







基于氨基酸序列和对应活性值的条件对抗生成网络(Cgan)
目的:根据氨基酸序列和某值(可以是任意的长度或者数值)进行训练,最后根据一个噪声和条件标签生成相关的氨基酸序列
数据准备工作
在蛋白质网站uniport根据 胶原蛋白某发挥作用的结构域氨基酸序列进行blast,操作获取到相关同源性序列并且进行收集,并且收集其对应的稳定性,具体数据格式如下图

代码工作开始
导入相关的库包
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
import torchvision
from torchvision import transforms
print(torch.__version__)
数据准备
import pandas as pd
data = pd.read_csv('../data/8E_double_dubplcate_.csv')
data = data.dropna()
data = data[data['A4']>0.65]
data
编写一个自定义的dataset类处理我们的序列数据
import torch
import torch.nn.functional as F
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self, sequences, labels,amino_acid_table):
self.sequences = sequences
self.labels = labels
self.table = amino_acid_table
def __len__(self):
return len(self.sequences)
def __getitem__(self, index):
sequence = self.sequences[index]
label = self.labels[index]
# 将label转换为32位浮点型张量
label = torch.tensor(label, dtype=torch.float32)
# 将氨基酸序列进行One-hot编码
encoded_sequence = torch.zeros(len(sequence), 20) # 初始化编码后的序列
# 根据氨基酸序列中的每个氨基酸位置,将对应位置设置为1
for i, amino_acid in enumerate(sequence):
amino_acid_index = self._amino_acid_to_index(amino_acid)
encoded_sequence[i, amino_acid_index] = 1
return encoded_sequence, label # 在此处label作为氨基酸的区分标记把
def _amino_acid_to_index(self,amino_acid):
amino_acids = self.table # 20种常见氨基酸
return amino_acids.index(amino_acid)
其中我们对于我输入进行来的氨基酸序列数据采用one-hot编码方式进行序列矩阵化,
在这里我们需要对输入的实际氨基酸序列 进行一个剪裁,因为我们必须确保每一条序列进来的长度是一样的,这里由于胶原蛋白β螺旋中的结构域氨基酸序列56个氨基酸长度的就能确定整个胶原蛋白的稳定性,所以这里我们采用截断操作,使得每个氨基酸序列最长等于56个氨基酸。(数据处理操作过程省略,)
对实际数据进行实例化
from torch.utils.data import DataLoader
import pandas as pd
import json
with open('../config/amino_acids_table.json', 'r') as f:
content = f.read()
table = json.loads(content)
print('table idnex',table)
amino_acids_table = table['amino_acids_table']
print("amino_acids_table is same as training:",amino_acids_table)
sequences = data['seqs'].values
labels = data['A4']
# 打印训练集和测试集的大小
print("训练集大小:", sequences.shape, labels.shape)
# 创建自定义数据集实例
train_set = MyDataset(sequences, labels,amino_acids_table)
# 创建数据加载器
train_loader = DataLoader(train_set, batch_size=8, shuffle=True)
output:
后续我们需要根据amino_acids_table的氨基酸index进行氨基酸序列还原
table idnex {‘amino_acids_table’: ‘CTDLQGWMAFHKYPINRSVE’}
amino_acids_table is same as training: CTDLQGWMAFHKYPINRSVE
训练集大小: (4900,) (4900,)
定义生成器和判别器
# 定义生成器
class Generator(nn.Module):
def __init__(self, ):
super().__init__()
# seqs torch.Size([8, 56, 20])
self.noise = nn.Linear(100,56*20)
# a4 torch.Size([8])
self.fc_a4 = nn.Linear(1,56*20)
# learning netword
self.rnn1 = nn.GRU(input_size=56 * 20 *2, hidden_size=512, num_layers=3, batch_first=True)
