






点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
今天自动驾驶之心为大家分享中科院自动化所&理想汽车最新的工作—PlanAgent,文章提出一种全新基于多模态大语言模型MLLM的自动驾驶闭环规划框架,问鼎nuPlan SOTA!如果您有相关工作需要分享,请在文末联系我们!
也欢迎添加小助理微信AIDriver004,加入我们的技术交流群
论文作者 | Yupeng Zheng等
编辑 | 自动驾驶之心
中科院自动化所深度强化学习团队联合理想汽车等提出了一种新的基于多模态大语言模型MLLM的自动驾驶闭环规划框架—PlanAgent。该方法以场景的鸟瞰图和基于图的文本提示为输入,利用多模态大语言模型的多模态理解和常识推理能力,进行从场景理解到横向和纵向运动指令生成的层次化推理,并进一步产生规划器所需的指令。在大规模且具有挑战性的nuPlan基准上对该方法进行了测试,实验表明PlanAgent在常规场景和长尾场景上都取得了最好(SOTA)性能。与常规大语言模型(LLM)方法相比,PlanAgent所需的场景描述词符(token)量仅为1/3左右。
论文信息
论文题目:PlanAgent: A Multi-modal Large Language Agent for Closed loop Vehicle Motion Planning
论文发表单位:中科院自动化所,理想汽车,清华大学,北京航空航天大学
论文地址:https://arxiv.org/abs/2406.01587

1 引言
作为自动驾驶的核心模块之一,运动规划的目标是产生一条安全舒适的最优轨迹。基于规则的算法,如PDM[1]算法,在处理常见场景时表现良好,但往往难以应对需要更复杂驾驶操作的长尾场景[2]。基于学习的算法[2,3]常常会在长尾情况下过拟合,导致其在nuPlan中的性能并不如基于规则的方法PDM。
最近,大语言模型的发展为自动驾驶规划开辟了新的可能性。最新的一些研究尝试利用大语言模型强大的推理能力增强自动驾驶算法的规划和控制能力。然而,它们遇到了一些问题:(1)实验环境未能基于真实闭环场景(2)使用过量的坐标数字表示地图细节或运动状态,大大增加了所需的词符(token)数量;(3)由大语言模型直接生成轨迹点难以确保安全。为应对上述挑战,本文提出了PlanAgent方法。
