






#世界模型和DriveGPT这类大模型到底能给自动驾驶带来什么ne
以下分享大模型与自动驾驶结合的相关工作9篇论
1、ADAPT
ADAPT: Action-aware Driving Caption Transformer(ICRA2023)
ADAPT提出了一种基于端到端transformer的架构ADAPT(动作感知Driving cAPtion transformer),它为自动驾驶车辆的控制和动作提供了用户友好的自然语言叙述和推理。ADAPT通过共享视频表示联合训练驾驶字幕任务和车辆控制预测任务。
整体架构:
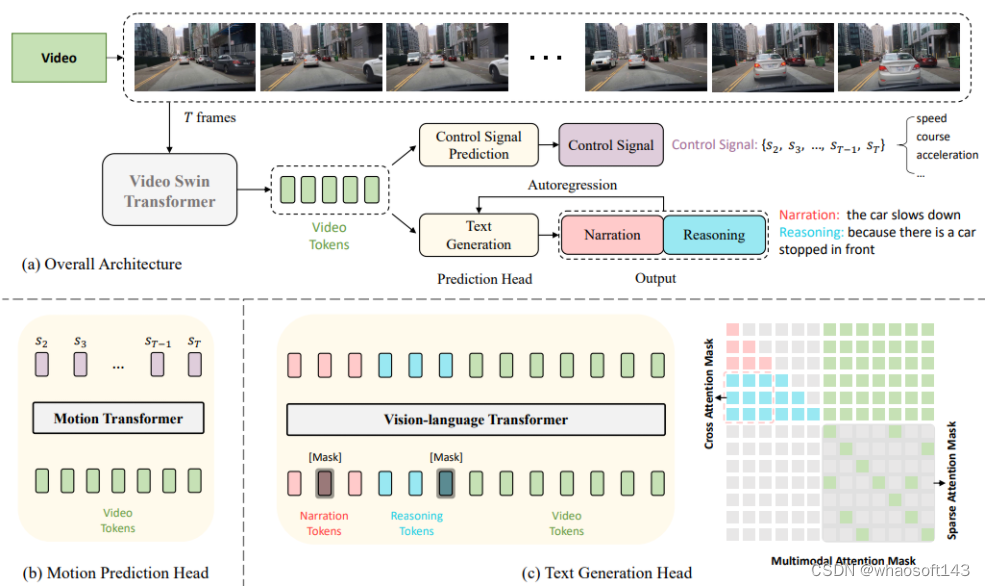
ADAPT框架概述,(a) 输入是车辆的前视图视频,输出是预测车辆的控制信号以及当前动作的叙述和推理。首先对视频中的T帧进行密集和均匀的采样,将其发送到可学习的视频swin transformer,并标记为视频标记。不同的预测头生成最终的运动结果和文本结果。(b) (c)分别显示预测头~

2、BEVGPT
Generative Pre-trained Large Model for Autonomous Driving Prediction, Decision-Making, and Planning.(AAAI2024)
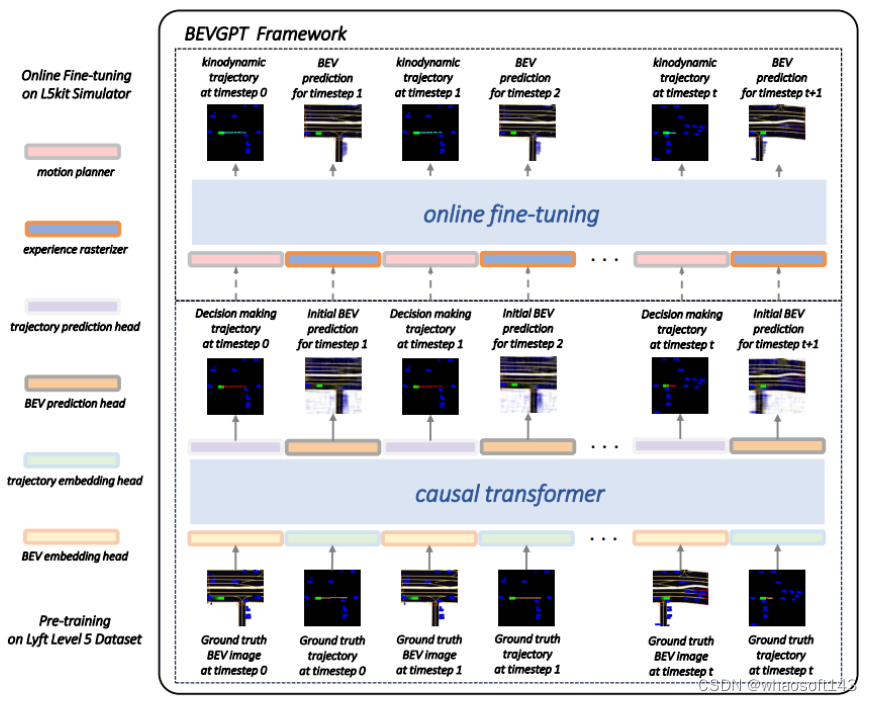
BEVGPT 是第一个生成式, 集预测、决策、运动规划于一体的自监督 pre-trained的大模型。输入BEV images, 输出自车轨迹, 并且能够输出对驾驶场景的预测, 该方案训练时需要高精地图。之所以叫GPT,一方面是因为利用了GPT式的自回归训练方法, 这里自回归的输入是历史的轨迹及BEV, target 是下一个BEV和轨迹。另一方面,能够做到生成, 即给定初始桢的BEV, 算法能够自己生成接下来的多帧BEV场景。该方法并不是一个从传感器输入的端到端方法, 可以看成是基于感知的结果,将后面的模块用一个模型给模型化了, 在实际中也有重要的应用价值. 比如能够基于很多驾驶回传数据的感知结果和轨迹真值来训练驾驶专家模型。
整体结构:
3、DriveGPT4
