










摘要
当前多模态机器翻译NMT模型并不能充分利用不同模态的语义单元之间的细粒度语义对应,这具有细化多模态表示学习的潜力
1.引言
NMT将图像作为额外的输入扩展文本翻译
如何充分利用视觉信息是多模态NMT的核心问题之一,它直接影响了模型的性能
1)将每个输入图像编码成全局特征向量,可用于初始化多模态NMT模型的不同组件,或作为额外的源标记,或学习联合多模态表示;
2)提取基于对象的图像特征以初始化模型或补充源序列,或生成基于注意的视觉上下文
3)将每幅图像表示为空间特征,可以作为额外的上下文利用,或通过注意机制对源语义的补充
但仍并没有充分利用输入句子-图像对中语义单元之间的细粒度语义对应关系
1)如何构建一个统一的表示来弥合两种不同模式之间的语义差距(文本和图像两个模态)
2)如何实现基于统一表示的语义交互
将文本和图像表示成一个多模态图,每个节点表示一个语义单元:文本单词或视觉对象,并引入两种类型的边来建模同一模态(模态内边)之间的语义关系和不同模态的语义单元(模态间边)之间的语义对应关系。
堆叠多个基于图的多模态融合层,迭代地执行节点之间的语义交互,以进行图编码。在这个过程中,区分了两种模态的参数,并依次进行模态内和模态间的融合来学习多模态节点的表示。最后,解码器可以通过一种注意机制来利用这些表示。
2.
最大似然估计作为损失函数
2.1 编码器
2.1.1 多模态图
无向图,每个节点代表一个文本单词或一个视觉对象
构建节点策略:
(1)将所有单词作为单独的文本节点,以充分利用文本信息。例如每个节点对应于输入句子中的一个单词
(2)使用斯坦福解析器来识别输入句子中的所有名词短语,然后应用一个visual grounding toolkit (Yang et al., 2019)来检测每个名词短语的bounding boxes(视觉对象)。随后,所有检测到的视觉对象都被包括为独立的视觉节点(有点聚类成节点的意思?)。这样就可以有效地减少大量不相关的视觉物体的负面影响(目标检测领域提出的什么去背景吗?)。(以及没有解释边的构造有什么讲究吗?异构边诶)

2.1.2 嵌入层
初始化节点状态
对于词节点,初始化为词嵌入和位置编码的和
对于图像节点,先通过FasterRCNN中ROI池化层(提取感兴趣区域?)之后的全连接层中提取视觉特征,然后经过relu激活的MLP将这些特征投影到词节点表示的空间(为啥这样就能统一空间?)
2.1.3 基于图的多模态融合层
1.模态内融合
通过自注意力机制(QKV那个多头注意力机制),根据节点的同模态邻居得到上下文表示
对于已经CNN过的图像节点,QKV要特殊简化
2.模态间融合
(Teney et al., 2018; Kim et al., 2018)
具有元素级操作的跨模态门控机制来采集每个节点的跨模态邻居的语义信息。
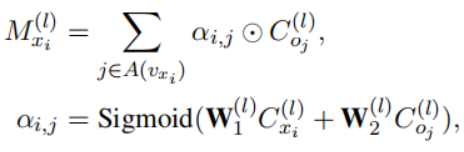
优点:可以根据每种模态的上下文表示,更好地确定模态间融合的程度。
最后采用位置级前馈网络FFN来生成文本节点状态和视觉节点状态
2.2 解码器
类似于传统的Transformer解码器。由于通过多个基于图的多模态融合层,视觉信息已经被合并到所有文本节点中(不同模态的节点合并了?),解码器可以通过只关注文本节点状态来动态地利用多模态上下文(?)。
堆叠Ld个相同的层,生成目标端隐藏状态,其中每一层l由三个子层组成。前两个子层是掩蔽自注意力和编码-解码注意力,分别集成目标端和原始端上下文(还是QKV)
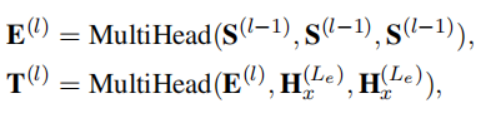
其中S(l−1)表示第l层的目标侧隐藏状态。特别是,S(0)是输入目标词嵌入。最后再S(l) = FFN(T(l))
最后,利用softmax定义生成目标句子的概率分布,并以顶层的隐藏状态作为输入:

其中X是输入句子,I是输入图像,Y是标签句子
4.相关
Teney et al. (2017) VQA
(Visual Question Answering,视觉问答)的GNN。区别是,该文为每个模态建立了一个单独的图,而本文使用一个统一的多模态图














 964
964











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









