







instant-ngp
instant-ngp是今年NVIDIA在SIGGRAPH 2022中的项目,由于其"5s训练一个Nerf"的传奇速度,受到研究人员的关注。下面对其做简单介绍,也作为自己学习的记录。
背景
传统基于全连接的神经网络已经能解决很多问题,比如MLP结构(PointNet、Nerf等),但是这种全连接的神经网络在训练和评估中代价很大。同时在基于深度学习的图形学任务中,每个工作都针对自己特定的task,设计不同的网络结构,这样的缺点是这些方法只限制在特定的任务上,同时这些工作在优化整个网络的过程中,需要对整个网络进行优化,这加大了网络的花费。
方案
作者提出一种基于多分辨率的哈希编码方案,这个方案与task无关,是一种通用的方案(改方案能用在多种不同任务中),改方案只由参数T和期望的分辨率Nmak配置,实验结果表明该方案在多项任务上达到了不错的效果。该方案与任务无关的自适应性和效率的关键是哈希表的多分辨率层次结构。
Adaptivity
作者将网格级联的映射到相应的固定大小的特征向量数组。在粗分辨率下,从网格点到数组条目有一个1:1的映射。在精细分辨率下,数组被视为一个哈希表,并使用空间哈希函数进行索引,其中多个网格点为每个数组条目起别名。
这种哈希碰撞将导致训练梯度达到平均水平,这意味着最大的梯度(与损失函数最相关的梯度)将占主导地位,因此哈希表将自动对最重要且细节最丰富的部分做优先考虑。同时与之前的工作不同,在instant-ngp的训练期间不需要对数据结构进行系统性更新。
Efficiency
哈希表的查找是O(1),同时哈希表可以并行的查找。
MultiResolution Hash Encoding



一个全连接网络 m(y; ϕ \phi ϕ),对输入的y进行编码y=enc(x; θ \theta θ),因此在instant-ngp中,既有可训练的权值参数 ϕ \phi ϕ,也有可训练的编码参数 θ \theta θ。这些参数被分布为L个层,每层中包含T个维度为F的特征向量。上面的表1为哈希编码参数,只有哈希表的大小T和期望的分辨率Nmak需要被设置(作为超参数 )。
在这个过程中,每个层是独立的(如上图中的红蓝两层,分别代表不同层级。红色代表分辨率较高的体素网格、蓝色代表分辨率较低的体素网格),同时存储网格顶点所代表的特征向量,每一层的分辨率是最糙分辨率与最佳分辨率之间的几何级数。[Nmin,Nmak]。Nmak代表了数据中的最好细节。
由上面的陈述我们知道参数被分为L个层,按照表1给出的超参数可知L被设置为16,即体素的分辨率有16个等级,那么分辨率层级从低到高的变化公式为:

其中b被认为是成长参数,作者将其设置为1.38到2之间。对于L层中的某个层l,输入的坐标点对应的分辨率为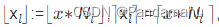
对于较粗糙的网格,不需要T个参数,它的参数量应该为(N𝑙)d≤T,这样以来映射就可以保证一对一的关系,对于精细网格,使用空间哈希函数h:Zd→ZT将网格索引到数组。本文中空间哈希函数的定义为
运算符
⨁
\bigoplus
⨁表示异或运算,
π
\pi
πi表示独一无二大小的大素数,改计算在每一维产生线性同余排列,以解除维度对哈希值的影响。最后根据x在体素中的相对位置,实现体素内角点特征向量的线性插值,插值的权重为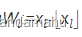 (我猜这里应该代表可视化图中,线性插值的部分,但还是有些不理解)。
(我猜这里应该代表可视化图中,线性插值的部分,但还是有些不理解)。
根据以上对哈希编码的陈述,可以理解这个过程在L层中可以独立的执行,不会相互干扰。这样的话每一层的插值向量以及辅助输入(位置+视角方向)被串联以产生y,y是由输入的enc(x;𝜃)到MLP m(y;Φ)。
神经网络训练参数
为了优化GPU的缓存,作者逐级的处理对应的哈希表,当处理一批输入时,首先计算多分辨率哈希编码的第一级,接着是第二级,依次类推。所以在整个过程中,只有少量的哈希表需要驻留在GPU缓存中,节省了GPU的内存。
问题
- Q1:什么是计算机图形基元
我的理解就是计算机图形中的基本元素:像素、线条、特征点等。
- Q2:多个网格点为每条数组条目起别名

我理解这步就是,将多个网格点组成的特征向量,通过哈希函数,映射到对应的哈希表中。
- Q3:下图的红蓝代表不同尺度,换句话说是将坐标进行缩放,它是怎么缩放的?
我猜测可能的步骤有两种:
1.将坐标点转换为一个特征向量,然后在将特征向量简化
2. 整个空间用体素分隔开,那么对于三维空间中一点用多级的体素块去表达。用粗糙的体素块去表达整个空间,学习整个场景的宏观特征。用精细的体素块去表达整个空间,学习到场景的精细细节。
- Q4: • 为什么使用作者提出的空间哈希函数,在每一维产生线性同余排列(可理解),为什么可以解除维度对散列值的影响呢?

- Q5:根据x在体素网格中的相对位置,实现对体素内角点的特征向量线性插值,插值的权重为
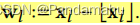
那这个权重是怎么计算到的Xl指的是什么?Xl向下取整又指的什么?
- Q6:哈希表这块怎么训练,所谓的θ参数是什么
我的理解是,将对应的值先用对应的哈希函数处理,然后再用MLP结构将哈希值映射为一个特征向量。所谓的参数θ就是对哈希值映射的MLP层的权重,与做Nerf处理的MLP结构的权重Φ区分开。

我对这里的理解是:
传统的神经网络都是将输入映射到高维空间,通过神经网络从数据中拟合特点的规律,实现我们的任务。
神经网络从根据特定的任务,可以像搭积木一样,增加或者删除特定的模块,去适应对应的任务。但是这种方法的缺陷就是,构建出的特定框架,只能适合特定的任务。

第一句话中,将级联的网格映射到相应大小的特征向量数组上,在粗分辨率下网格到数组条目的映射是1:1。怎么从网格映射到数组?网格是怎么来的?Nerf中的网格是啥?
第二句话中,在精细分辨率下,数组被视为一个哈希表,并使用空间哈希函数进行索引,其中多个网格点为每个数组条目起别名。多个网格映射到同一个数组理解,但是网格点怎么作为值映射成哈希值?
第三句话,这种哈希碰撞导致碰撞训练梯度达到平均水平,这意味着最大的梯度——那些与损失函数最相关的梯度——将占主导地位。
第四句话,因此,哈希表自动对具有最重要精细细节的稀疏区域进行优先级。与之前的工作不同,在training期间的任何时候都不需要对数据结构进行结构性更新。这里能理解。

中间划线的话,怎么把这些参数划分为L个级别,就是用不同层级分辨率吗?

怎么对输入的坐标点X进行缩放
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