DriveGPT4 Interpretable End-to-end Autonomous Driving via Large Language Model
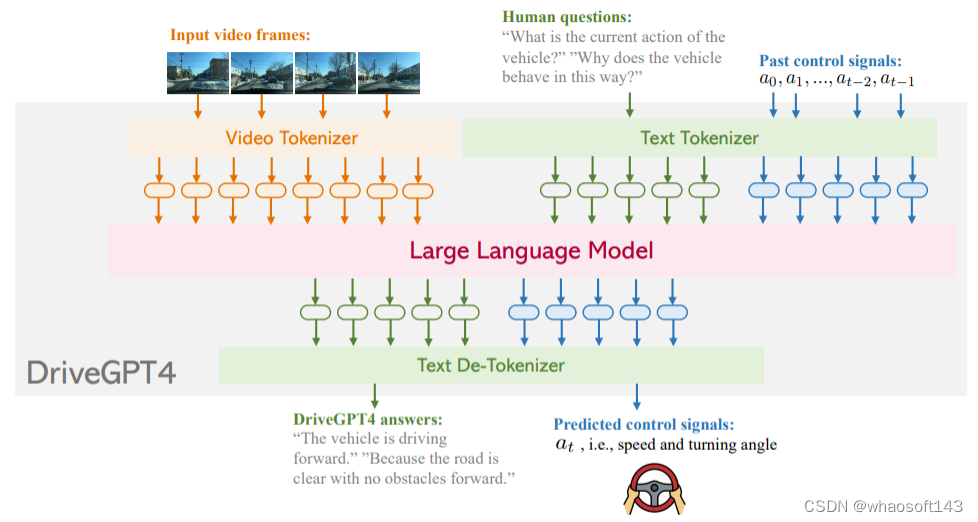
在过去的十年里,自动驾驶在学术界和工业界都得到了快速发展。然而其有限的可解释性仍然是一个悬而未决的重大问题,严重阻碍了自动驾驶的发展进程。以前使用小语言模型的方法由于缺乏灵活性、泛化能力和鲁棒性而未能解决这个问题。近两年随着ChatGPT的出现,多模态大型语言模型(LLM)因其通过文本处理和推理非文本数据(如图像和视频)的能力而受到研究界的极大关注。因此一些工作开始尝试将自动驾驶和大语言模型结合起来,今天汽车人为大家分享的DriveGPT4就是利用LLM的可解释实现的端到端自动驾驶系统。DriveGPT4能够解释车辆动作并提供相应的推理,以及回答用户提出的各种问题以增强交互。此外,DriveGPT4以端到端的方式预测车辆的运动控制。这些功能源于专门为无人驾驶设计的定制视觉指令调整数据集。DriveGPT4也是世界首个专注于可解释的端到端自动驾驶的工作。当与传统方法和视频理解LLM一起在多个任务上进行评估时,DriveGPT4表现出SOTA的定性和定量性能。
4、Drive Like a Human
Drive Like a Human: Rethinking Autonomous Driving with Large Language Models.
code:https://github.com/PJLab-ADG/DriveLikeAHuman
作者提出了理想的AD系统应该像人类一样驾驶,通过持续驾驶积累经验,并利用常识解决问题。为了实现这一目标,确定了AD系统所需的三种关键能力:推理、解释和记忆。通过构建闭环系统来展示LLM的理解能力和环境交互能力,证明了在驾驶场景中使用LLM的可行性。大量实验表明,LLM表现出了令人印象深刻的推理和解决长尾案例的能力,为类人自动驾驶的发展提供了宝贵的见解!
5、Driving with LLMs
Driving with LLMs: Fusing Object-Level Vector Modality for Explainable Autonomous Driving.
