







生成式AI中常说的token是什么?嵌入(Embeddings)是什么意思?为什么现在的AI具有生成能力?AI是怎么和你进行对话的?为什么都说提示词很重要?为什么同一段提示词,同一个AI模型/工具,多问几次可能得到截然不同的结果?
要回答以上这些问题,你需要了解大语言模型(LLM)是如何工作的。知其然,也要知其所以然。

步骤1:分词(Tokenize)
面对一个问题,我们人类的习惯性操作是什么?理解问题。LLM也是一样。
LLM在处理输入文本时,首先使用分词器(Tokenizer)将文本分割成若干小的文本块,即tokens。这些tokens由可变数量的字符组成,随后被转换成高维向量的数值表示,也就是嵌入(embeddings),供模型处理。这一步骤是模型理解语言的基础,类似于人类阅读和解析文本的过程。
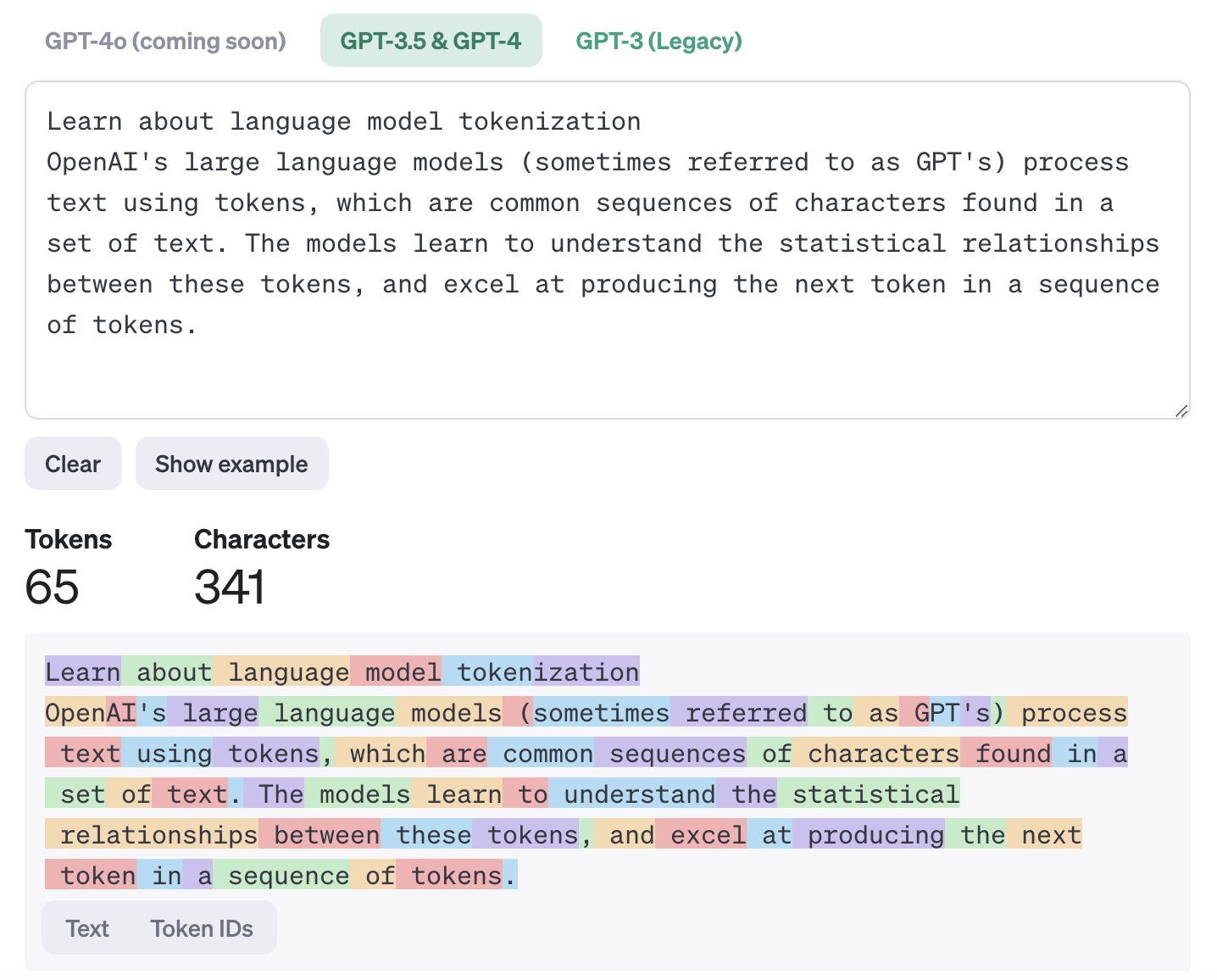
分词(Tokenize)是LLM工作的第一步&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1998
1998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









