






 文章介绍了一种利用3DSR和深度感知离散自动编码器(DADA)进行三维表面异常检测的方法。方法通过在RGB和深度数据上训练,以捕捉深度属性,但面临数据量不足和处理速度慢的问题。文章还讨论了RGB网络在处理深度数据的局限性及改进策略。
文章介绍了一种利用3DSR和深度感知离散自动编码器(DADA)进行三维表面异常检测的方法。方法通过在RGB和深度数据上训练,以捕捉深度属性,但面临数据量不足和处理速度慢的问题。文章还讨论了RGB网络在处理深度数据的局限性及改进策略。
WCAV2024
摘要&引言
RGB骨干:某些表面异常仅在RGB中实际上仍然是看不见的,因此需要合并三维信息(确实重点在于“合并”,单纯看例子里的深度图片也看不出来异常在哪里,但是和rgb overlay之后就明显一些了)。在工业深度数据集上重新训练RGB骨干,这是为更快的密集输入处理而设计的,由于足够大的数据集的可用性有限而受到阻碍。
点云骨干:一般的点云数据集并不能很好地表示工业设置的深度外观分布(那是说点云训练的模型泛化性能差,和现实工业场景不兼容?还是说他们用的点云数据失了真,无法真实的表现现实场景?),从而导致了次优表示。此外,点云主干网大大减慢了处理速度,降低了该方法的实用性。
-》提速思路:直接把点云视作灰度图片然后用RGB训练的网络来推理(那不就丧失了3d性?)
-》-》这种改进的不足:在表示对于异常检测至关重要的深度属性方面表现不足。这是因为RGB图像处理网络通常没有被设计来捕获深度信息,它们优化的是处理颜色和纹理的能力。而深度图像的结构和分布可能与普通的RGB图像很不一样,所以直接应用RGB网络到深度数据可能会导致损失重要的深度信息,这对于准确检测异常是不利的。(不只是你这个rgb网络没有提取深度特征的能力啊,你这个输入都已经是灰度图了喂)
-》-》-》改进思路:把rgb网络再在深度数据上训练一下
-》-》-》-》不足:rgb预训练模型是在很大型数据集上训练的,现有的包括mvtec3d都不够量级
方法
提出了一种基于对偶子空间重投影(3DSR)的三维表面异常检测方法。输入的图像被编码到一个离散的特征空间中,然后由两个解码器重新投影到图像空间中。对象解码器和一般对象解码器分别重建无异常和异常外观。异常检测模块根据两个重投影的差异对潜在异常进行分割(
那不就是一种传统的分割模型吗,分出前景和背景)。3DSR的训练分为两个阶段。首先,在RGB和深度图像对上训练一种新的深度感知离散自动编码器(DADA),以学习RGB+3D深度数据的一般联合离散表示。
在第二阶段,将DADA集成到DSR [22]表面异常检测框架中,产生3DSR,然后在三维异常检测数据集[2,4]上进行训练。在第3.1节中,描述了所提出的具有深度感知能力的离散自动编码器(DADA)模块的体系结构。然后在第3.2节中描述了工业深度数据模拟过程。最后的3DSR表面异常检测管道详见第3.3节。
DADA
在深度图像中,即使是轻微的深度变化也可以为缺陷检测提供信息,因此表示TD的变化是至关重要的。
所以深度图像不像rgb,看不出来对象具体的纹理沟壑细节

