







-
目录
5、FlagEval(天秤评测)FlagEval - 首页
6、C-Eval(学科生成):https://cevalbenchmark.com
1、OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
一、大模型排名
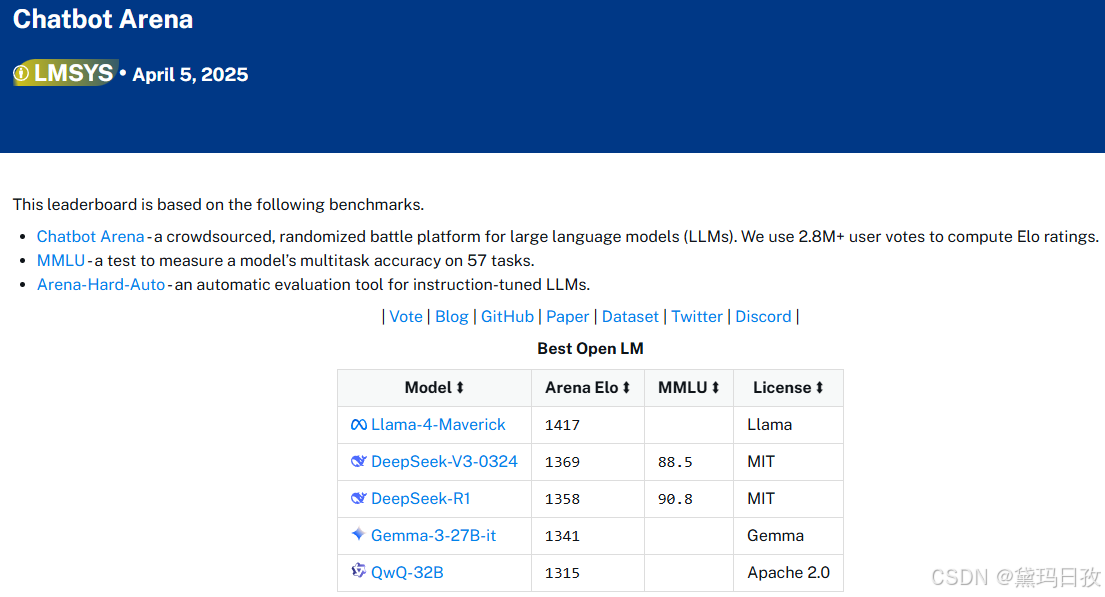
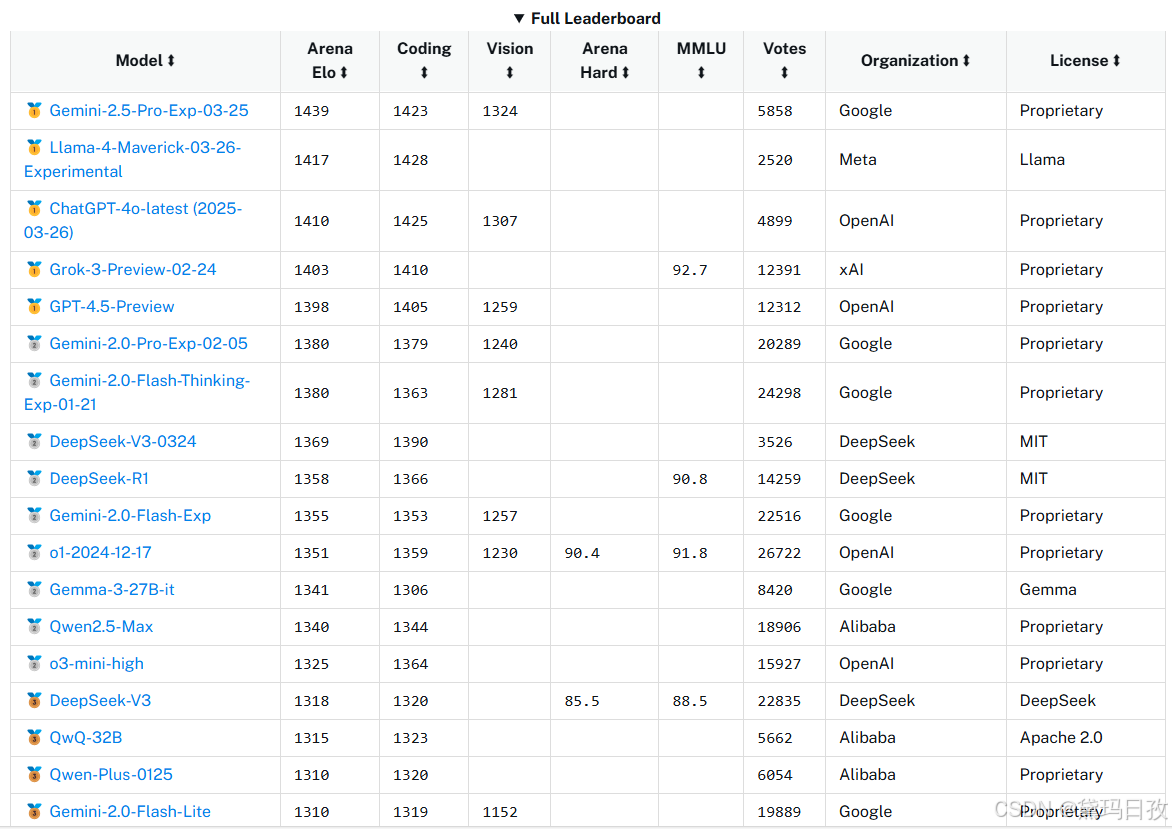
1、 Chatbot Arena | OpenLM.ai
Chatbot Arena(前身为LMSYS):免费AI聊天以比较和测试最佳AI聊天机器人
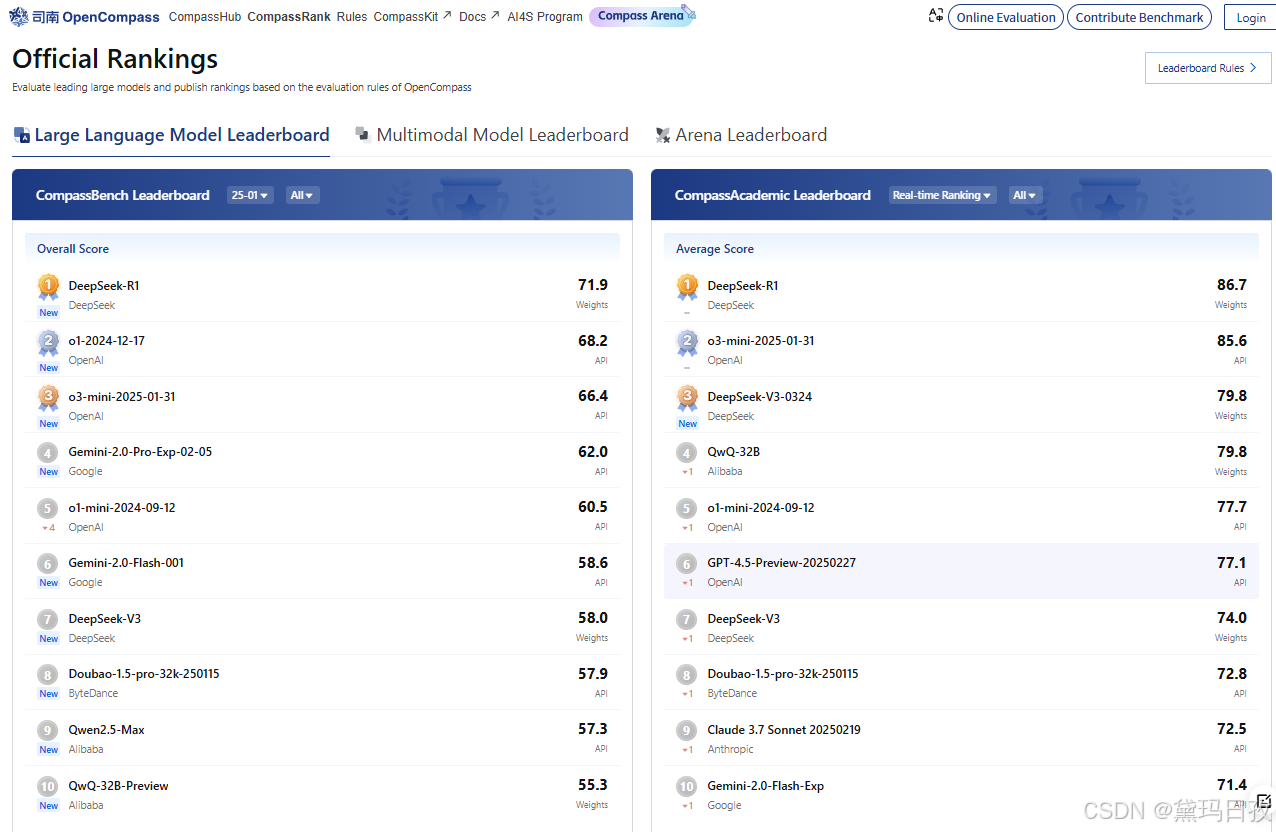