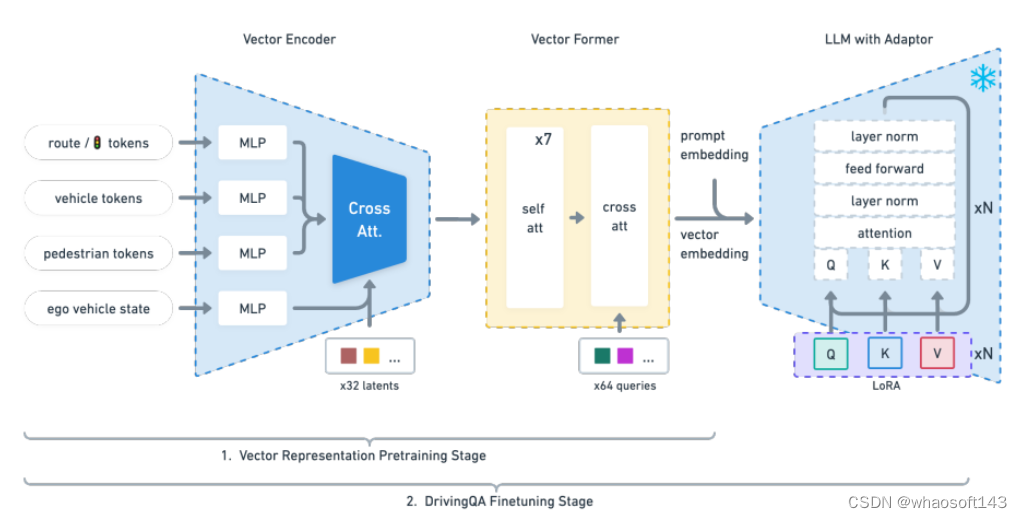
大型语言模型(LLM)在自动驾驶领域显示出了前景,尤其是在泛化和可解释性方面。本文引入了一种独特的目标级多模式LLM架构,该架构将矢量化的数字模态与预先训练的LLM相结合,以提高对驾驶情况下上下文的理解。本文还提出了一个新的数据集,其中包括来自10k驾驶场景的160k个QA对,与RL代理收集的高质量控制命令和教师LLM(GPT-3.5)生成的问答对配对。设计了一种独特的预训练策略,使用矢量字幕语言数据将数字矢量模态与静态LLM表示对齐。论文还介绍了驾驶QA的评估指标,并展示了LLM驾驶员在解释驾驶场景、回答问题和决策方面的熟练程度。与传统的行为克隆相比,突出了基于LLM的驱动动作生成的潜力。我们也提供了基准、数据集和模型以供进一步探索。
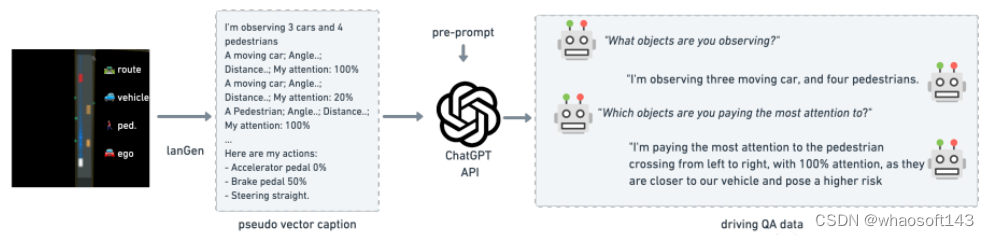
模型结构:
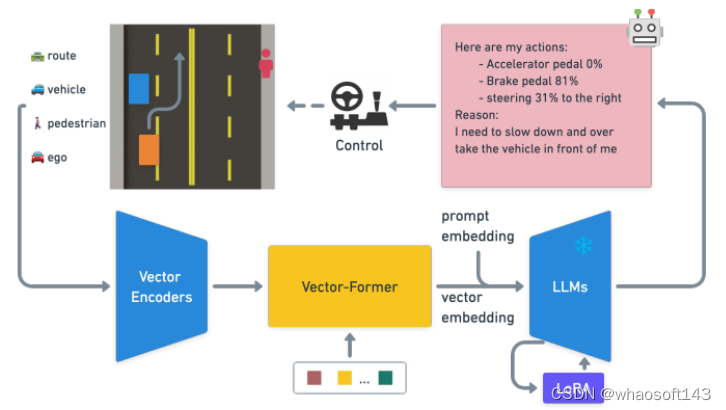
LLM驾驶体系结构概述,演示如何使用来自驾驶模拟器的对象级矢量输入来通过LLM预测动作!
6、HiLM-D
HiLM-D: Towards High-Resolution Understanding in Multimodal Large Language Models for Autonomous Driving.