2 方法
基于MLLM的闭环规划智能体PlanAgent框架如图1所示,本文设计了三个模块来解决自动驾驶中的复杂问题:
场景信息提取模块(Environment Transformation module):为了实现高效的场景信息表示,设计了一个环境信息提取模块,能够提取具有车道信息的多模态输入。
推理模块(Reasoning module):为了实现场景理解和常识推理,设计了一个推理模块,该模块利用多模态大语言模型MLLM生成合理且安全的规划器代码。
反思模块(Reflection module):为了保障安全规划,设计了一个反思机制,能够通过仿真对规划器进行验证,过滤掉不合理的MLLM提案。
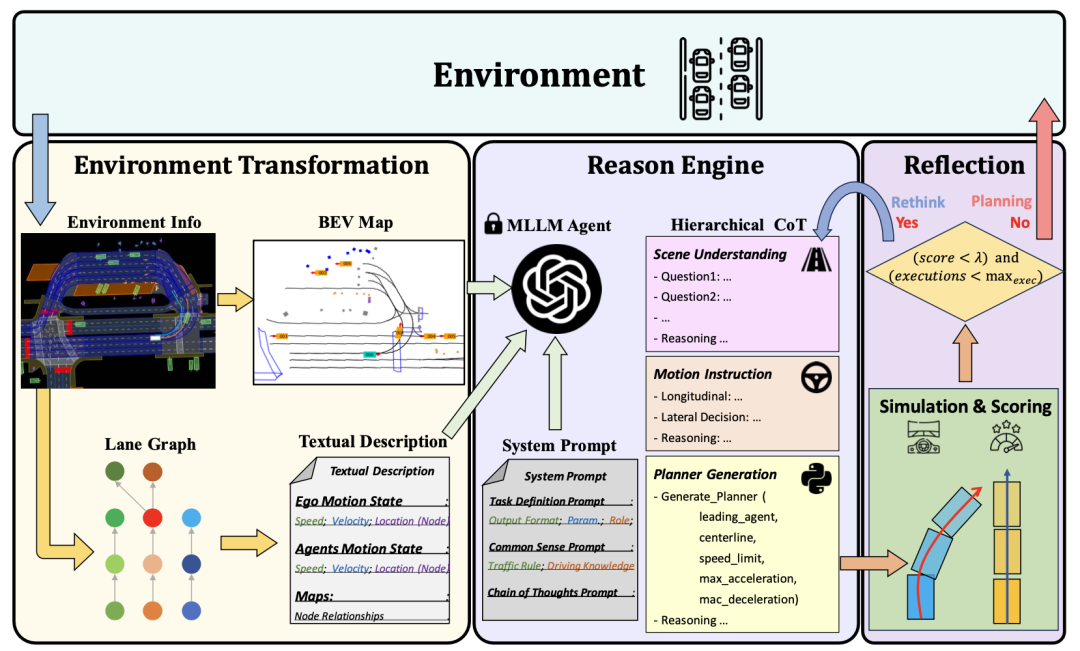
图1 PlanAgent的整体框架,包含场景信息提取/推理/反思模块
2.1 环境信息提取模块
大语言模型中的提示词(prompt)对其生成输出的质量有着至关重要的影响。为了提高MLLM的生成质量,场景信息提取模块能够提取场景上下文信息,并将其转换为鸟瞰图(BEV)图像和文本提示,使之与MLLM的输入保持一致。首先,本文将场景信息转化成鸟瞰图(BEV)图像,以增强MLLM对全局场景的理解能力。同时,需要对道路信息进行图表征,如图 2所示,在此基础上提取关键车辆的运动信息,使MLLM能够重点关注与自身位置最相关的区域。
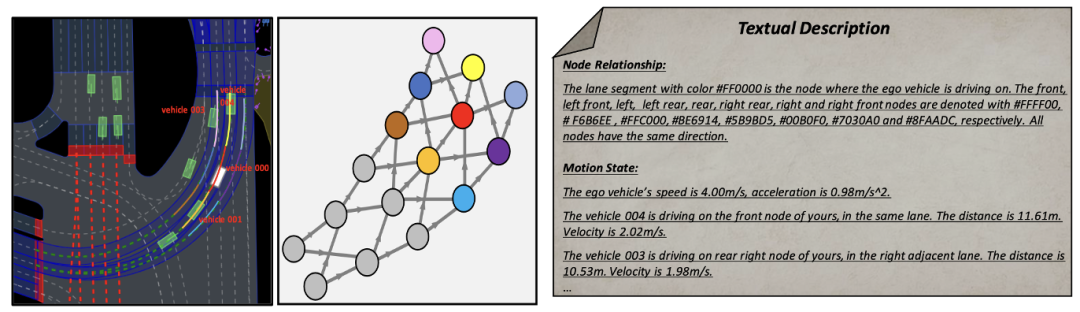
图2 基于图表征的文本提示描述
2.2 推理模块
如何将大语言模型的推理能力引入到自动驾驶规划过程中,实现具有常识推理能力的规划系统是一个关键问题。本文设计的方法能够以包含当前场景信息的用户消息和预定义的系统消息为输入,经过分层思维链多轮推理,生成智能驾驶员模型(IDM)的规划器代码。由此,PlanAgent能够通过上下文学习将MLLM强大的推理能力嵌入到自动驾驶规划任务中。
其中,用户消息包括BEV编码和基于图表征提取出来的周围车辆运动信息。系统消息包括任务的定义、常识知识以及思维链步骤,如图 3所示。

图3 系统提示模版
在得到prompt信息后,MLLM会对当前场景从三个层次进行推理:场景理解、运动指令和代码生成,最终生成规划器的代码。在PlanAgent中,会生成跟车、中心线、速度限制、最大加速度和最大减速度参数代码,再由IDM生成某一场景下的瞬时加速度,最终由此生成轨迹。
