









 本文介绍了如何利用全连接线性BP网络的增强学习模型训练一个智能体,使其在经典游戏坦克大战中自主对敌。模型设计包括复杂option的抽象与转移,通过神经网络表示,最终实现人机共存的游戏体验。
本文介绍了如何利用全连接线性BP网络的增强学习模型训练一个智能体,使其在经典游戏坦克大战中自主对敌。模型设计包括复杂option的抽象与转移,通过神经网络表示,最终实现人机共存的游戏体验。
这个项目是基于一个人工智能算法(基于全连接线性BP网络的增强学习模型)代理玩经典游戏坦克大战。 在个游戏中,机器控制的坦克主要目标是射击敌方坦克并保卫自家的根据地。
游戏中坦克的动作空间有两个维度组成:
• 移动方向:【上、下、左、右】
• 动作:【射击】
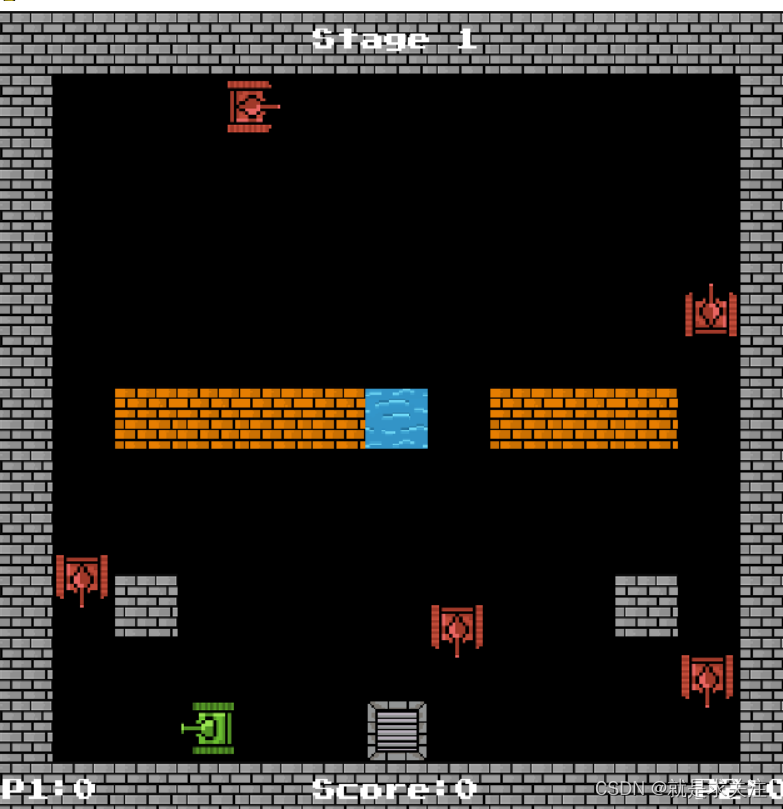
界面结构如下所示:
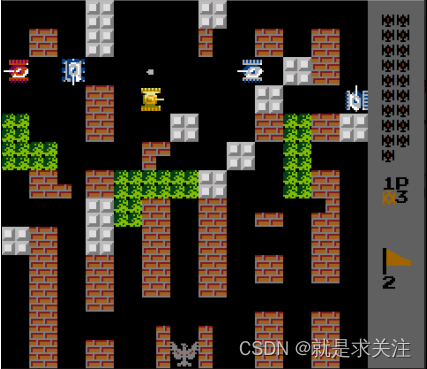
输入的特征:坦克执行以下操作的动作,特征尺度大小:200
• 子弹位置、方向