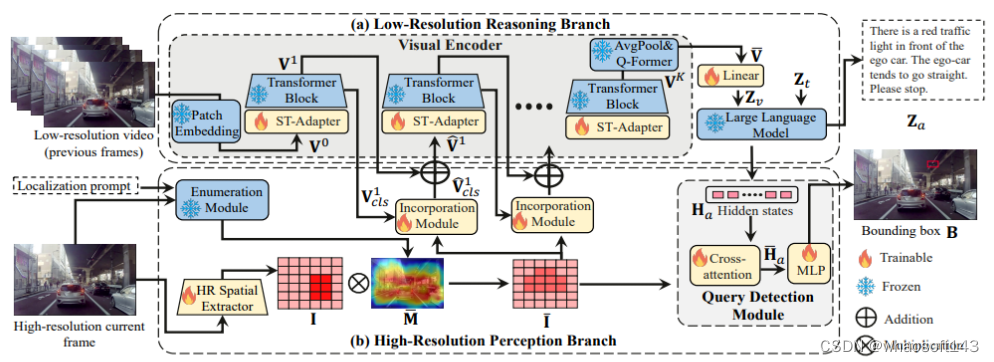
自动驾驶系统通常针对不同的任务使用单独的模型,从而产生复杂的设计。这是首次利用奇异多模态大语言模型(MLLMs)来整合视频中的多个自动驾驶任务,即风险目标定位和意图与建议预测(ROLISP)任务。ROLISP使用自然语言同时识别和解释风险目标,理解自我-车辆意图,并提供动作建议,从而消除了特定任务架构的必要性。然而,由于缺乏高分辨率(HR)信息,现有的MLLM在应用于ROLISP时往往会错过小目标(如交通锥),并过度关注突出目标(如大型卡车)。本文提出了HiLM-D(在用于自动驾驶的MLLMs中实现高分辨率理解),这是一种将人力资源信息整合到用于ROLISP任务的MLLMs中的有效方法。
HiLM-D集成了两个分支:
(i) 低分辨率推理分支可以是任何MLLMs,处理低分辨率视频以说明风险目标并辨别自我车辆意图/建议;
(ii)HiLM-D突出的高分辨率感知分支(HR-PB)摄取HR图像,通过捕捉视觉特异性HR特征图并将所有潜在风险优先于仅突出的目标来增强检测;HR-PB作为一个即插即用模块,无缝地适应当前的MLLM。在ROLISP基准上的实验表明,与领先的MLLMs相比,HiLM-D具有显著的优势,在BLEU-4中用于字幕的改进为4.8%,在mIoU中用于检测的改进为17.2%。
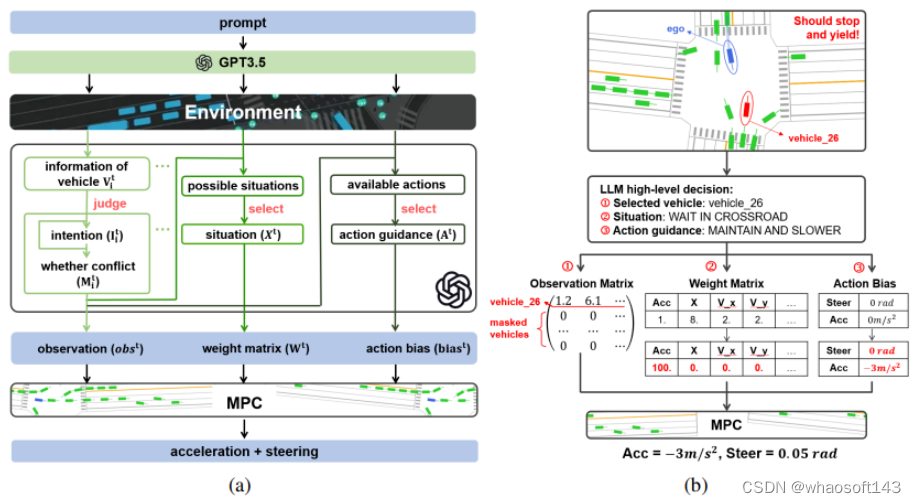
7、LanguageMPC
LanguageMPC: Large Language Models as Decision Makers for Autonomous Driving.
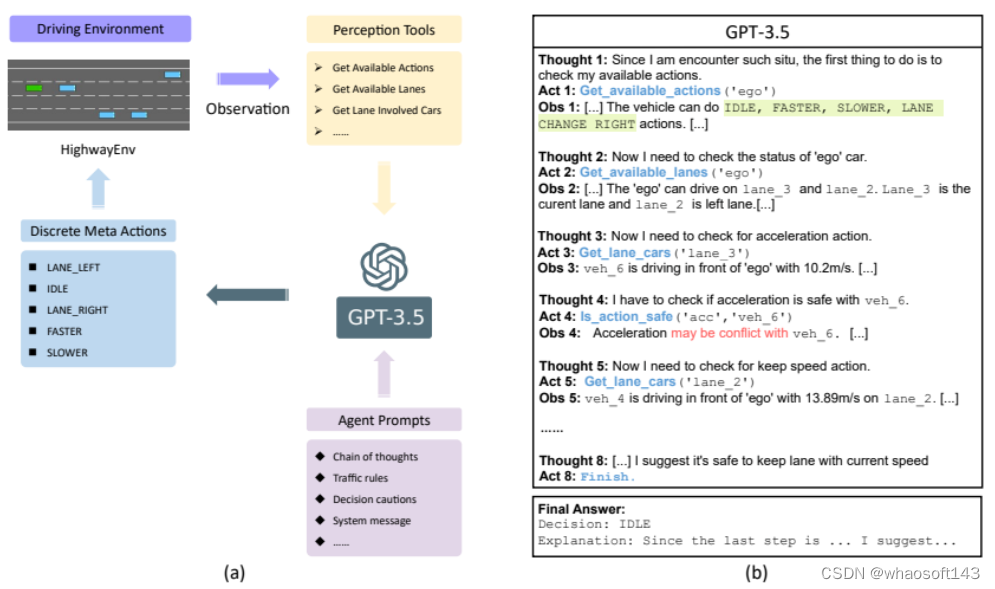