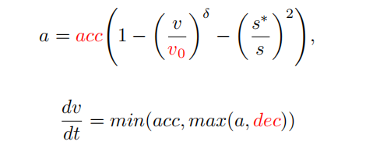
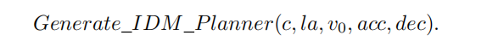
2.3 反思模块
通过以上两个模块强化了MLLM对场景的理解和推理能力。然而,MLLM的幻觉仍然对自动驾驶的安全构成了挑战。受到人类“三思而后行”决策的启发,本文在算法设计中加入了反思机制。对MLLM生成的规划器进行仿真模拟,并通过碰撞可能性、行驶距离、舒适度等指标评估该规划器的驾驶分数。当得分低于某个阈值τ时,表明MLLM生成的规划器欠妥,MLLM将被请求重新生成规划器。
3 实验与结果
本文在大规模真实场景的闭环规划平台nuPlan[4]进行闭环规划实验,以评估PlanAgent的性能,实验结果如下。
3.1 主要实验
表1 PlanAgent与其他算法在nuPlan的val14和test-hard基准上的比较
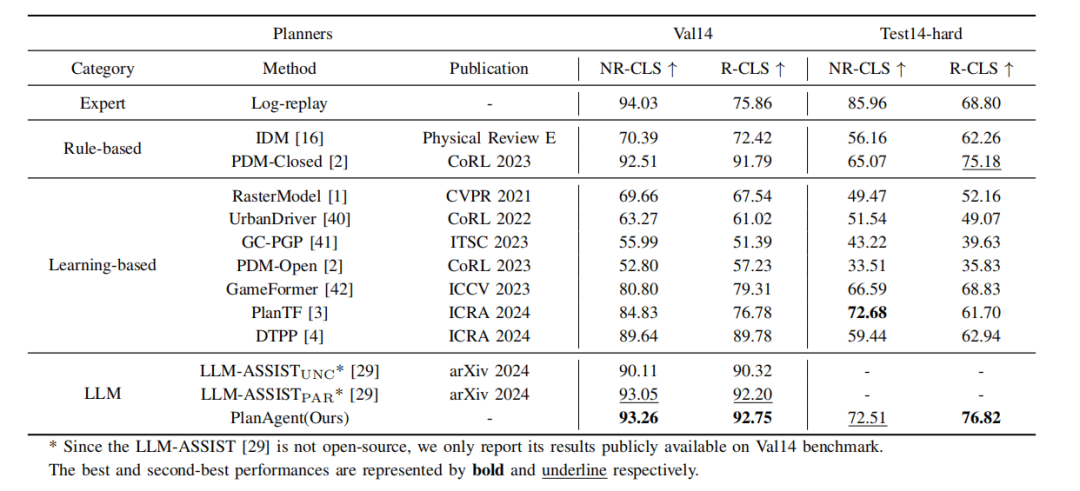
如表 1所示,本文将所提出的PlanAgent和三类最前沿的算法进行比较,并在nuPlan的两个基准val14和test-hard上进行测试。PlanAgent与其他方法相比表现出了有竞争力和可泛化的结果。
有竞争力的结果:在常见场景val14基准上,PlanAgent优于其他基于规则、基于学习和基于大语言模型的方法,在NR-CLS和R-CLS中都取得了最好的评分。
可泛化的结果:以PDM-Closed[1]为代表的规则类方法和以planTF[2]为代表的学习类方法都不能同时在val14和test-hard上表现良好。与这两类方法相比PlanAgent能够在克服长尾场景的同时,保证常见场景中的性能。
表2 不同方法描述场景所用token比较

同时,PlanAgent相比于其他基于大模型的方法所用的token数量更少,如表 2,大概只需要GPT-Driver[5]或LLM-ASSIST[6]的1/3。这表明PlanAgent能够用较少的token更有效地对场景进行描述。这对于闭源大语言模型的使用尤为重要。
3.2 消融实验
表3 场景提取模块中不同部分的消融实验
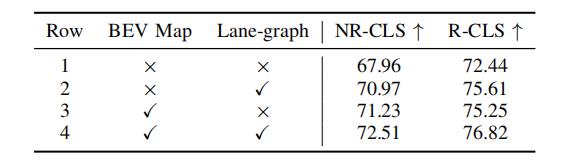
表4 分层思维链中不同部分的消融实验
