







一、目录
1.Bert Embedding 参数量计算
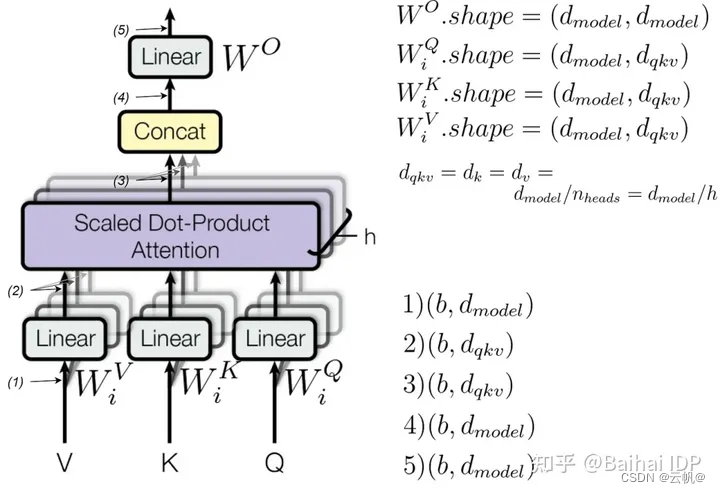
2.多头自注意力self_attention 参数计算: d_model* d_model + 3*(d_model* d_qkvnum_heads)
3. 全连接层参数量
4.layerNormer 参数量 2hidden
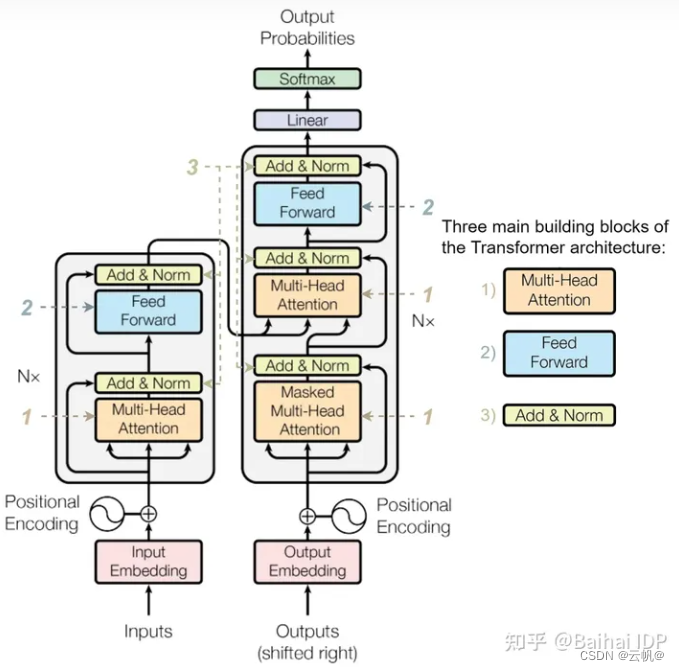
5. 编码器 解码器参数
6. 语言模型head 参数:hidden* vocab
二、实现
 参考:https://zhuanlan.zhihu.com/p/636500748
参考:https://zhuanlan.zhihu.com/p/636500748
import torch
def count_parameters(model:torch.nn.Module):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
-
Bert Embedding 参数量计算
包含三个表示层+一个LayerNorm 层,表示层为wordembedding+tokentype_embedding+position_embedding
假设词表大小 vocab size 为 30522,seq_length 为 512,那么有:
wordsembedding 参数为:(vocab,hidden)
segment_embedding 参数为:(2,hidden)
position_embedding 参数为:(512,hidden)
layerNorm 参数为 hidden*2
合并:(30522+2+512)1024+ 10242 -
多头自注意力self_attention 参数计算: d_model* d_model + 3*(d_model* d_qkv*num_heads)
self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=config.attention_bias)
self.k_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=config.attention_bias)
self.v_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=config.attention_bias)
self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=config.attention_bias)
d_model=512
n_head=8
multihead_attention=nn.MultiheadAttention(embed_dim=d_model,num_heads=n_head)
print(count_parameters(multihead_attention))
print(4 * (d_model * d_model + d_model))
- 全连接层参数量
FeedForward 参数 Linear(1024,4096) 以及 Linear(4096,1024)
参数为:210244096
class TransformerFordWard(nn.Module):
def __init__(self,d_model,d_ff):
super(TransformerFordWard,self).__init__()
self.d_model=d_model
self.d_ff=d_ff
self.linear1 = nn.Linear(self.d_model, self.d_ff)
self.relu = nn.ReLU()
self.linear2 = nn.Linear(self.d_ff, self.d_model)
def forward(self, x):
x = self.linear1(x)
x = self.relu(x)
x = self.linear2(x)
return x
d_model=512
d_ff=2048
feed_forward = TransformerFordWard(d_model, d_ff)
print(count_parameters(feed_forward)) # 2099712
print(2 * d_model * d_ff + d_model + d_ff) # 2099712
- layerNormer 参数量 2*hidden
d_model = 512
layer_normalization = nn.LayerNorm(d_model)
print(count_parameters(layer_normalization)) # 1024
print(d_model * 2) # 1024
-
编码器 解码器参数
编码器= attention + feed_forward+2layer_norm
解码器= 2 attention +feed_forward+3* layer_norm
from torch import nn
encoder_layer = nn.TransformerEncoderLayer(d_model=512, nhead=8)
print(count_parameters(encoder_layer)) # 3152384
decoder_layer = nn.TransformerDecoderLayer(d_model=512, nhead=8)
print(count_parameters(decoder_layer)) # 4204032
print(decoder_layer)
- 语言模型head 参数:hidden* vocab
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)















 1050
1050











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