这项工作将大型语言模型(LLM)作为需要人类常识理解的复杂AD场景的决策组件。设计了认知途径,以实现LLM的全面推理,并开发了将LLM决策转化为可操作驾驶命令的算法。通过这种方法,LLM决策通过引导参数矩阵自适应与低级控制器无缝集成。大量实验表明,由于LLM的常识性推理能力,提出的方法不仅在单车任务中始终优于基线方法,而且有助于处理复杂的驾驶行为,甚至多车协调。本文在安全性、效率、可推广性和互操作性方面,为利用LLM作为复杂AD场景的有效决策者迈出了第一步,希望它能成为该领域未来研究的灵感来源。
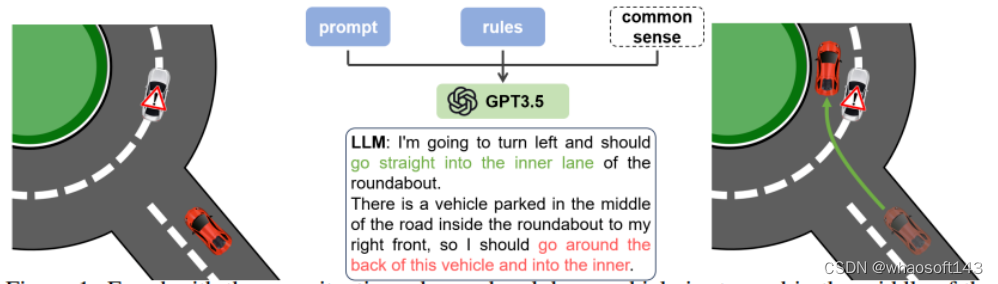
网络结构:
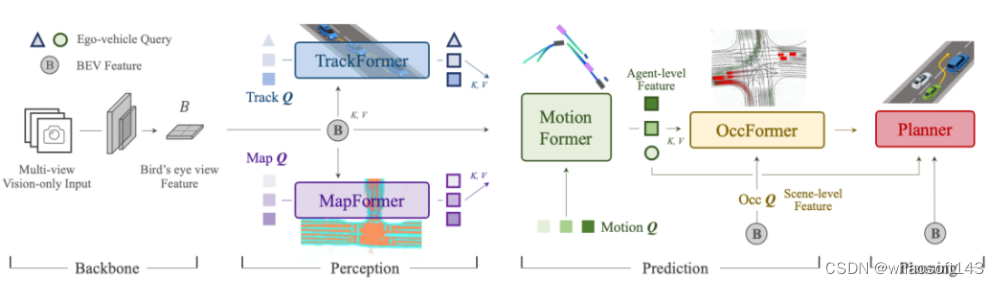
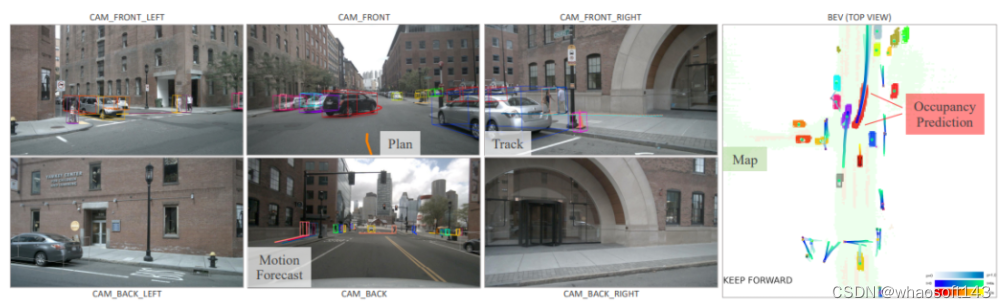
8、Planning-oriented Autonomous Driving
今年CVPR2023的best paper!UniAD将各任务通过token的形式在特征层面,按照感知-预测-决策的流程进行深度融合,使得各项任务彼此支持,实现性能提升。在nuScenes数据集的所有任务上,UniAD都达到SOTA性能,比所有其它端到端的方法都要优越,尤其是预测和规划效果远超其它模型。作为业内首个实现感知决策一体化自动驾驶通用大模型,UniAD能更好地协助进行行车规划,实现「多任务」和「高性能」,确保车辆行驶的可靠和安全。基于此,UniAD具有极大的应用落地潜力和价值。
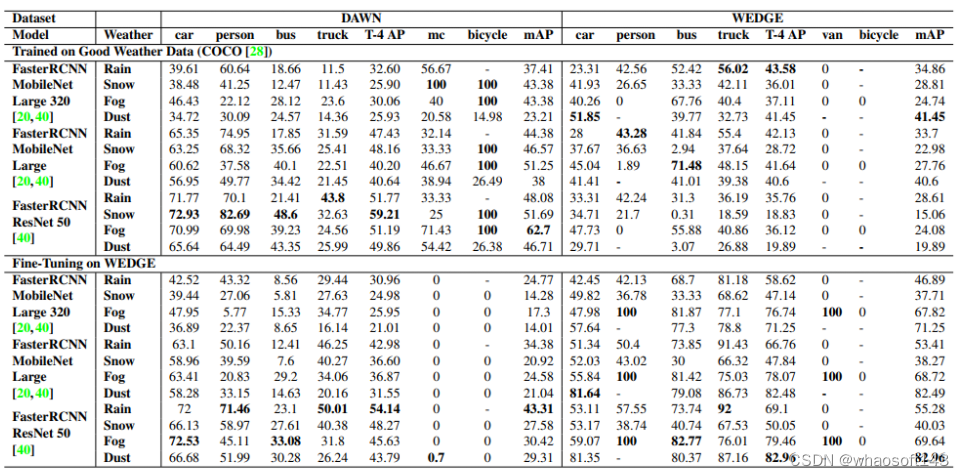
9、WEDGE
WEDGE:A multi-weather autonomous driving dataset built from generative vision-language models.