self.rnn2 = nn.GRU(input_size=512, hidden_size=128, num_layers=3, batch_first=True)
self.rnn3 = nn.GRU(input_size=128, hidden_size=512, num_layers=3, batch_first=True)
self.fc_out = nn.Linear(512, 56 * 20)
self.softmax = nn.Softmax(dim=2)
def forward(self, seq, a4):
# nosie
x = torch.relu(self.noise(seq))
# x = x.view(-1,56,20)
# a4
a4 = a4.unsqueeze(1)
y = torch.relu(self.fc_a4(a4))
# y = y.view(-1,56,20)
# print("noise shape",x.shape)
# print("a4 shape",y.shape)
feature = torch.cat([x, y], dim=1)
# print("after cat feature shape",feature.shape)
out, _ = self.rnn1(feature)
out, _ = self.rnn2(out)
out, _ = self.rnn3(out)
out = self.fc_out(out) # out shape == [8,1120]
# print("out1 shape",out.shape )
out = out.view(-1,56,20) # out shape == [8,56,29]
# print('out after view shape',out.shape)
out = self.softmax(out) # out shape == [8,56,20] 最后以为进行了softmax
# print("out2 shape",out.shape )
# print('out after view shape',out.shape)
return out
# 定义判别器
class Discriminator(nn.Module):
def __init__(self, seq_dim=56*2 ,a4_dim=1, hid_dim=128):
super().__init__()
self.label = nn.Linear(1,56*20)
self.main = nn.Sequential(
nn.Linear(56*20*2,512),
nn.BatchNorm1d(512), # 添加批量归一化层
nn.LeakyReLU(),#leakyRelu() 再负值的是时候保留一定的梯度
nn.Dropout(0.25),
nn.Linear(512,1024),
nn.BatchNorm1d(1024), # 添加批量归一化层
nn.LeakyReLU(),# leakyRelu() f(x),x>0 输出x ,X<0,输出a*x,a是一个很小的斜率值,比如0.1
nn.Dropout(0.25),
nn.Linear(1024,512),
nn.BatchNorm1d(512), # 添加批量归一化层
nn.LeakyReLU(),
nn.Dropout(0.25),
nn.Linear(512,1), # 输出到1,然后激活后 是 0-1之间的一个概率
nn.Sigmoid()
)
# self.conv1 = nn.Conv1d(20, 64, kernel_size=3, stride=1)
# self.conv2 = nn.Conv1d(64, 10, kernel_size=3, stride=1)
# self.maxpool = nn.MaxPool1d(kernel_size=2, stride=1)
# self.fc = nn.Linear(10 * 108, 1)
# self.sigmoid = nn.Sigmoid()
def forward(self, seq, a4):
# seq 进来的是 torch.size([16,56,20])
# a4
a4 = a4.unsqueeze(1)
y = torch.relu(self.label(a4))
y = y.view(-1,56,20)
# print("seq shape",seq.shape) # torch.Size([16, 56, 20])
# print("a4 shape",y.shape) # torch.Size([16, 56, 20])
feature = torch.cat([seq, y], dim=1) # torch.Size([16, 112, 20])
# print("feature shape before view ==>",feature.shape)
feature = feature.view(-1,112*20)
# Apply convolutional layers
# feature = feature.permute(0,2,1)
# x = self.conv1(feature)
# x = self.conv2(x)
out = self.main(feature)
# print(out.shape)
# out = np.argmax(out.detach().numpy(),axis=0) # 后续采用
return out
损失函数的选择
在设定损失函数的同时我们要根据我们的需求进行选择,首先我们要求生成的序列跟原来指定稳定性的序列 关键节点需要一致,同时我们需要氨基酸序列尽可能多的多样化
即 确保生成的氨基酸序列确实有如实的稳定性的同时 且具有一定的多样性可能。所以选择wgans中的损失函数,其确保固定氨基酸之间的距离能够足够相似的同时整体结构不改变。
class Wgansloss(nn.Module):
def __init__(self):
