







PointNet的问题:
对每个点做 MLP 低维到高维的映射,把所有点映射到高维的特征通过 Max pooling
结合到一起,本质上来说,要么对一个点做操作,要么对所有点做操作,实际上没有局部的概念 ( loal context ) ,比较难对精细的特征做学习,在分割上有局限性
另外,因为没有 local context ,在平移不变性上也有局限性。(xyz)对点云数据做平移 所有的数据都不一样了,导致所有的特征,全局特征都不一样了,分类也不一样
PointNet++ 提出了什么问题?
- how to generate the partitioning of the point set
- how to abstract sets of points or local features through a local feature learner
PointNet++ 怎么解决的问题
1.FPS
2.Set Abstraction Levels

核心思想
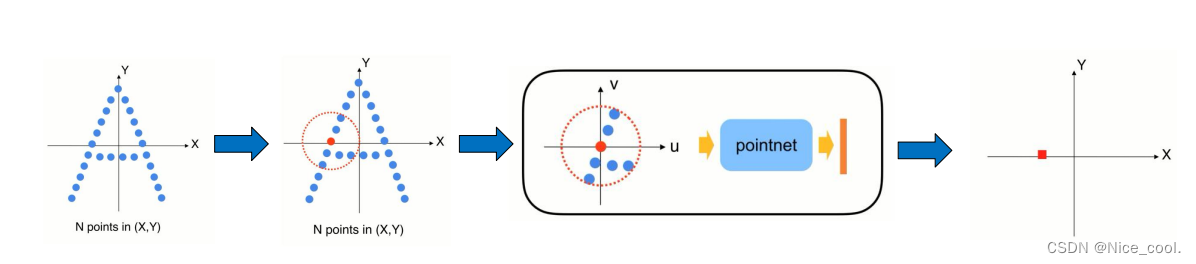
- 先把局部的点转换到一个局部坐标系中
- 在局部中使用pointnet 来提取特征
- 提取完特征以后会得到一个新的点,F (x,y )在整个点云中的位置 在欧氏空间中,还有个向量特征F(高纬的特征空间),代表小区域的几何形状
- 重复这个操作就会得到一组新的点,在数量上少于原先的点,但是新的每个点代表了它周围一个区域的几何特点
整体网络结构
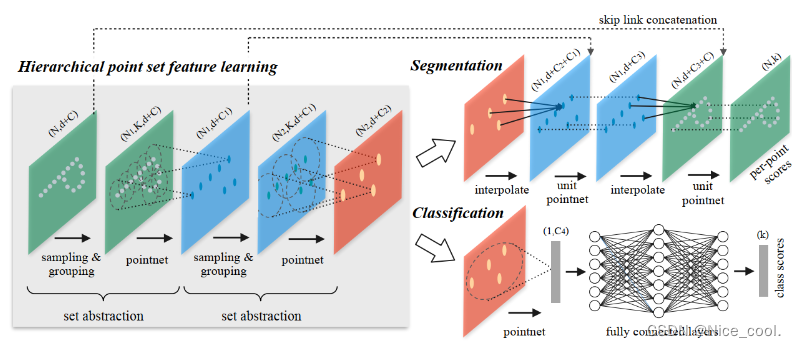
Hierarchical point set feature learning(层次化特征学习)
PointNet++的网络大体是 encoder-decoder 结构
encoder 为降采样过程,通过多个set abstraction结构实现多层次的降采样,得到不同规模的 point-wise feature,最后一个 set abstraction 输出可以认为是 global feature
set abstraction:
set abstraction 由 sampling,grouping,pointnet 三个模块构成
input: N × ( d + C ) ,N points with d-dim coordinates and C-dim point feature
output: N ′ × ( d + C ′ )
Encoder
sampling layer (对输入点进行采样,选出若干个中心点)
使用FPS(最远点采样)对点集进行降采样,将输入点集从规模A降到更小的规模B 。
FPS可以理解成是使得采样的各个点之间尽可能远,这种采样的好处是可以降采样结果会比较均匀。
具体过程如下:
随机选择一个点作为初始点作为已选择采样点,计算未选择采样点集中每个点与已选择采样点集之间的距离 distance,将距离最大的那个点加入已选择采样点集,然后更新distance,一直循环迭代下去,直至获得了目标数量的采样点。
input: N × ( d + C )
output: N ′ × d
这里因为是局部区域的质心,所以N‘就代表了N’个局部区域的N‘个质心
1.在质心数量相同的情况下,用FPS去采样,比随机采样能够更好的覆盖整个点集
2.和CNN去扫描向量空间的数据空间分布来讲, FPS产生的感受野是相对独立,因为是最远点。
def farthest_point_sample(xyz, npoint):
"""
Input:
xyz: pointcloud data, [B, N, 3]
npoint: number of samples
Return:
centroids: sampled pointcloud index, [B, npoint, 3]
"""
device = xyz.device
B, N, C = xyz.shape
centroids = torch.zeros(B, npoint, dtype=torch.long).to(device) # 采样点矩阵(B, npoint)
distance = torch.ones(B, N).to(device) * 1e10 # 采样点到所有点距离(B, N)
farthest = torch.randint(0, N, (B,), dtype=torch.long).to(device) # 最远点,初试时随机选择一点点
batch_indices = torch.arange(B, dtype=torch.long).to(device) # batch_size 数组
for i in range(npoint):
centroids[:, i] = farthest # 更新第i个最远点
centroid = xyz[batch_indices, farthest, :].view(B, 1, 3) # 取出这个最远点的xyz坐标
dist = torch.sum((xyz - centroid) ** 2, -1) # 计算点集中的所有点到这个最远点的欧式距离
mask = dist < distance
distance[mask] = dist[mask] # 更新distances,记录样本中每个点距离所有已出现的采样点的最小距离
farthest = torch.max(distance, -1)[1] # 返回最远点索引
return centroids
grouping (利用上一步得到的中心点将点集划分成若干个区域)