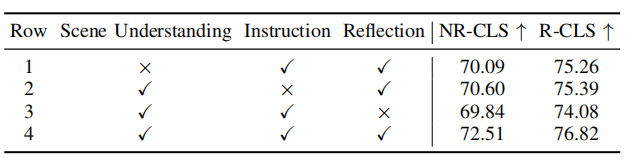
如表3和表4,本文对场景信息提取模块和推理模块中不同部分进行了消融实验,实验证明了各个模块的有效性和必要性。通过BEV图像和图表征两种形式可以增强MLLM对场景的理解能力,通过分层思维链能增强MLLM对场景的推理能力。
表5 PlanAgent在不同语言模型上的实验
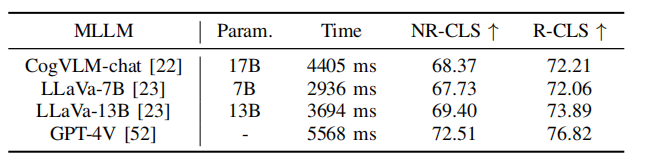
同时,如表 5所示,本文使用了一些开源大语言模型进行测试。实验结果表明,在Test-hard的NR-CLS基准上,PlanAgent使用不同的大语言模型分别能够比PDM-Closed的驾驶分数高出4.1%、5.1%和6.7%。这证明了PlanAgent与各种多模态大语言模型的兼容性。
3.3 可视化分析
环岛通行场景
PDM选择外侧车道作为centerline,车辆靠外侧车道行驶,在车辆汇入时卡住。PlanAgent判断有车辆汇入,输出合理的左换道指令,并生成横向动作选择环岛内侧车道为centerline,车辆靠内侧车道行驶。
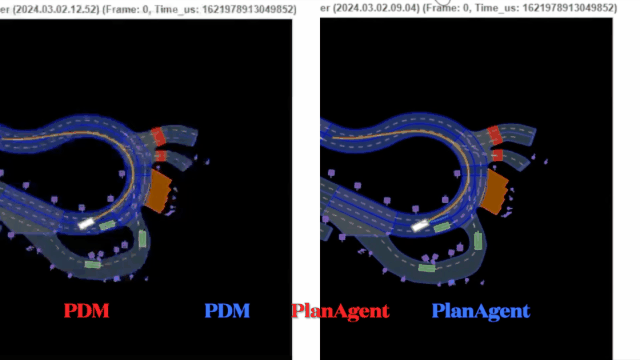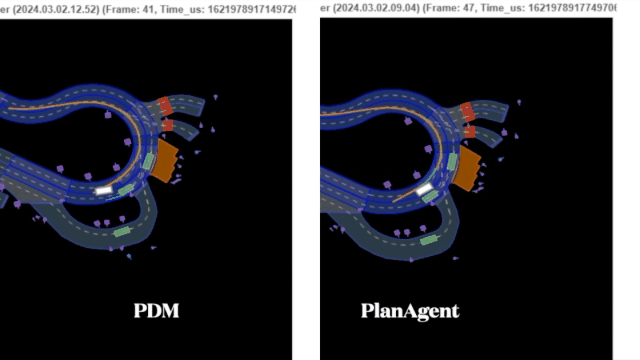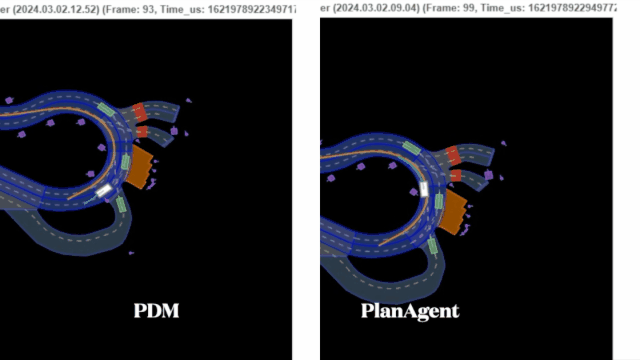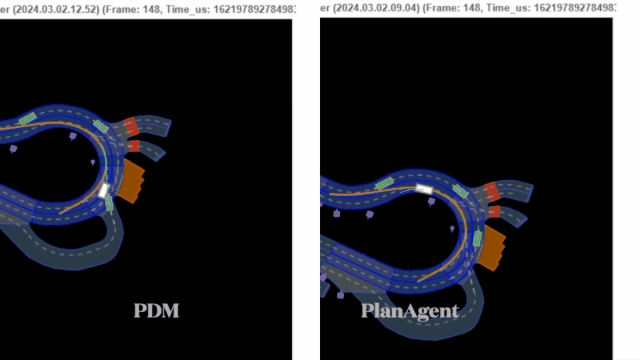
路口停止线停车场景
PDM选择了红绿灯类为跟车类。PlanAgent输出合理指令,选择停止线为跟车类。

4 结论
本文提出了一种新的基于MLLM的自动驾驶闭环规划框架,称为PlanAgent。该方法引入了一个场景信息提取模块,用于提取BEV图像,并基于道路的图表征提取周围车辆的运动信息。同时提出了一个具有层次结构的推理模块,用于指导MLLM理解场景信息、生成运动指令,最终生成规划器代码。此外,PlanAgent还模仿人类决策进行反思,当轨迹评分低于阈值时进行重规划,以加强决策的安全性。基于多模态大模型的自动驾驶闭环规划智能体PlanAgent在nuPlan基准上取得了闭环规划SOTA性能。
[1]D. Dauner, M. Hallgarten, A. Geiger, and K. Chitta, “Parting with Misconceptions about Learning-based Vehicle Motion Planning,” CoRL, 2023.
[2]J. Cheng, Y. Chen, X. Mei, B. Yang, B. Li, and M. Liu, “Rethinking Imitation-based Planner for Autonomous Driving,” ICRA, 2024.
[3]Z. Huang, P. Karkus, et al., “DTPP: Differentiable Joint Conditional Prediction and Cost Evaluation for Tree Policy Planning in Autonomous Driving,” ICRA, 2024.
[4]N. Karnchanachari, D. Geromichalos, et al., “Towards Learning-based Planning: The nuPlan Benchmark for Real-world Autonomous Driving,” arXiv preprint arXiv:2403.04133, 2024.
[5]J. Mao, Y. Qian, H. Zhao, and Y. Wang, “GPT-Driver: Learning to Drive with GPT,” arXiv preprint arXiv:2310.01415, 2023.
[6]S. Sharan, F. Pittaluga, M. Chandraker, et al., ‘LLM-Assist: Enhancing Closed-Loop Planning with Language-Based Reasoning,” arXiv preprint arXiv:2401.00125, 2024.
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 网页端官网:www.zdjszx.com
网页端官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵















 211
211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









