,并用上一个单词(或标点符号)与这个新的组成两个,用这两个当作下一个输入输入到模型中,又生成了新的单词(或标点符号),不断地循环就是一串文本…
三 RNN改进
<1>双向RNN
在有些情况,比如有一部电视剧,在第三集的时候才出现的人物,现在让预测一下在第三集中出现的人物名字,你用前面两集的内容是预测不出来的,所以你需要用到第四,第五集的内容来预测第三集的内容,这就是双向RNN的想法。如图是双向RNN的图解:

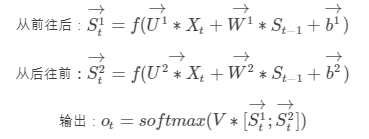
这里的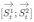 做的是一个拼接,如果他们都是1000X1维的,拼接在一起就是1000X2维的了。
做的是一个拼接,如果他们都是1000X1维的,拼接在一起就是1000X2维的了。
双向RNN需要的内存是单向RNN的两倍,因为在同一时间点,双向RNN需要保存两个方向上的权重参数,在分类的时候,需要同时输入两个隐藏层输出的信息。
<2>深层双向RNN
这样具备了“双向”的优点,也具备了“多层”的优点。


四 LSTM(长短记忆神经网络–RNN的一种)
<1>RNN与LSTM的联系
LSTM是循环神经网络中的一种。
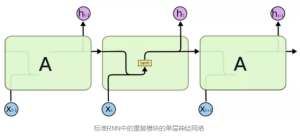
LSTM也拥有普通RNN的结构,不同的是,基本单元不一样。普通RNN基本单元有非常简单的结构,如单个tanh层,而LSTM的基本单元比较复杂。两者基本单元(重复单元)对比如下图。

<2>LSTM的优点(为什么要用LSTM)
(1)由(二)可知,时序反向传播算法按照时间的逆序将错误信息一步步地往前传递过程容易发生梯度消失或梯度爆炸。梯度爆炸比较好解决,可以通过梯度裁剪解决,而梯度消失问题比较复杂(CNN用了BN等几个方法解决了)。LSTM就是为了解决RNN层内梯度消失的问题。
(2)有选择地保存和输出历史信息。 -->因为门控单元
(3)可以学习长的依赖关系。 -->因为线性相加,不单单取决于激活函数
<3>LSTM的原理(为什么LSTM能解决该问题)
参考:
https://blog.csdn.net/u010754290/article/details/47167979
1 LSTM算法框架(前向传播):包括输入、输出、过程

1.1 输入门(input gate)

最终输入门输出为:
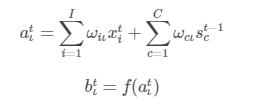
1.2 忘记门(forget gate)

最终忘记门的输出为:
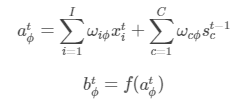
1.3 st的计算

1.4 输出门(output gate)

最终输出门的输出为:
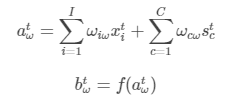
1.5 outputt

输入门控制当前计算的新状态以多大程度更新到记忆单元中;遗忘门控制前一步记忆单元多大程度被遗忘;输出门控制输出多大程度上取决于记忆单元。与RNN不同的是,记忆单元c的转移不一定完全取决于激活函数计算得到的状态,还由输入门和遗忘门共同控制。在一个训练好的LSTM模型中,当输入序列中没有重要信息时,遗忘门的值接近于1,输入门的值接近于0,表示过去的记忆被完整保存,而输入信息被放弃,从而实现长期记忆功能。当输入序列中存在重要信息时,LSTM应把他存入记忆中,此时输入门接近于1;当输入序列中存在重要信息且该信息意味着之前的记忆不再重要时,输入门的值接近1,遗忘门的值接近0。

最终outputt
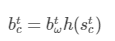
2 反向传播
BP算法、SGD结合使用,更新模型参数。
通过以上原理解析,易知,LSTM具有有选择地保存和输出历史信息、作用是可以学习长的依赖关系的优点。
最后的输出是两部分的“同或”运算,第一部分与RNN的运算相同,第二部分是通过三个门新增加的,这一部分正是LSTM的特别之处,在反向传播的过程中,不仅仅由o(t)起作用(因为,如果只有o起作用,那么就是跟传统RNN梯度消失的原理一样,连续几个小于1的偏导连乘,还是会出现梯度消失),从而解决了梯度消失的问题。
五 RNN练手项目
<1>用LSTM做文本情感分类:
https://blog.csdn.net/weixin_40363423/article/details/90085362
<2>用LSTM做文本生成:
https://blog.csdn.net/weixin_40363423/article/details/90085362
https://github.com/hzy46/Char-RNN-TensorFlow
【参考文献】
[1] https://blog.csdn.net/qq_39422642/article/details/78676567
[2] http://www.elecfans.com/d/717999.html
[3] https://www.e-learn.cn/content/qita/671741
[4] https://www.jianshu.com/p/4b4701beba92
[5] https://blog.csdn.net/zhangbaoanhadoop/article/details/81952284
[6] https://blog.csdn.net/u010754290/article/details/47167979















 5644
5644











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