• 敌人的位置、方向和类型
• 邻近的地图信息
• 自家坦克和敌人坦克的距离
•敌人坦克到基地的距离
将每个原子动作作为一个独立的option,除了原先动作集中的原子动作外,根据学习任务另外抽象出若干个复杂option,并将这些option作为一种特殊的“动作”加入 到 原 来 的 动 作 集 中,option 间 的 转 移 通 过BP神经网络来表示。详见代码。设计的模型结构如下所示:
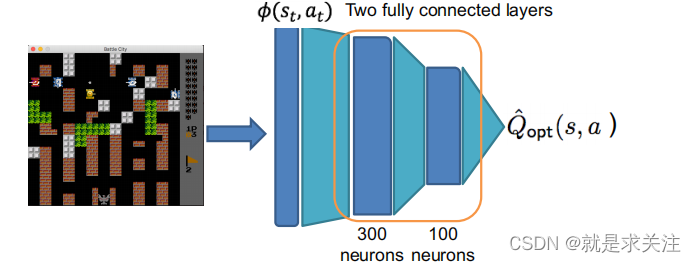
训练过程如下:
最终实现的坦克大战,可以实现人为操作和机器自动运行。
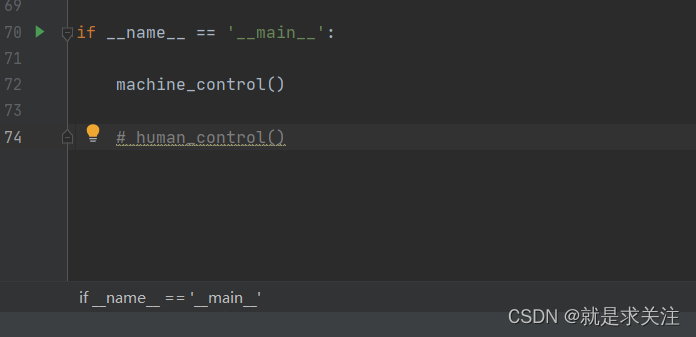
完成注释下图代码即可
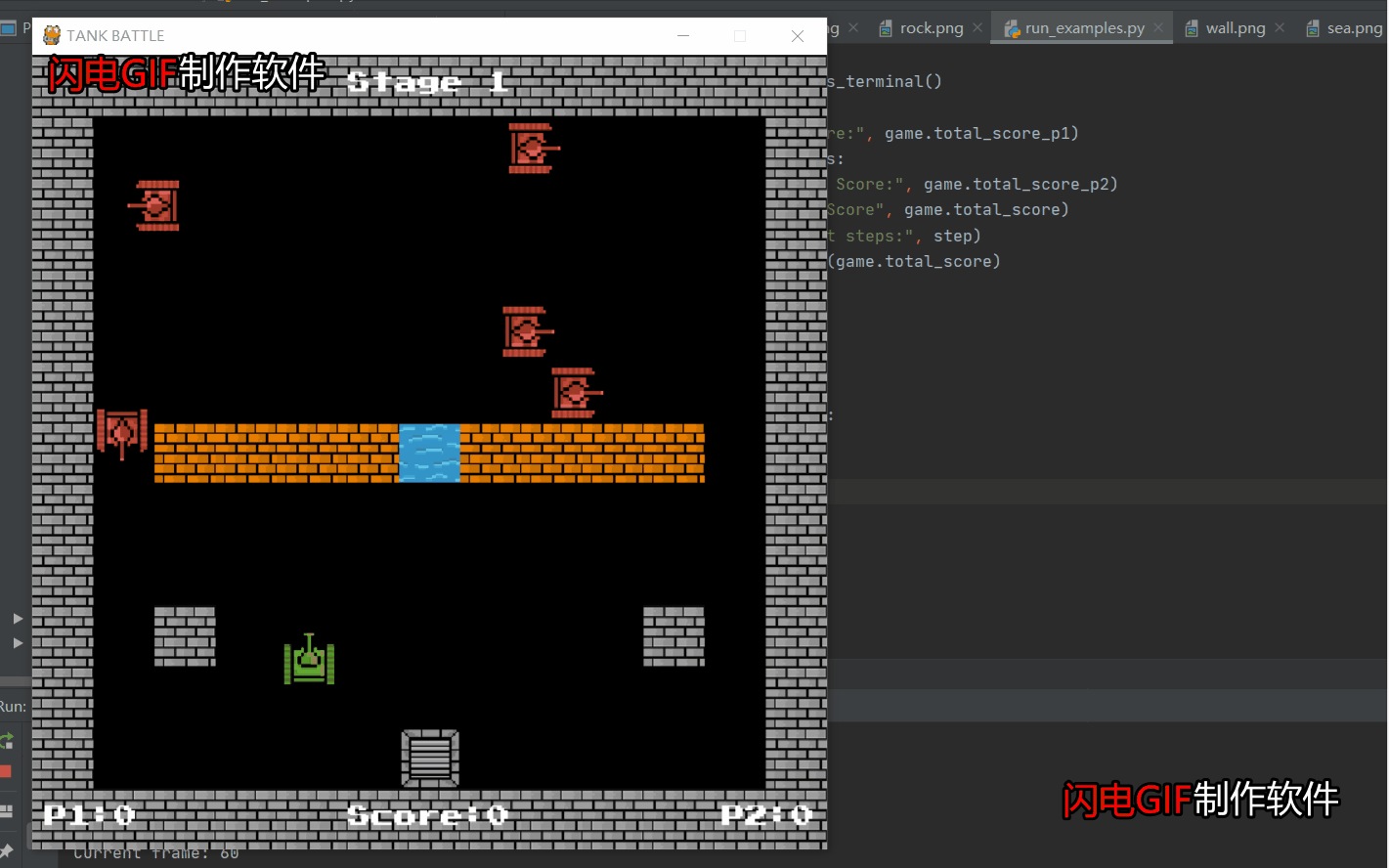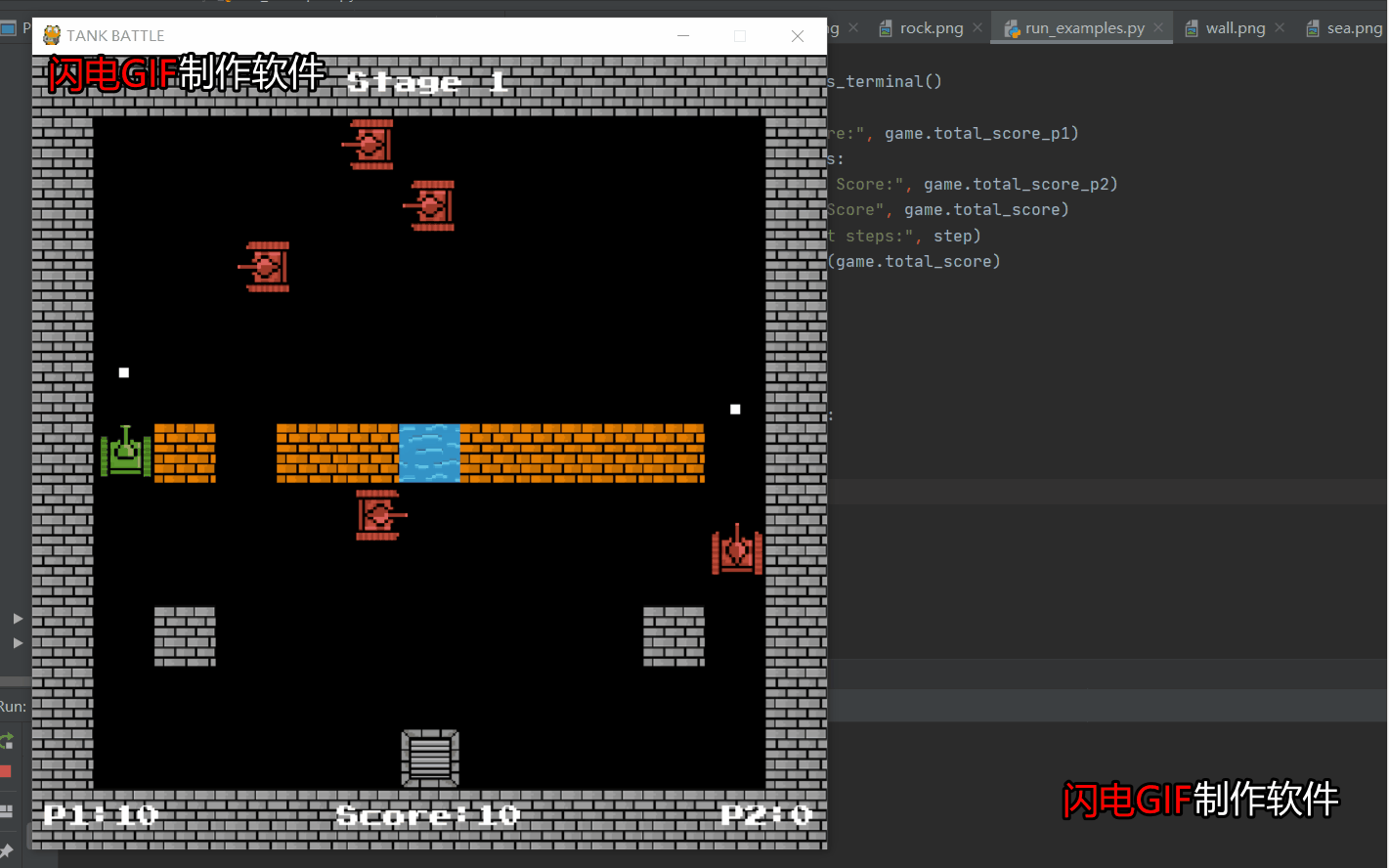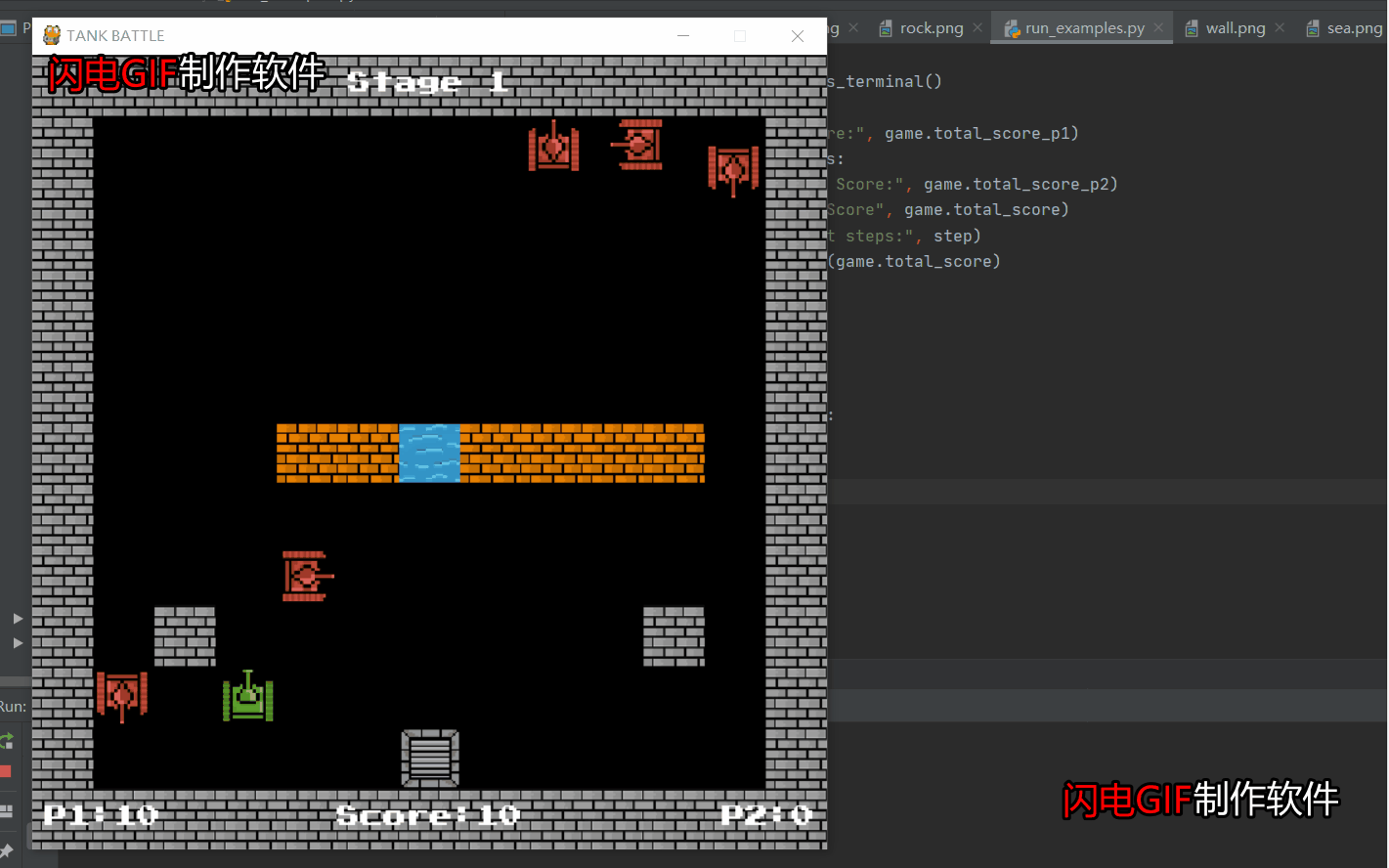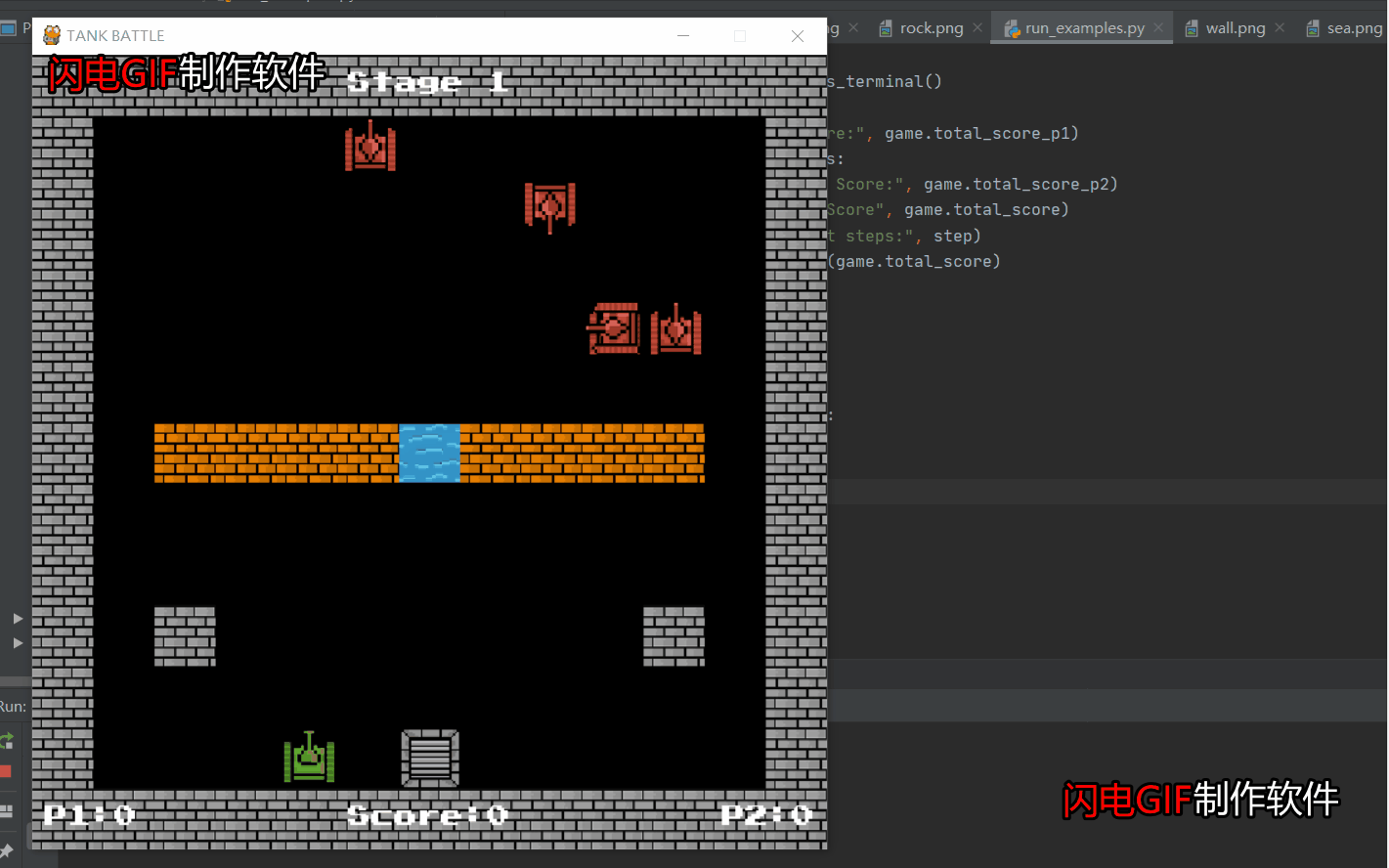
深度强化学习在游戏领域中有着广泛的应用,使用深度强化学习方法训练的智能体能在一些游戏上有接近人类玩家 的表现。本设计并实现了一个坦克对战游戏环境,并将深度强化学习应用到游戏中,使用 BP强化学习
练智能体,使智 能体程序能在游戏中获胜。
全部代码下载连接:


















 1100
1100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











