







Instant-NGP论文笔记
2022年英伟达的论文: Instant Neural Graphics Primitives with a Multiresolution Hash Encoding
论文地址:Instant-NGP
论文讲解视频:B站视频
介绍
使用哈希编码的多分辨率的即时神经图形原语
使用全连接神经网络的 神经图形原语 训练和评估是非常耗时的
设计了一个新的通用性的输入编码,它可以使用小型的网络同时又不会降低质量
小型的网络可以显著的减少浮点数的计算和内存访问
多分辨率的结构可以使网络自己处理哈希碰撞的问题
NGP使用了完全的cuda编程,更小的带宽浪费和更少的计算
1920x1080分辨率的图像可以在10ms完成渲染
计算图形原语由数学公式定义的,带有参数形式的外观表示
数学表示的质量和性能特征对于视觉保真度至关重要:我们希望表示在捕获高频、局部细节的同时保持快速和紧凑。
将神经网络输入映射到高维空间的编码,这是从紧凑模型中提取高近似质量的关键
多分辨率编码的方式是可自适应和高效的,独立于任务的
作者在四种类型的任务上进行了验证
- 百万像素图像:高分辨率图像的渲染
- SDF
- NRC
- NeRF
将输入编码到高维空间的几种方式
1. 频率编码
香草NeRF使用的三角函数的方法,这种称为频率编码
这种编码方式,就是使用线性变换,将低频转换成高频
2. 参数编码
参数编码是除了权重和偏置之外,增加一种辅助类型的数据结果,如网格或者树
可以根据输入向量,在这些结构上(网格或者树),使用插值的方式获取值
这种安排用更大的内存占用换取更小的计算成本:对于通过网络向后传播的每个梯度,完全连接的MLP网络中的每个权重都必须更新,对于可训练的输入编码参数(“特征向量”),只有非常小的数量受到影响
例如,网格类型中的一个点位的值,其计算使用三线性插值的方式,只需要计算周围八个点的数据
通过这种方式,尽管参数编码的参数总数比固定的输入编码要高得多,但在训练期间进行更新所需的FLOPs和内存访问的数量并没有显著增加
通过减少MLP的大小,训练速度可以得到提升,并且不会降低质量
3. 稀疏参数编码
密集型Grid中的可训练参数比神经网络中的权重使用更多的内存
密集型网格有两种类型的浪费:
- 在空间中的空白部分,也会进行分配,也会进行特征计算,但是它们是无用的
- 参数的数量是N的三次方,但是有用的物体表面的数据是N的2次方,这个N可以认为是分辨率
- 密集型网格会容易学习的过度平滑
多分辨率哈希编码
多分辨率哈希编码是这篇论文中的核心内容
假设这个表示神经网络: m ( y ; Φ ) m(\mathrm{y} ; \Phi) m(y;Φ),这个表示输入编码: y = enc ( x ; θ ) \mathbf{y}=\operatorname{enc}(\mathbf{x} ; \theta) y=enc(x;θ)
那么这个论文的内容就是在研究这里的输入编码部分
在保证相同的质量的情况下,达到更好的训练速度,同时不会增加开销
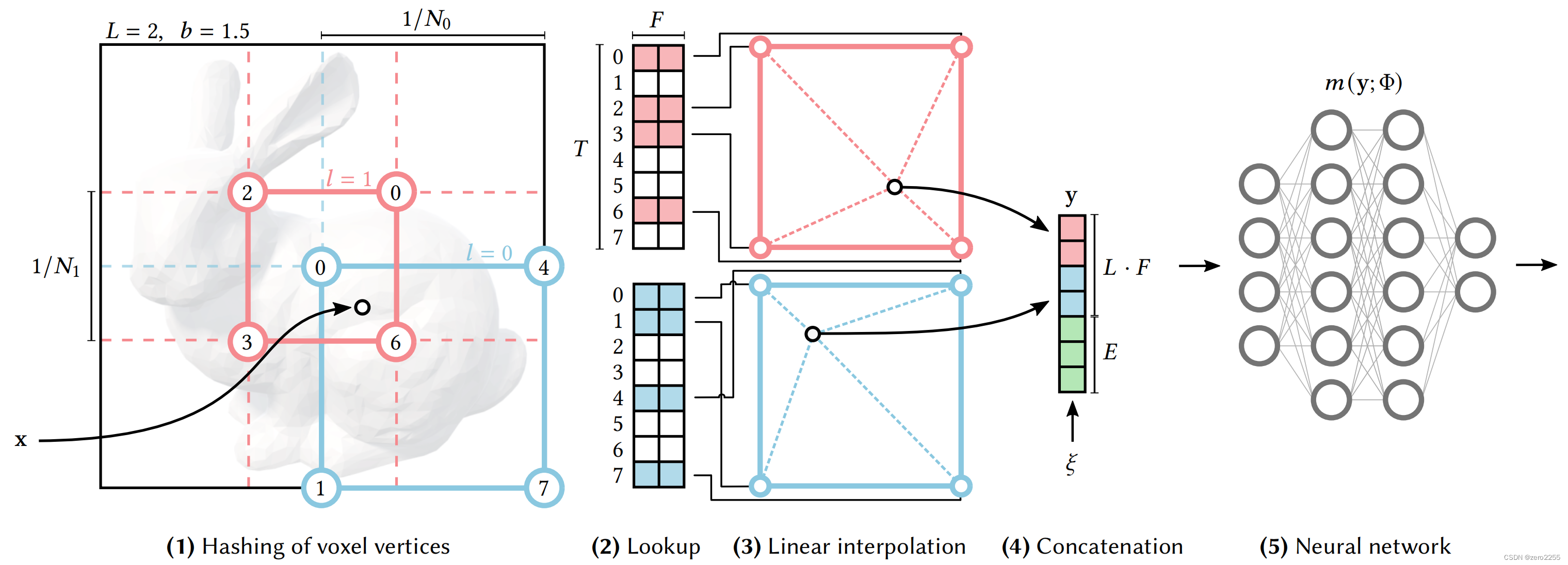
上图是NGP的简易过程
- 第一步是将坐标点(xyz的真实值)转换为hash表中的index
- 途中蓝色粉色表示了不同的Level下的计算,不同的Level,网格的分辨率不同(上图中粉色网格小,粉色的分辨率就比蓝色的大)