super(Wgansloss, self).__init__()
def forward(self, real_predictions, fake_predictions):
# 自定义损失计算方式
real_loss = -torch.mean(real_predictions) # 最大化真实样本的平均预测值
fake_loss = torch.mean(fake_predictions) # 最小化生成样本的平均预测值
loss = real_loss + fake_loss # 真实样本的平均预测值减去生成样本的平均预测值
return loss
intel One-API 组件中的 AI tooklist
在这里我们需要使用inter 公司架构的one-API架构,实验一次代码编写,可以在任意的基础架构上进行运行。
OneAPI 旨在提供一个适用于各类计算架构的统一编程模型和应用程序接口。也就是说,应用程序的开发者只需要开发一次代码,就可以让代码在跨平台的异构系统上执行,底层的硬件架构可以是CPU、GPU、FPGA、神经网络处理器,或者其他针对不同应用的硬件加速器等等。
这种演化的过程中不可避免的造成了软、硬件体系的蓬勃发展,市场上架构各异的硬件芯片,纷繁多样的语言、各式各样的商业模式都是其推动的直接产物,然而也正是这些多样化、多元化的环境使得跨架构的系统设计变得越来越复杂、愈来愈让人难以理解。
在这种应用环境下,开发者在集成多种架构芯片、系统阶段性升级或改造时将必须面对如下挑战:
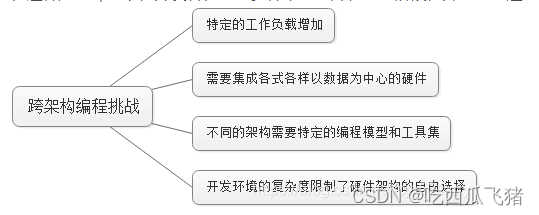
而Intel oneAPI 正是为解决这些问题而诞生,简单来说它是一个跨行业、开放、标准统一、简化的编程模型,旨在促进社区和行业合作、简化跨多架构的开发过程、解决跨体系及供应商代码重用,为跨 CPU、GPU、FPGA、专用加速器的开发者提供统一的开发体验
intel oneAPI 赋能 AI
在 intel oneAPI架构下,有我们训练神经网络的所需要的集成工具库,AI-tooklist 其底层架构支持 AI训练中间件,pytorch、tensorflow、X-net、numpy、等等相关工具
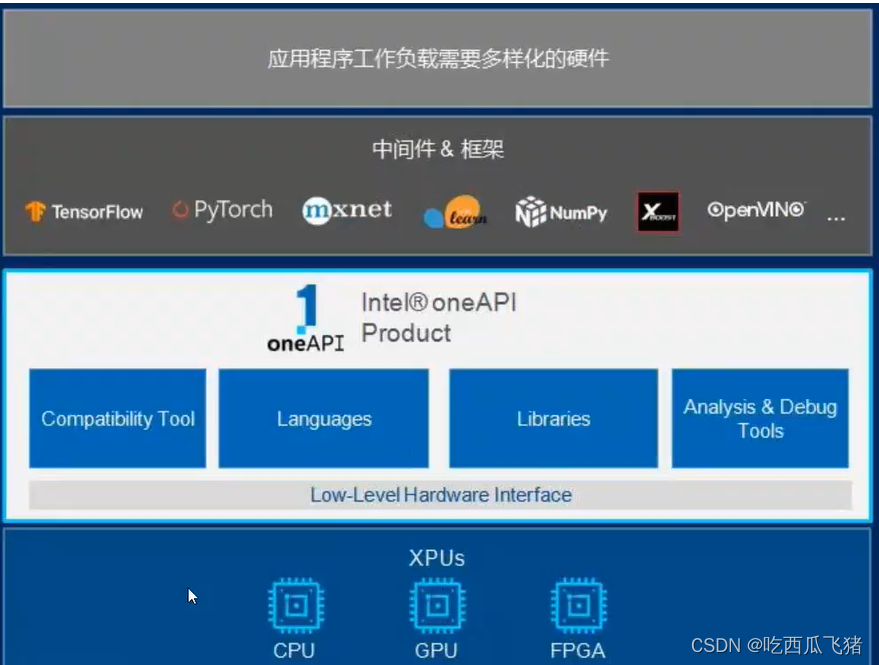
在这里我们使用AI-tooklist进行pytorch深度学习框架的加速,同时构建我们自己one-API应用,以支持在任何底层架构上使用,在其他系统上我们可以基于任意的 XPUs进行运算和运行。

定义解码函数
解码函数将生成的数据矩阵重新根绝amino_acid_table 进行还原\
def generator_seq(model, test_input,label,table):
# np.squeeze 把维度为1的值去掉
prediction_seq = model(test_input,label).detach().cpu().numpy()# detach 截断梯度,然后再放到CPU上
# 假设氨基酸字典为 amino_acids_dic
# print(table)
# 假设网络输出的概率矩阵为 output
# print(prediction_seq)
# 获取每个位点最大概率的氨基酸索引
amino_acids_index = np.argmax(prediction_seq, axis=2)
# print(amino_acids_index)
# 根据氨基酸索引获取对应的氨基酸
amino_acids_seq = []
for row in amino_acids_index:
seq = ''.join([amino_acids_dic[index] for index in row]) # 将氨基酸索引转换为氨基酸序列
amino_acids_seq.append(seq)
# 输出氨基酸序列
# print(amino_acids_seq)
return amino_acids_seq
# 后续加载回归模型去预测一下生成标签的结果
生成器,判别器,损失函数 ,实例化,创建one API 接口应用,加速model 和 优化器计算
在此之前我们先要安装 intel_extension_for_pytorch
python -m pip install intel_extension_for_pytorch
# 运行下面的代码检验是否安装成功 pytorch 和 intel-one API
python -c "import torch; import intel_extension_for_pytorch as ipex; print(torch.__version__); print(ipex.__version__);"
import torch
import intel_extension_for_pytorch as ipex
generator = Generator().to(device=device)
discriminator = Discriminator().to(device=device)
opt_gen = torch.optim.RMSprop(generator.parameters(),lr=0.0005)
opt_disc = torch.optim.RMSprop(discriminator.parameters(),lr=0.0005)
criterion = Wgansloss()
# 这里是构建 oneAPI AI tooklist的过程,只用将模型和优化器通过接口即可,其余都按照正常的训练步骤
generator , opt_gen = ipex.optimize(generator , optimizer=opt_gen )
discriminator , opt_disc = ipex.optimize(discriminator , optimizer=opt_disc )
训练代码
在经过400个epoch的时候,生成器的损失达到稳定
# 训练
num_epochs = 100
