







2021
摘要
社交网络中用户生成的内容通常包含图像、视频等多模态数据。多模态主题检测对融合和对齐不同模式的异构特征提出了新的挑战
引言
本文主要研究了图像-文本社交网络数据的多模态主题检测问题。受[19]中引入的图融合网络(GFN)的启发
(就是Modality to modality translation: an adversarial representation learning and graph fusion network for multimodal fusion这一篇),我们采用了一个基于GFN的编码器和一个多层感知器(MLP)解码器来解决多模态主题检测中的融合问题。与原来的GFN不同,我们设计了一个重构损失函数,以无监督的方式约束编码器和解码器的学习过程。该编码器通过逐层构造顶点来分层融合多模态信息,其中将特征视为顶点,将多模态动力学视为边。因此,融合表示包含信息结构,提供了显式的多模态动力学和丰富的语义信息,提高了多模态主题检测性能。在Yelp数据集上的实验结果表明,我们提出的方法优于基线方法。
过去
Mai等人开发了一种图融合网络(GFN)[19],通过逐层构建顶点和边,分层融合多模态特征。融合的表示包含信息结构和显式的多模态动力学,有利于主题检测。因此,我们采用了一个基于GFN的编码器和一个MLP解码器来学习输入数据中丰富的语义信息,以提高多模态主题检测的性能。
方法
该模型由特征嵌入模块F、图融合模块G和聚类模块C.组成,以原始图像和文档作为输入,提取视觉和文本特征向量。然后G分层融合多模态信息,通过图融合输出具有信息结构的表示。基于融合的表示形式,C采用聚类算法进行主题检测。

编码器
视觉:预训练过的VGG16对输入图像提取特征(就是说这里并不参与从头训练学习?是拿个现成的模型相当于,顶多有些微调吧,迁移学习真的无赖)
文本:
我们使用NLTK[5]来进行文本标记化。然后用GloVe[21]中预训练的单词嵌入初始化标记序列seq={e1,e2,…,eL},得到向量表示,其中ei∈RDe,L为序列的长度。最后,我们使用一个带有LSTM细胞[11]的双向递归神经网络(BiRNN)[24]来获得嵌入序列的隐藏状态表示,其中h∈Rf。
(那不就是BiLSTM)
图融合
受[19]的启发,E将多模态特征视为顶点
(不就两模态?那节点到底是怎么建模的?),以及模态与边之间的模型交互。在第一层中,采用一个模态注意网络MAN∈Rf→R1来重新加权多模态特征的重要性。然后我们对重新加权的特征向量进行平均,得到第一层的最终输出,即单模态 dynamics U:
(就是说两模态特征通过学习单元MAN得到后面计算U所用的权重α吧,加权的权重通过学习得到这个思路)
(后接MLP,两模态特征拼接送入,学习V)
正如[19]中所介绍的,两个向量彼此越接近,它们之间存在的互补信息就越少。因此,我们使用一个矩阵Sv,h来描述多模态特征向量的相似性:(安定的内积相似度,先做soft归一化)
连接第一层和第二层顶点的边的权重定义为:(讲究是什么?)
第二层的最终输出,即组合的双模态 dynamics B,是通过重新加权计算出来的:
从而融合表示
最后解码
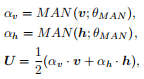
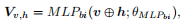
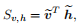
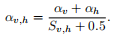
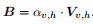

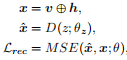
聚类
在z的基础上聚类,自动识别输入数据的潜在主题:(相当于一般AE或者GAN的嵌入分类环节吧)
T
p
=
C
(
z
)
T_p = C(z)
Tp=C(z)
用Birch聚类















 854
854











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