但是通常大家用l2损失,对变化敏感,因此通常rgb的贡献更大,而深度数据基本0贡献(所以像CDO等有些算法才认为直接研究rgb比融合上3d效果更好吗?)
4通道的图片输入DADA后,RGB和深度信息由分组卷积层[8]确保RGB和深度特性不交互。这种通道级分离是防止在损失函数中的单一模态的压倒性影响。
最小化由于在低空间分辨率上离散化而导致的信息丢失的两阶段离散化架构:
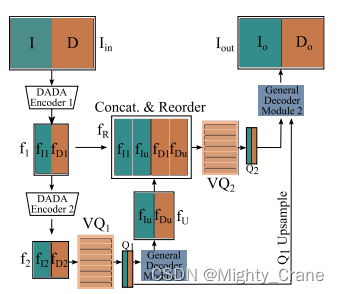
DADA编码器1:输入图像首先被编码器1处理,这个编码器将空间分辨率下采样4倍,产生特征集f1。这里的fI1代表RGB特征,fD1代表深度特征。
DADA编码器2:编码器1输出的特征被传递到编码器2,它进一步下采样,总共下采样8倍,产生新的特征集f2。
量化特征Q1:f2特征通过L2距离量化到码本VQ1的最近邻,得到量化特征Q1。
解码和上采样:量化特征Q1被输入到一个解码模块,这个模块将空间分辨率上采样2倍,得到fU。
特征重组和重排序:特征f1和fU被连接起来,并且通道重排序,以便将图像特征fI1和fIU以及深度特征fD1和fDu分组。这个重排序是必要的,因为它在解码器的分组卷积中保持了RGB和深度特征的分离。
再次量化:重新排序的特征fR被量化到最近的码本向量VQ2,产生Q2。
Q1上采样和拼接:量化特征Q1被上采样以匹配Q2的空间分辨率,然后Q1和Q2被输入到第二个解码模块。
输出重建:第二个解码模块输出RGB图像Io和深度Do的重建,这两个重建被连接起来作为最终输出Iout。
这个过程使用了一种改良的VQ-VAE(Vector Quantized-Variational AutoEncoder)损失函数来训练DADA。这个损失函数被修改以适应加入的深度信息。简而言之,这种架构设计用于处理和重建深度和RGB信息,通过精心设计的量化和解码过程来减少在处理中丢失重要的空间分辨率信息。
DDG
由于缺乏工业深度数据集,训练DADA需要模拟数据。一个有效的模拟过程需要考虑工业深度数据的关键特性。首先,物体深度可以从最近到最远连续变化。其次,小的凹痕和颠簸要么会导致RGB的显著强度变化,要么是完全看不见的,这取决于照明
(以能够在rgb而不只是深度通道上可见为标准,否则太假了吧,参考图1那种)。在深度上,这些微小的变化总是可以通过最小的局部深度值的改变来检测到。最后,一个深度图像的平均值可以有显著的变化。模拟数据必须捕捉工业图像中的局部变化和可变的平均物体深度。因此,模拟的深度图像生成过程被设计为明确地解决这些属性。模拟图像的核心生成器是Perlin噪声生成器[12],它产生各种局部平滑纹理,以良好地模拟深度的逐渐变化,解决了第一个特性。然后利用随机仿射变换适应Perlin噪声图像,模拟细微的局部变化和变化的平均目标距离。
从而DADA的训练是rgb和深度图像对。rgb图像来自典中典imagenet,深度图像是与rgb无关的模拟生成得到
3d异常检测流水线
在第二阶段,采用DSR [22]作为判别异常检测框架。DSR用于RGB表面异常检测的VQ-VAE-2 [13]网络被DADA取代,经过预先训练,从3D和RGB数据中提取信息表示。此外,DADA的矢量量化特征空间可以实现有效的模拟异常采样。3DSR的体系结构如图5所示
编码和量化(DADA编码器):图像I和深度D输入到DADA编码器,提取特征并量化得到Q1和Q2。
异常生成(仅训练时):在训练过程中,Q1和Q2通过异常生成过程被修改,产生含有模拟特征级异常的Q1A和Q2A。
子空间限制模块:Q1A和Q2A接着输入子空间限制模块,该模块尝试将提取的特征恢复到无异常的表示Q1S和Q2S。
对象特定解码器:对象特定解码器被训练以从重建的特征Q1S和Q2S重建无异常的外观。
预训练的通用外观解码器:通用外观解码器在训练时从Q1A和Q2A重建异常外观IG和DG,或在推断时从Q1和Q2重建。
拼接和输入异常检测模块:然后,IG、DG、IS和DS被拼接并输入异常检测模块。
异常检测模块:异常检测模块被训练在训练期间定位模拟的异常,在测试时定位真实的异常。它直接输出异常分割掩码Mout,并使用Focal损失进行训练。
异常得分估计:通过使用高斯滤波平滑Mout,然后取平滑掩码的最大值来估计图像级异常得分。
训练时异常生成:异常通过修改量化的特征图Q1和Q2生成。首先生成异常映射M,通过阈值处理和二值化一个Perlin噪声图来生成。M被调整大小以适应Q1和Q2的空间维度。Q1和Q2中对应于M的正值区域的特征向量被随机抽样自码本VQ1和VQ2中的特征向量所替换,生成包含模拟异常的修改后特征图Q1A和Q2A。
整个过程中,蓝色标记的步骤仅在训练时进行,橙色标记的步骤仅在推断时进行。红色标记的是可训练的模块。这个复杂的过程使得系统能够在训练期间学习识别和重建异常,而在推断期间快速有效地检测新的异常。















 220
220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