for epoch in range(num_epochs):
d_epoch_loss = 0
g_epoch_loss = 0
count = len(train_loader)
# disc_iter = 0 # 判别器的迭代次数
for seq, a4 in train_loader:
# print(seq.shape) # 编码完成的 氨基酸序列 形状 torch.Size([8, 56, 20])
# print(a4.shape) # 每个氨基酸序列对应的A4值 形状 torch.Size([8])
# break
seq = seq.to(device=device)
a4 = a4.to(device=device)
# 随机正态噪音
batch_size = seq.size(0)
random_noise = torch.randn(batch_size,100,device=device)
# A.训练判别器
opt_disc.zero_grad()
# 生成假样本
fake_seq = generator(random_noise, a4).detach()
# print(fake_seq)
# 计算真实样本判别器输出
# real_pred = discriminator(seq, a4)
# real_loss = criterion(real_pred, torch.ones_like(real_pred,device=device))
# real_loss.backward()
# # 计算假样本判别器输出
# fake_pred = discriminator(fake_seq, a4)
# fake_loss = criterion(fake_pred, torch.zeros_like(fake_pred,device=device))
# fake_loss.backward()
# wgans 训练方法 判别器计算 真、假样本的计算输出
real_pred = discriminator(seq, a4)
# real_loss = criterion(real_pred, a4)
# real_loss.backward()
fake_pred = discriminator(fake_seq, a4)
# fake_loss = criterion(fake_pred, a4)
# fake_loss.backward()
# opt_disc.step()
# Wasserstein 损失计算
discriminator_loss = criterion(real_pred, fake_pred)
# 损失backward(),梯度更新
discriminator_loss.backward()
opt_disc.step()
# disc_iter+=1
# 限制判别器参数的范围
for p in discriminator.parameters():
p.data.clamp_(-0.01, 0.01)
# 记录损失函数
disc_loss = discriminator_loss
# 判别器每更新五次参数则 生成器更新一次参数
# if disc_iter % 8 == 0:
# B. 训练生成器
opt_gen.zero_grad()
# 生成假样本
fake_seq = generator(random_noise, a4)
# 计算假样本判别器输出
fake_pred = discriminator(fake_seq, a4)
# gen_loss = criterion(fake_pred, torch.ones_like(fake_pred,device=device))
gen_loss = -torch.mean(fake_pred)
gen_loss.backward()
opt_gen.step()
with torch.no_grad():
d_epoch_loss +=disc_loss
g_epoch_loss +=gen_loss
print(f'Epoch [{epoch}/{num_epochs}]')
# 生成新样本
# ...
if epoch % 10 ==0: # 每25个epoch生成一次序列
with torch.no_grad():
# 每个epoch上 判别器的损失
d_epoch_loss = d_epoch_loss / count
# 每个epoch上 生成器的损失
g_epoch_loss = g_epoch_loss / count
# 每个epoch结束后,都添加到list中
print(f"d_epoch_loss:==>{d_epoch_loss}, and g_epoch_loss:==>{g_epoch_loss}")
D_loss.append(d_epoch_loss.item())
G_loss.append(g_epoch_loss.item())
print("给定的a4值 ==》 氨基酸序列:",a4_seed) # 展示标签,每个epoch应该不变
seq_gen_list = generator_seq(model=generator,test_input=noise_seed,label=a4_seed,table=amino_acids_dic)
print(seq_gen_list) # 展示生成的序列
generator_seq_history[epoch] = seq_gen_list # 将 seq_gen_list 存储到 generator_seq_history 字典中
# break
结果

不足之处:
可以根据损失函数进行丰富,可以多加几个损失函数 丰富模型的生成样式,同样可以变换模型结构去降低数据维度,同时加以大模型做氨基酸序列的嵌入。如果有相关的问题,可以联系我
邮箱 2397895834@qq.COM















 4258
4258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