开放的道路给自主感知带来了许多挑战,包括极端天气。在好天气数据集上训练的模型经常无法在这些分布外数据(OOD)设置中进行检测。为了增强感知中的对抗性鲁棒性,本文引入WEDGE(WEather Images by DALL-E GEneration):一个通过提示用视觉语言生成模型生成的合成数据集。WEDGE 由 16 种极端天气条件下的 3360 张图像组成,并用 16513 个边框手动注释,支持天气分类和 2D 目标检测任务的研究。作者从研究的角度分析了WEDGE,验证了其对于极端天气自主感知的有效性。作者还建立了分类和检测的基线性能,测试准确度为 53.87%,mAP 为 45.41。WEDGE 可用于微调检测器,将真实世界天气基准(例如 DAWN)的 SOTA 性能提高 4.48 AP,适用于卡车等类别。


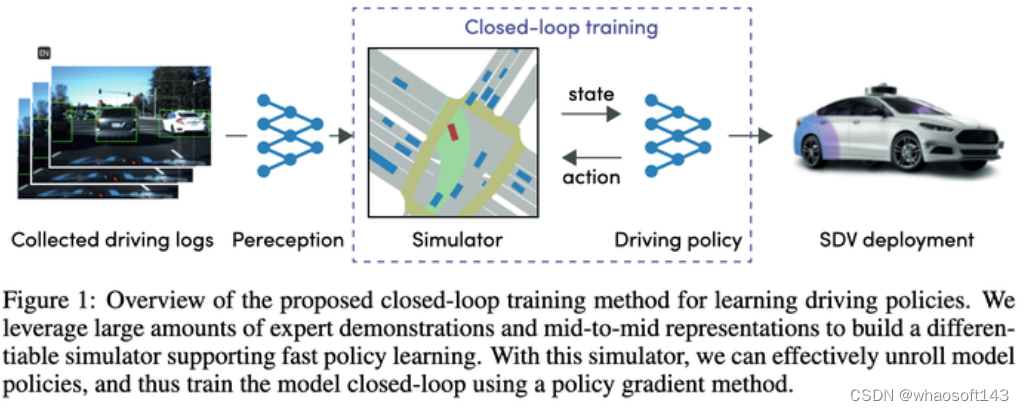
#自动驾驶端到端规划方法汇总
一、Woven Planet(丰田子公司)的方案:Urban Driver 2021
这篇文章是21年的,但一大堆新文章都拿它来做对比基线,因此应该也有必要来看看方法。
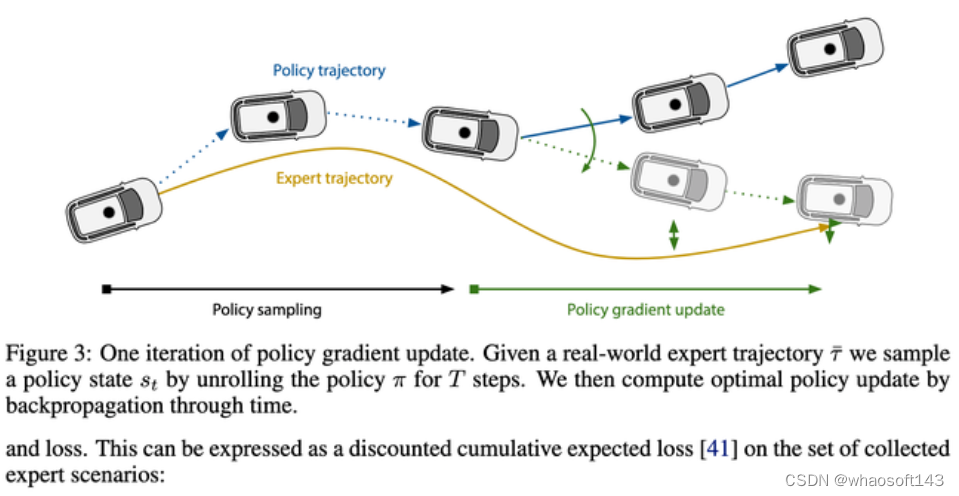
大概看了下,主要就是用Policy Gradients学习State->近期action的映射函数,有了这个映射函数,可以一步步推演出整个执行轨迹,最后loss就是让这个推演给出的轨迹尽可能的接近专家轨迹。
效果应该当时还不错,因此能成为各家新算法的基线。
二、南洋理工大学方案一 Conditional Predictive Behavior Planning with Inverse Reinforcement Learning 2023.04
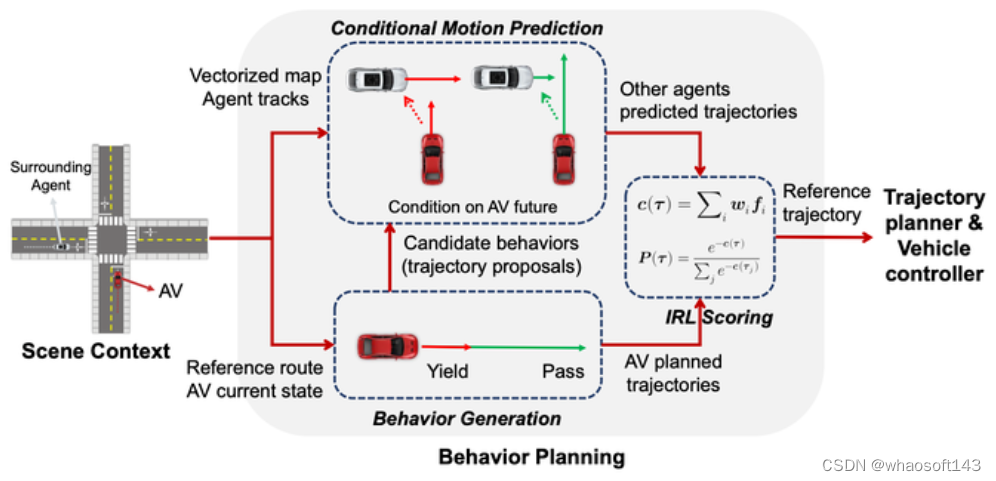
先使用规则枚举了多种行为,生成了10~30条轨迹。(未使用预测结果)
使用Condtional Prediction算出每条主车待选轨迹情况下的预测结果,然后使用IRL对待选轨迹打分。
其中Conditional Joint Prediction模型长这样:
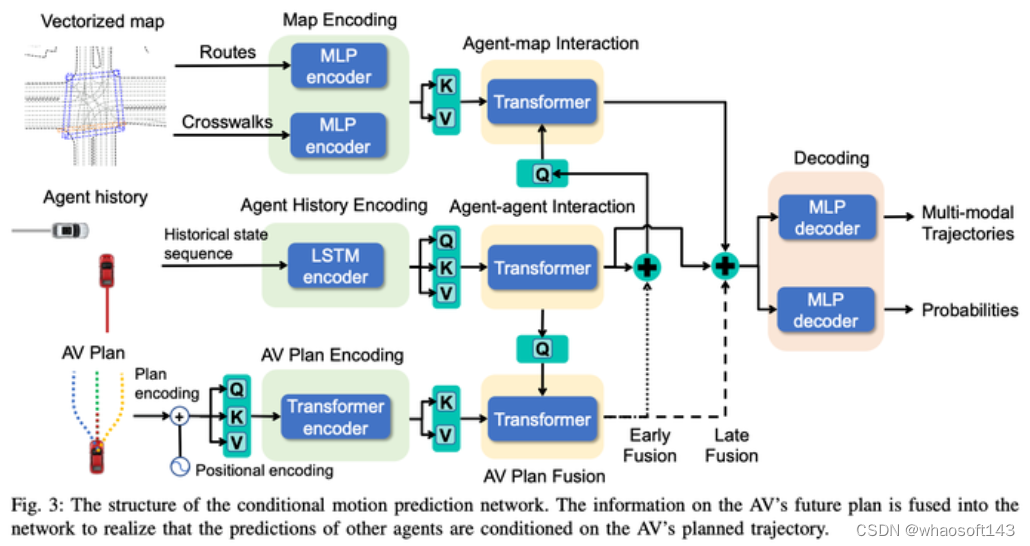
这个方法基本上很赞的点就是利用了Conditional Joint Prediction可以很好的完成交互性的预测,使得算法有一定的博弈能力。