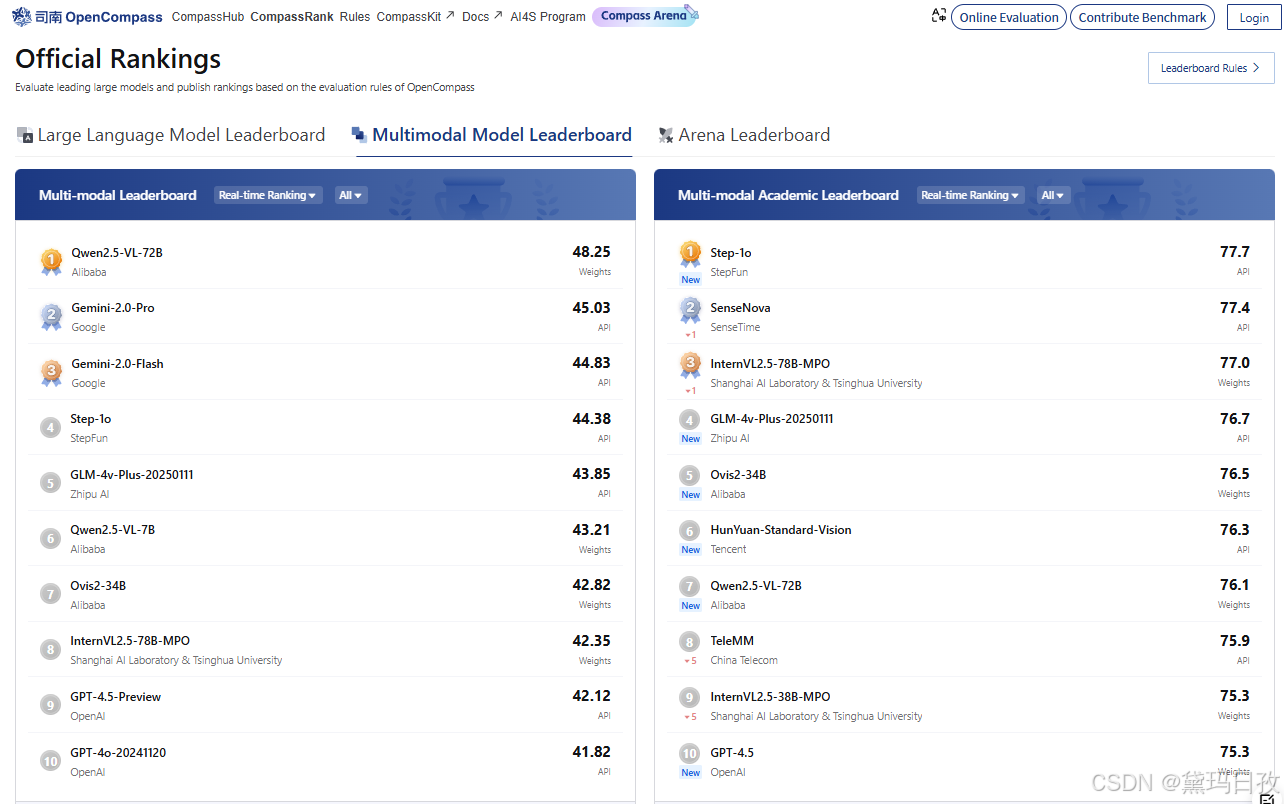
2、 OpenCompass司南 - 评测榜单
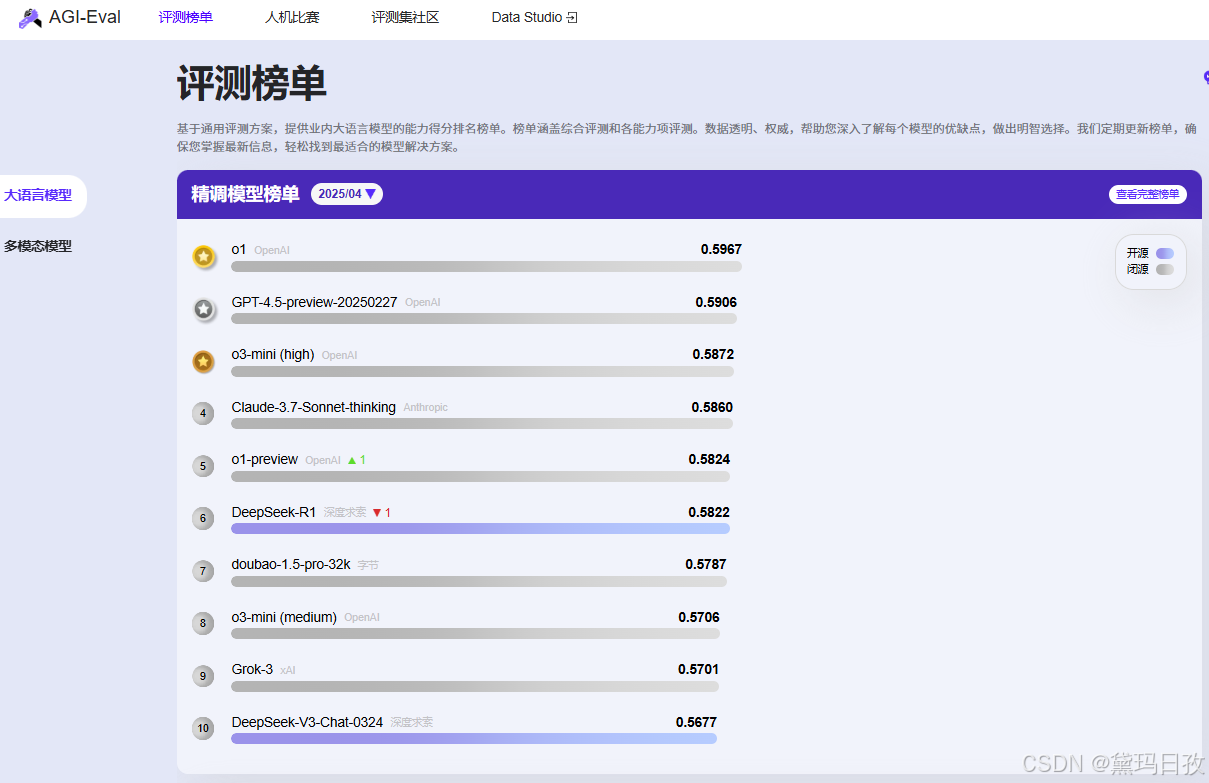
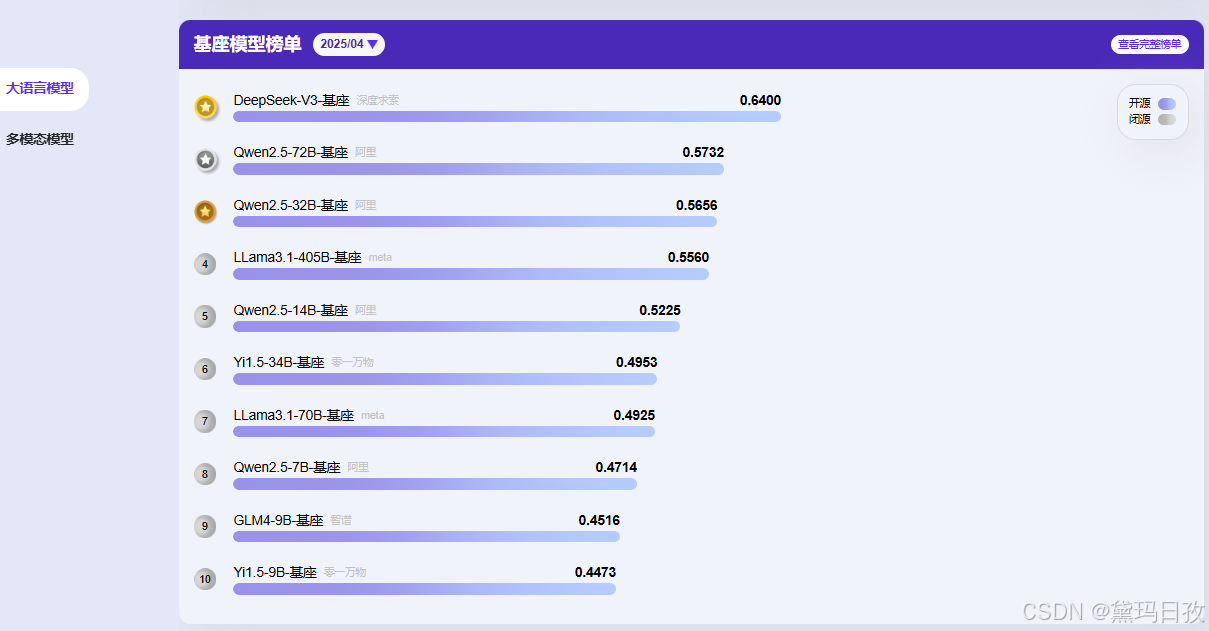
3、AGI-Eval AGI-Eval评测社区
官网:https://agi-eval.cn
功能:评估大模型认知与问题解决能力,提供透明榜单和开放数据集
-
4、中文通用大模型综合性测评基准(SuperCLUE)
是针对中文可用的通用大模型的一个测评基准。