对每个中心点找它的邻域点,形成子点集。注意子点集之间可以存在overlap,并且每个子点集的点数目不一定相等。文章提出了两种方案,一是 ball query,在尺度空间下,给定半径k,将距离在k以内的点都加入点集。这种方法的好处是固定了邻域尺度,能够更好的提取局部空间的特征(generalizable),适用于语义分割任务。第二种方案是K近邻,这种方案固定了点集的数量。本文更偏好 ball query 方法
input: N × ( d + C ) , N ′ × d
output: groups of point with size of N ′ × K × ( d + C )
each group corresponds to a local region
def square_distance(src, dst):
"""
Calculate Euclid distance between each two points.
src^T * dst = xn * xm + yn * ym + zn * zm;
sum(src^2, dim=-1) = xn*xn + yn*yn + zn*zn;
sum(dst^2, dim=-1) = xm*xm + ym*ym + zm*zm;
dist = (xn - xm)^2 + (yn - ym)^2 + (zn - zm)^2
= sum(src**2,dim=-1)+sum(dst**2,dim=-1)-2*src^T*dst
Input:
src: source points, [B, N, C]
dst: target points, [B, M, C]
Output:
dist: per-point square distance, [B, N, M]
"""
B, N, _ = src.shape
_, M, _ = dst.shape
dist = -2 * torch.matmul(src, dst.permute(0, 2, 1))
dist += torch.sum(src ** 2, -1).view(B, N, 1)
dist += torch.sum(dst ** 2, -1).view(B, 1, M)
return dist
def query_ball_point(radius, nsample, xyz, new_xyz):
"""
Input:
radius: local region radius
nsample: max sample number in local region
xyz: all points, [B, N, 3]
new_xyz: query points, [B, S, 3]
Return:
group_idx: grouped points index, [B, S, nsample]
"""
device = xyz.device
B, N, C = xyz.shape
_, S, _ = new_xyz.shape
group_idx = torch.arange(N, dtype=torch.long).to(device).view(1, 1, N).repeat([B, S, 1])
sqrdists = square_distance(new_xyz, xyz)
group_idx[sqrdists > radius ** 2] = N
group_idx = group_idx.sort(dim=-1)[0][:, :, :nsample]
group_first = group_idx[:, :, 0].view(B, S, 1).repeat([1, 1, nsample])
mask = group_idx == N
group_idx[mask] = group_first[mask]
return group_idx
PointNet (对上述得到的每个区域进行编码,变成特征向量)
class PointNetSetAbstraction(nn.Module):
def __init__(self, npoint, radius, nsample, in_channel, mlp, group_all):
super(PointNetSetAbstraction, self).__init__()
self.npoint = npoint
self.radius = radius
self.nsample = nsample
self.mlp_convs = nn.ModuleList()
self.mlp_bns = nn.ModuleList()
last_channel = in_channel
for out_channel in mlp:
self.mlp_convs.append(nn.Conv2d(last_channel, out_channel, 1))
self.mlp_bns.append(nn.BatchNorm2d(out_channel))
last_channel = out_channel
self.group_all = group_all
def forward(self, xyz, points):
"""
Input:
xyz: input points position data, [B, C, N]
points: input points data, [B, D, N]
Return:
new_xyz: sampled points position data, [B, C, S]
new_points_concat: sample points feature data, [B, D', S]
"""
xyz = xyz.permute(0, 2, 1)
if points is not None:
points = points.permute(0, 2, 1)