但我个人认为算法缺点是前边只生成了10~30条轨迹,而且轨迹生成时没考虑预测,而且最后会直接在IRL打分后,直接选用这些轨迹中的一条作为最终结果,比较容易出现10~30条在考虑预测后发现都不大理想的情况。相当于要在瘸子里边挑将军,挑出来的也还是瘸子。基于这个方案,再解决前边待选样本生成质量会是很不错的路子
三、英伟达方案:2023.02 Tree-structured Policy Planning with Learned Behavior Models
用规则树状采样,一层一层的往后考虑,对每一层的每个子结点都生成一个conditional prediction,然后用规则对prediction结果和主车轨迹打分,并用一些规则把不合法的干掉,然后,利用DP往后生成最优轨迹,DP思路有点类似于apollo里dp_path_optimizer,不过加了一个时间维度。
不过因为多了一个维度,这个后边扩展次数多了之后,还是会出现解空间很大计算量过大的情况,当前论文里写的方法是到节点过多之后,随机丢弃了一些节点来确保计算量可控(感觉意思是节点过多之后可能也是n层之后了,可能影响比较小了)
本文主要贡献就是把一个连续解空间通过这种树形采样规则转变一个马尔可夫决策过程,然后再利用dp求解。
四、南洋理工大学&英伟达联合 2023年10月最新方案:DTPP: Differentiable Joint Conditional Prediction and Cost Evaluation for Tree Policy Planning in Autonomous Driving
看标题就感觉很Exciting:
一、Conditional Prediction确保了一定博弈效果
二、可导,能够整个梯度回传,让预测与IRL一起训练。也是能拼出一个端到端自动驾驶的必备条件
三、Tree Policy Planning,可能有一定的交互推演能力
仔细看完,发现这篇文章信息含量很高,方法很巧妙。
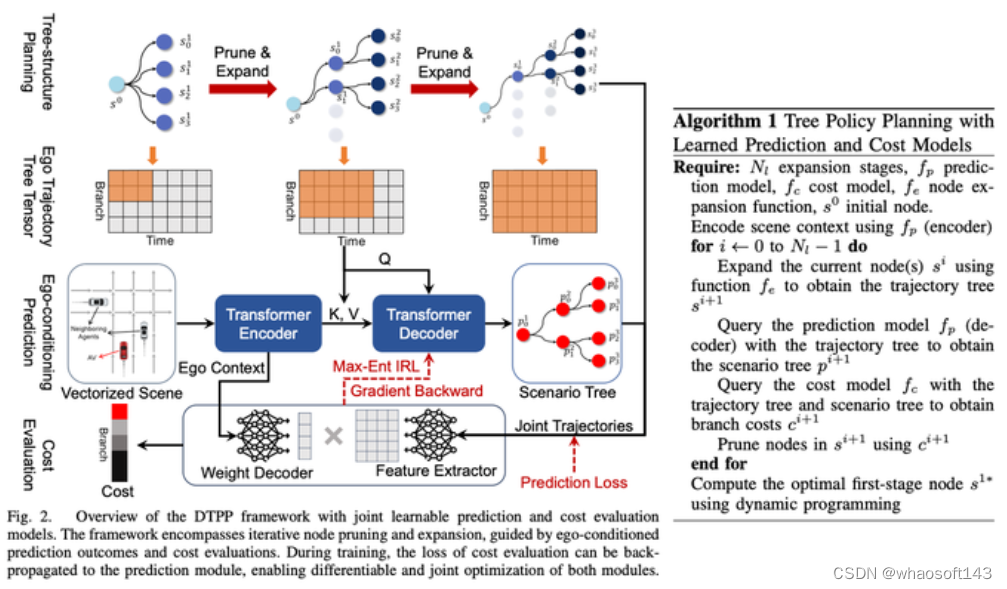
主要基于英伟达的TPP和南洋理工的Conditional Predictive Behavior Planning with Inverse Reinforcement Learning进行糅合改进,很好的解决了之前南洋理工论文中待选轨迹不好的问题。
论文方案主要模块有:
一、Conditional Prediction模块,输入一条主车历史轨迹+提示轨迹 + 障碍车历史轨迹,给出主车接近提示轨迹的预测轨迹和与主车行为自洽的障碍车的预测轨迹。