它主要要回答的问题是:在当前通用大模型大力发展的情况下,中文大模型的效果情况。包括但不限于:这些模型哪些相对效果情况、相较于国际上的代表性模型做到了什么程度、 这些模型与人类的效果对比如何?它尝试在一系列国内外代表性的模型上使用多个维度能力进行测试。SuperCLUE,是中文语言理解测评基准(CLUE)在通用人工智能时代的进一步发展。
目前包括三大基准:OPEN多轮开放式基准、OPT三大能力客观题基准、琅琊榜匿名对战基准。它按照月度进行更新。
-
5、FlagEval(天秤评测)FlagEval - 首页
- 官网:https://flageval.baai.ac.cn
- 出处:智源研究院的多模态生成能力评测,细分文生图、文生视频等任务。例如,快手可灵1.5在文生视频任务中表现优异,腾讯Hunyuan Image在文生图任务中领先。
-
6、C-Eval(学科生成):https://cevalbenchmark.com
-
二、AI Agent性能榜单
-
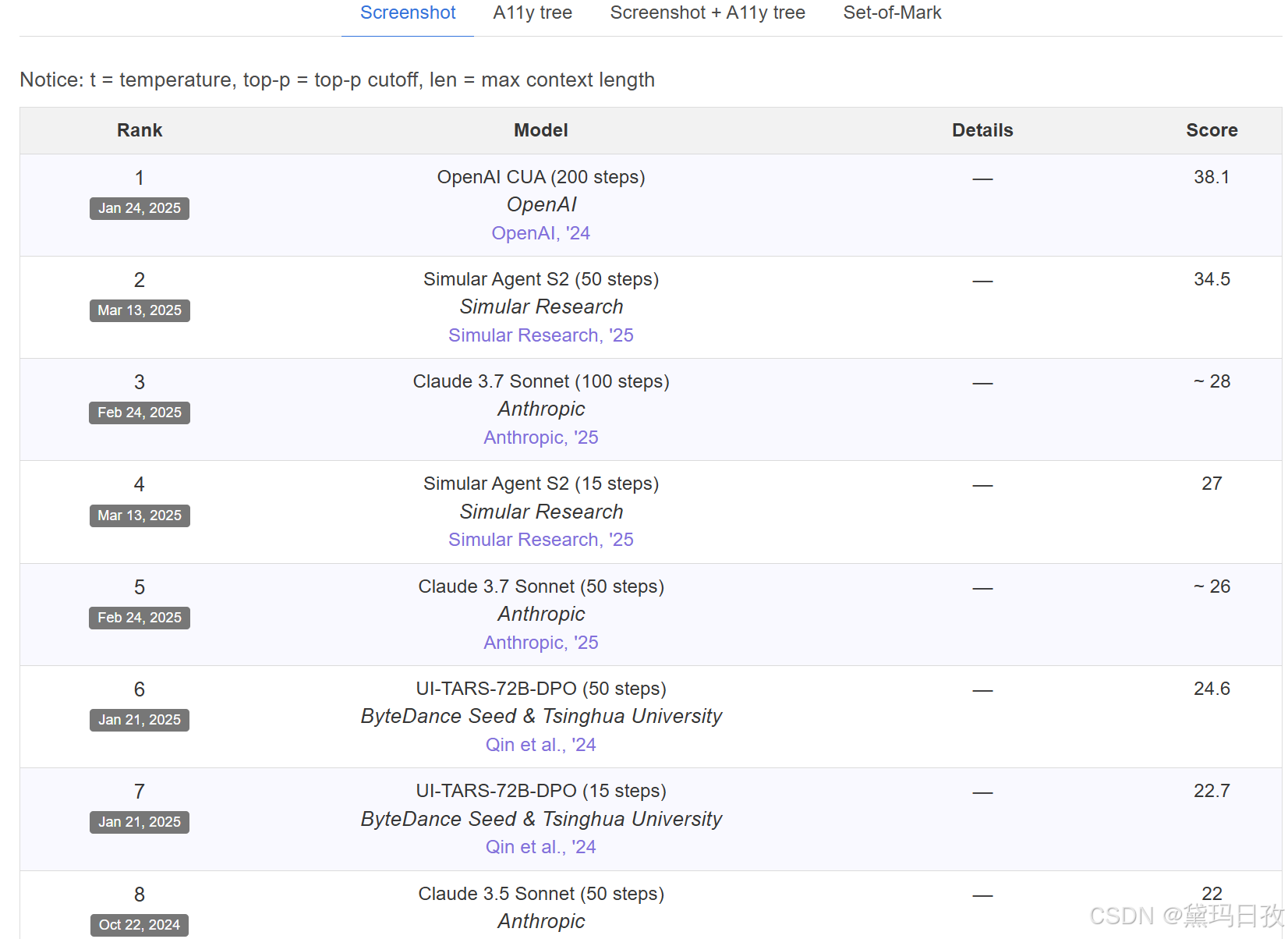
1、OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
-
2、GAIA基准测试(通用AI助手能力评测)
- 官网地址:
- Hugging Face GAIA Leaderboard(打不开):https://huggingface.co/spaces/gaia-benchmark/leaderboard
GAIA由Meta AI、Hugging Face、AutoGPT等团队联合推出,包含466道需多步骤解决的实际问题,覆盖工具调用、编程、网络检索等能力。
-
三、开源社区
-
1、Hugging Face(打不开)
定位:全球最大的AI开源社区,覆盖超40万预训练模型(如Llama3、Qwen2、DeepSeek)和数据集
核心功能:模型托管与推理服务(Inference API);Transformers库快速加载模型;Spaces功能支持应用部署。
适用场景:快速原型开发、多语言模型实验
链接:https://huggingface.co
-
2、魔搭社区(ModelScope)
定位:国内最大的开源社区,由阿里达摩院推出,集成通义千问、ChatGLM等国产模型
核心功能:一站式MaaS服务(模型即服务);创空间(Studio)支持多模型组合应用(如MinerU知识库工具);行业数据集与中文优化模型
适用场景:企业级AI开发、中文场景适配
链接:https://modelscope.cn
-
3、Papers With Code
官网:https://paperswithcode.com
Browse the State-of-the-Art in Machine Learning | Papers With Code
功能:汇总SOTA模型在特定任务(如目标检测、文本摘要)的性能数据。


















 1814
1814

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