if self.group_all:
new_xyz, new_points = sample_and_group_all(xyz, points)
else:
new_xyz, new_points = sample_and_group(self.npoint, self.radius, self.nsample, xyz, points)
# new_xyz: sampled points position data, [B, npoint, C]
# new_points: sampled points data, [B, npoint, nsample, C+D]
new_points = new_points.permute(0, 3, 2, 1) # [B, C+D, nsample,npoint]
for i, conv in enumerate(self.mlp_convs):
bn = self.mlp_bns[i]
new_points = F.relu(bn(conv(new_points)))
new_points = torch.max(new_points, 2)[0]
new_xyz = new_xyz.permute(0, 2, 1)
return new_xyz, new_points
Decodaer
分类
重复 set abstraction 的过程,实现一个多级的网络, 使得点的数量越来越少,但是每个点代表的区域以及感受野,越来越大,这个cnn的概念很类似,最后把点做一个pooling 得到 globle feature,送入几层全连接网络,最后通过一个softmax分类。
分割
设计了一种反向插值的方法来实现上采样的结构,通过反向插值和skip connection来获得discriminative point-wise feature
插值
对于P2中的每个点x,找在原始点云坐标空间下, P2中与其最接近的K个点 [x1,x2,x3…xk],将 [x1,x2,x3…xk] 的特征加权求和,得到x的特征。其中这个权重是与x和 [x1,x2,x3…xk] 的距离成反向相关的,意思就是距离越远的点,对x特征的贡献程度越小
PointNet++ 的问题
non-uniform sampling density
在稀疏点云局部邻域训练可能不能很好挖掘点云的局部结构
PointNet++ 代码
class pointnet2_seg_ssg(nn.Module):
def __init__(self, in_channels, nclasses):
super(pointnet2_seg_ssg, self).__init__()
self.pt_sa1 = PointNet_SA_Module(M=512, radius=0.2, K=32, in_channels=in_channels, mlp=[64, 64, 128], group_all=False)
self.pt_sa2 = PointNet_SA_Module(M=128, radius=0.4, K=64, in_channels=131, mlp=[128, 128, 256], group_all=False)
self.pt_sa3 = PointNet_SA_Module(M=None, radius=None, K=None, in_channels=259, mlp=[256, 512, 1024], group_all=True)
self.pt_fp1 = PointNet_FP_Module(in_channels=1024+256, mlp=[256, 256], bn=True)
self.pt_fp2 = PointNet_FP_Module(in_channels=256 + 128, mlp=[256, 128], bn=True)
self.pt_fp3 = PointNet_FP_Module(in_channels=128 + 6, mlp=[128, 128, 128], bn=True)
self.conv1 = nn.Conv1d(128, 128, 1, stride=1, bias=False)
self.bn1 = nn.BatchNorm1d(128)
self.dropout1 = nn.Dropout(0.5)
self.cls = nn.Conv1d(128, nclasses, 1, stride=1)
def forward(self, l0_xyz, l0_points):
l1_xyz, l1_points = self.pt_sa1(l0_xyz, l0_points)
l2_xyz, l2_points = self.pt_sa2(l1_xyz, l1_points)
l3_xyz, l3_points = self.pt_sa3(l2_xyz, l2_points)
l2_points = self.pt_fp1(l2_xyz, l3_xyz, l2_points, l3_points)
l1_points = self.pt_fp2(l1_xyz, l2_xyz, l1_points, l2_points)
l0_points = self.pt_fp3(l0_xyz, l1_xyz, torch.cat([l0_points, l0_xyz], dim=-1), l1_points)
net = l0_points.permute(0, 2, 1).contiguous()
net = self.dropout1(F.relu(self.bn1(self.conv1(net))))
net = self.cls(net)
return net
