









摘要
主流的模态融合方法未能实现学习多模态的嵌入空间这一目标
本文提出了一种新的对抗性编码器-解码器分类器框架
由于不同模态的分布在本质上有所不同,为了减少模态差距,使用对抗性训练通过各自的编码器将源模态的分布转换为目标模态的分布。
此外,通过引入重构损失和分类损失来对嵌入空间施加额外的约束。然后利用层次图神经网络融合编码表示(是把图融合成编码向量,还是融合成图后再进一步得到编码),明确地探索了多阶段的单峰、双峰和三峰相互作用
引言
(Baltrusaitis, Ahuja, ˇand Morency 2019)可以证明多模态就是比单模态好
多模态融合的一个关键问题在于来自不同模式的异构数据分布 (Baltrusaitis, Ahuja, and Morency 2019),导致了跨模式挖掘互补信息的困难,这对多模态信息的全面解释至关重要。
以往的大部分工作都没有致力于学习各种模态的联合嵌入空间来匹配多模态分布。相反,他们将每个模态应用到一个子网络,然后立即进行融合 (Zadeh et al. 2017;Poria et al. 2017b; Liu et al. 2018)(还是决策层融合呗?)。
生成对抗网络(GANs)可以使用对抗性训练明确地将一个分布映射到另一个先验分布(Makhzani et al. 2016)。
在此基础上,提出了一个对抗性编码器框架来匹配所有模态的变换分布,并学习一个模态不变的嵌入空间。
为每个模态定义一个解码器,重建原始特征,以防止单峰信息丢失。此外,还建立一个分类器,将编码的表示分类为真类别,确保了嵌入空间对学习任务具有鉴别性。
此外,许多先前的方法不能以分层hierarchical的方式进行融合,也不能明确地建模多个模式的每个子集之间的相互作用(Poria et al. 2017b; Liu et al. 2018; Zadeh et al. 2018b)。
于是本文将多模态融合解释为一个层次交互学习过程,首先基于单模态相互作用dynamics生成双模态交互,然后基于双模态和单模态相互作用生成三模态相互作用。
以图融合网络作为这个层次融合网络,这样在融合过程中是高度可解释的。
这个图融合网络由三层组成,分别包含单峰、双峰和三峰相互作用。底层的顶点将其信息传递到高层,在那里信息被融合,形成高层的多模态信息。通过这种方法,可以在分层探索跨模式交互的同时,仍然保持原始交互。
相关
传统多模态融合的研究主要集中在早期融合和晚期融合上。
早期的融合方法提取各种模式的特征,并通过简单的连接在输入级融合特征(简单的特征层融合)(Wollmer et al. 2013; Poria et al. 2016)但不能完全探索模式内相互作用(Zadeh等。2017)。
相比之下,晚期融合首先根据每种方式做出决策,然后通过加权平均来融合决策 (Nojavanasghari et al. 2016;Kampman et al. 2018)但它不能模拟特征不能相互交互的跨模态交互。
近年来,局部融合已经成为能够模拟时间依赖的跨模态相互作用的主流策略
(Zadeh et al. 2018a)提出了记忆融合网络,可以融合lstm的记忆,并由(Zadeh et al. 2018c)扩展,使用动态融合图(DFG)来融合特性。
本文的图融合网络与DFG的不同之处在于:1)使用内积作为边权重的一部分来估计相互作用之间的相似性;2)除了融合双峰和单峰相互关系,还融合任两个双峰相互关系,以获得更完整的三峰表示;3)分别确定顶点的重要性,首先获得每个层的输出,而不是直接添加所有顶点的加权信息。
张量融合也已成为一种新的趋势。(Zadeh et al. 2017)提出张量融合网络,采用多模态嵌入的外部产物进行融合,提高效率和减少冗余信息。
但它和它的改进们在融合前并没有明确地探索关联嵌入空间。因此,模态间隙仍然严重影响融合的效果。
对于模态翻译方法,多模态变换器(MulT) (Tsai et al. 2019a)使用定向成对跨模态注意将源模态转换为目标模态。此外,(Pham et al. 2019)提出的多模态循环翻译网络通过将编码器的输入(源模态)转换为解码器的输出(目标模态)。
MCTN使用编码器的输出作为源模态和目标模态的联合表示,而没有探索来自目标模态的信息,旨在解决模态损失问题。相比之下,本文解决了分布平移(全局对齐?)问题,并通过对抗训练将源模态的分布转换为目标处理模态来学习联合嵌入空间。然后使用目标和源模式的编码表示进行图融合。
方法
ARGF由两个阶段组成:联合嵌入空间学习阶段和图融合阶段。在第一阶段,通过对抗性框架学习所有模式的嵌入空间。
在第二阶段,利用编码器输出的表示来进行图融合
联合嵌入空间学习
三种模态作为输入:声音xa,语义xl,视觉xv
假设xl是目标模态,其他模态被称为源模态,p(xl)表示语言模态的先验数据分布,则有变换分布
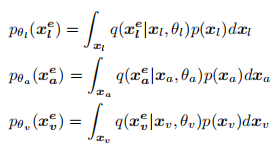
其中q就是编码器,一个深度神经网络,计算结果p是学习嵌入空间中的转换分布
通过优化θl、θv和θa,可以显式地将转换后的分布pθa(xea)和pθv(xev)映射到pθl(xel)。然而,不同模式的分布是非常复杂的,它们的性质也很不同,很难用简单的编码器网络来匹配的。
因此利用对抗性训练来为转换后的分布添加约束条件。定义一个鉴别器D,旨在将pθl(xel)归类为真,而pθa(xea)和pθv(xev)分类为假,而生成器(编码器Ea和Ev)试图欺骗鉴别器D,将pθv(xev)和pθa(xea)归类为真。生成器和鉴别器作为一个最小的相互竞争来学习联合嵌入空间。这里的损失函数可分为两部分:假对抗损失£fal和真对抗损失£tal,
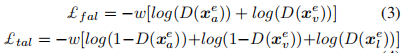
解码器通过重构损失学习
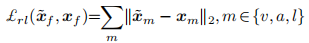
最后分类器通过分类损失学习
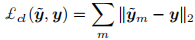
总结为
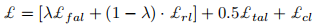
图融合网络
我们在本节中融合所有模态的编码表示来探索跨模态交互。假设多模态融合是处于多阶段的,考虑到保留所有n模态交互的需要,引入了层次神经网络图融合网络(GFN),依次对单峰、双峰和三峰交互进行建模。
GFN将每个交互视为一个顶点,并将相互作用顶点之间的相似性以及相互作用顶点的重要性视为边的权重,这在融合结构方面具有高度的可解释性和灵活性。(虽然不是纯粹的对象节点好歹能学一下图融合方法,但这异构图有点难顶)

第一层应用一个模态注意网络来处理每个顶点,并确定这些单模态交互的重要性,因为并不是所有的模态的贡献都是相等的。然后通过计算所有单峰顶点信息的加权平均值,得到最终的单峰交互。首先利用内积估计了第一层的每两个统一的单峰信息向量的相似性。可以认为两个信息向量越相似,它们的双峰相互作用就越不重要。
在第二层,即双峰动态学习层,使用MLP融合每个两个单峰顶点,得到每个双峰顶点:














 6409
6409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