二、打分模块,能够给一个主车+障碍车轨迹打分看这个轨迹是否像专家的行为,学习方法是IRL。
三、Tree Policy Search模块,用来生成一堆待选轨迹
使用Tree Search的方案来探索主车的可行解,探索过程中每一步都会把已经探索出来的轨迹作为输入,使用Conditional Prediction来给出主车和障碍车的预测轨迹,然后再调用打分模块评估轨迹的好坏,从而影响到下一步搜索扩展结点的方向。通过这种办法可以得到一些差异比较大的主车轨迹,并且轨迹生成时已经随时考虑了与障碍车的交互。
传统的IRL都是人工搞了一大堆的feature,如前后一堆障碍物在轨迹时间维度上的各种feature(如相对s, l和ttc之类的),本文里为了让模型可导,则是直接使用prediction的ego context MLP生成一个Weight数组(size = 1 * C),隐式表征了主车周围的环境信息,然后又用MLP直接接把主车轨迹+对应多模态预测结果转成Feature数组(size = C * N, N指的待选轨迹数),然后两个矩阵相乘得到最终轨迹打分。然后IRL让专家得分最高。个人感觉这里可能是为了计算效率,让decoder尽可能简单,还是有一定的主车信息丢失,如果不关注计算效率,可以用一些更复杂一些的网络连接Ego Context和Predicted Trajectories,应该效果层面会更好?或者如果放弃可导性,这里还是可以考虑再把人工设置的feature加进去,也应该可以提升模型效果。
在耗时方面,该方案采用一次重Encode + 多次轻量化Decode的方法,有效降低了计算时延,文中提到时延可以压到98ms。
在learning based planner中属于SOTA行列,闭环效果接近前一篇文章中提到的nuplan 排第一的Rule Based方案PDM。
总结
看下来,感觉这么个范式是挺不错的思路,中间具体过程可以自己想办法调整:
- 用预测模型指导一些规则来生成一些待选ego轨迹
- 对每条轨迹,用Conditional Joint Prediction做交互式预测,生成agent预测。可以提升博弈性能。
- IRL等方法做利用Conditional Joint Prediction结果对前边的主车轨迹打分,选出最优轨迹















 2047
2047

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