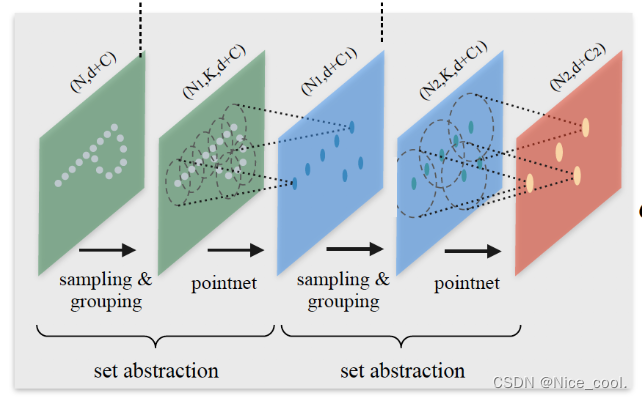
set abstraction
class PointNet_SA_Module(nn.Module):
def __init__(self, M, radius, K, in_channels, mlp, group_all, bn=True, pooling='max', use_xyz=True):
super(PointNet_SA_Module, self).__init__()
self.M = M
self.radius = radius
self.K = K
self.in_channels = in_channels
self.mlp = mlp
self.group_all = group_all
self.bn = bn
self.pooling = pooling
self.use_xyz = use_xyz
self.backbone = nn.Sequential()
for i, out_channels in enumerate(mlp):
self.backbone.add_module('Conv{}'.format(i),
nn.Conv2d(in_channels, out_channels, 1,
stride=1, padding=0, bias=False))
if bn:
self.backbone.add_module('Bn{}'.format(i),
nn.BatchNorm2d(out_channels))
self.backbone.add_module('Relu{}'.format(i), nn.ReLU())
in_channels = out_channels
def forward(self, xyz, points):
if self.group_all:
new_xyz, new_points, grouped_inds, grouped_xyz = sample_and_group_all(xyz, points, self.use_xyz)
else:
new_xyz, new_points, grouped_inds, grouped_xyz = sample_and_group(xyz=xyz,
points=points,
M=self.M,
radius=self.radius,
K=self.K,
use_xyz=self.use_xyz)
new_points = self.backbone(new_points.permute(0, 3, 2, 1).contiguous())
if self.pooling == 'avg':
new_points = torch.mean(new_points, dim=2)
else:
new_points = torch.max(new_points, dim=2)[0]
new_points = new_points.permute(0, 2, 1).contiguous()
return new_xyz, new_points
PointNet++ 是有 3次 set abstraction 操作的:
N是点的数量,
M表示中心点的数量,
K表示每个中心点的球邻域内选择的点的数量,
C0是特征维度
第一次: (B, N, C0) -> (B, M1, C1) , C0 = 3 或 C0=6(加上normal信息)
第二次: (B, M1, C1+3) -> (B, M2, C2)
第三次: (B, M2, C2+3) -> (B, C3)
C1和C2后面都加了3, 这是在学到特征的基础上又加了位置信息(x, y, z),
重新作为新的特征来送入PointNet网络
对应代码
self.pt_sa1 = PointNet_SA_Module(M=512, radius=0.2, K=32, in_channels=in_channels, mlp=[64, 64, 128], group_all=False)
self.pt_sa2 = PointNet_SA_Module(M=128, radius=0.4, K=64, in_channels=131, mlp=[128, 128, 256], group_all=False)
self.pt_sa3 = PointNet_SA_Module(M=None, radius=None, K=None, in_channels=259, mlp=[256, 512, 1024], group_all=True)
l1_xyz, l1_points = self.pt_sa1(l0_xyz, l0_points)
l2_xyz, l2_points = self.pt_sa2(l1_xyz, l1_points)
l3_xyz, l3_points = self.pt_sa3(l2_xyz, l2_points)
网络代码
if __name__ == '__main__':
in_channels = 6
n_classes = 50
l0_xyz = torch.randn(4, 1024, 3)
l0_points = torch.randn(4, 1024, 3)
model = pointnet2_seg_ssg(in_channels, n_classes)
net = model(l0_xyz, l0_points)
print(net.shape)
print(net)















 488
488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









