







主要作用: 加入非线性因素,弥补线性模型表达不足的缺陷
Sigmoid函数
σ
(
x
)
=
1
1
+
e
−
x
\sigma(x) = \frac{1}{1 + e^{-x}}
σ(x)=1+e−x1
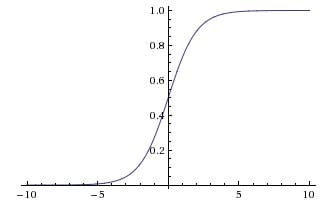
随着
x
x
x 的趋近正/负无穷,
y
y
y 对应的值越来越接近 +1/-1,趋近饱和
因此当
x
x
x = 100 和
x
x
x = 1000 的差别不大,这个特性丢掉了
x
x
x = 1000 的信息
Tanh函数
t
a
n
h
(
x
)
=
2
σ
(
2
x
)
−
1
tanh(x) = 2 \sigma(2x) - 1
tanh(x)=2σ(2x)−1
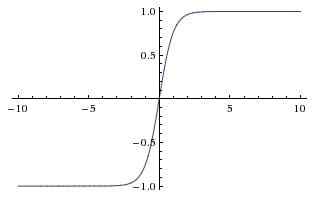
对Sigmoid函数的值域升级版,值域为(-1, 1)
ReLU函数
R
e
L
U
(
x
)
=
m
a
x
(
0
,
x
)
ReLU(x) = max(0, x)
ReLU(x)=max(0,x)
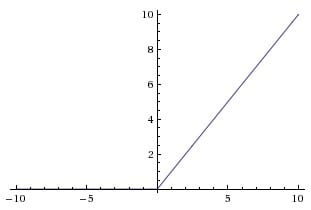
大于 0 的一律留下,否则一律为 0,这种对正向信号的重视,忽略负向信号的特性,与人类神经元细胞信号的反应机制非常相似
变式
1.Softplus: 对负信号不是全部拒绝,函数更为平滑,但计算量巨大
2.Noisy relus: 其中x加入了一个高斯分布噪声
3.Leaky relus: 在ReLU的基础上,保留一部分负值,让x为负时乘以0.01,对负信号不是一味拒绝,而是缩小
4.Elus: 对x为负时,做了更加复杂的变化
总结:
Tanh函数:特征相差明显
Sigmoid函数:特征相差复杂,但是没有明显区别
ReLU函数:处理后的数据具有很好的稀疏疏性(大多数元素值为0),近似程度地最大保留数据特征
实际上,神经网络训练过程中,就是不断尝试如何用一个稀疏矩阵来表达数据特征,稀疏矩阵可以使神经网络在迭代运算中得到又快又好的效果,因此ReLU函数被作为激活函数有着更广泛的应用















 1396
1396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