- 第二步是在不同层级的hash table中找到目标值周围的八个点位的值,然后进行三线性插值
- 第三步就是将所有的Level的结果拼接,到这里就算完成了encoding
- 第四步就是送入神经网络即可
NGP中不仅网络权重要进行训练,编码参数也要进行训练
参数编码,设计成L层,每层有 T个特征向量,每个向量的维度是F
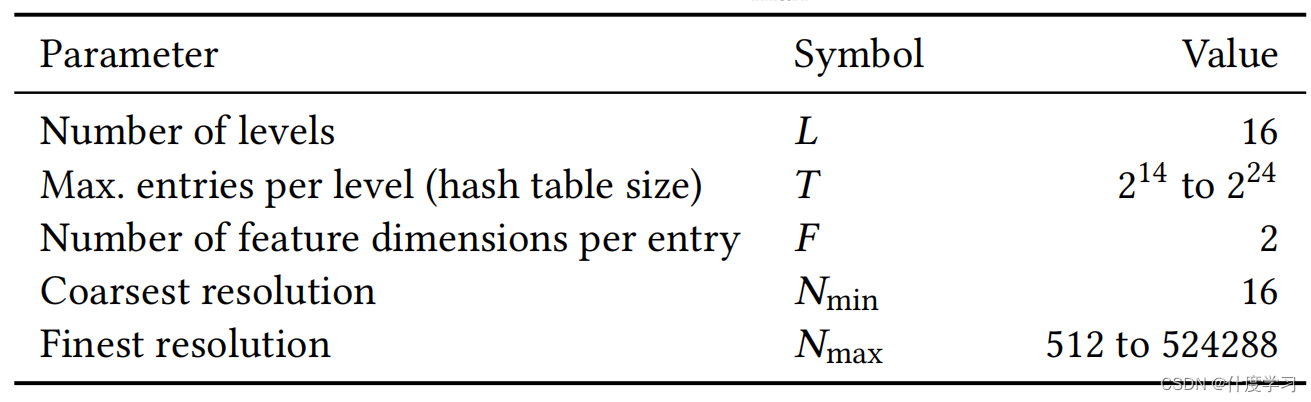
每层所代表的分辨率,是最粗糙的分辨率和最精细的分辨之间的 插值
N l : = ⌊ N min ⋅ b l ⌋ b : = exp ( ln N max − ln N min L − 1 ) \begin{aligned} N_l &:=\left\lfloor N_{\min } \cdot b^l\right\rfloor \\ b &:=\exp \left(\frac{\ln N_{\max }-\ln N_{\min }}{L-1}\right) \end{aligned} Nlb:=⌊Nmin⋅bl⌋:=exp(L−1lnNmax−lnNmin)
每层的分辨率以Nmin为系数,乘上b的l层指数
b这个参数是根据Nmax,Nmin,L三个超参数计算得出的
在粗糙的层级中,网格的数量是小于T的数量的,因此对应关系可以1:1
但是在精细的层级中,网格的数量是大于T的数量的,因此使用了一个Hash映射
这个hash表并不需要考虑如何处理哈希碰撞的问题
完全依赖于训练时,靠梯度传递来进行这个参数Hash表的优化,以及后续的神经网络都会帮着进行优化
这里大致是说可能两个点位的值会索引到同一个地方产生冲突
但是神经网络的训练,会将这种冲突的索引分开,虽然key是不够的,但是在空间中大部分的区域也是没有值的
因此神经网络会将更有价值的点位作为主导梯度的部分
例如,辐射场的可见表面上的一个点将强烈促进重建图像(具有高能见度和高密度,两者都倍增影响梯度的大小),导致其表中的值的巨大变化,而空白空间中的一个点碰巧引用同一表中值将有一个小得多的权重
h ( x ) = ( ⨁ i = 1 d x i π i ) m o d T h(\mathbf{x})=\left(\bigoplus_{i=1}^d x_i \pi_i\right) \quad \bmod T h(x)=(i=1⨁dxiπi)modT
论文中的 θ \theta θ 参数的大小 是 TxLxF
公式XOR是每维线性同余(伪随机)排列的结果
XOR就是二进制异或 x表示grid的每个维度,每个维度对应一个大质数
对于空间三维xyz
- π 1 : = 1 \pi_1:=1 π1:=1
- π 2 = 2654435761 \pi_2=2654435761 π2=2654435761
- π 3 = 805459861 \pi_3=805459861 π3=805459861
最后,对于每个空间点位,会在每个层中找到相邻的8个点位(这八个点位就是上面的hx公式计算得到的),在利用这八个点位的值进行三线性插值得到目标值
到这里就完成了输入的encoding
T值的选择会决定模型的质量和性能,以及内存使用
一个高的T值,会有更好的质量,但是较低的性能
内存的使用与T值的大小是线性的关心
同时F值(特征长度)也与质量和性能有关
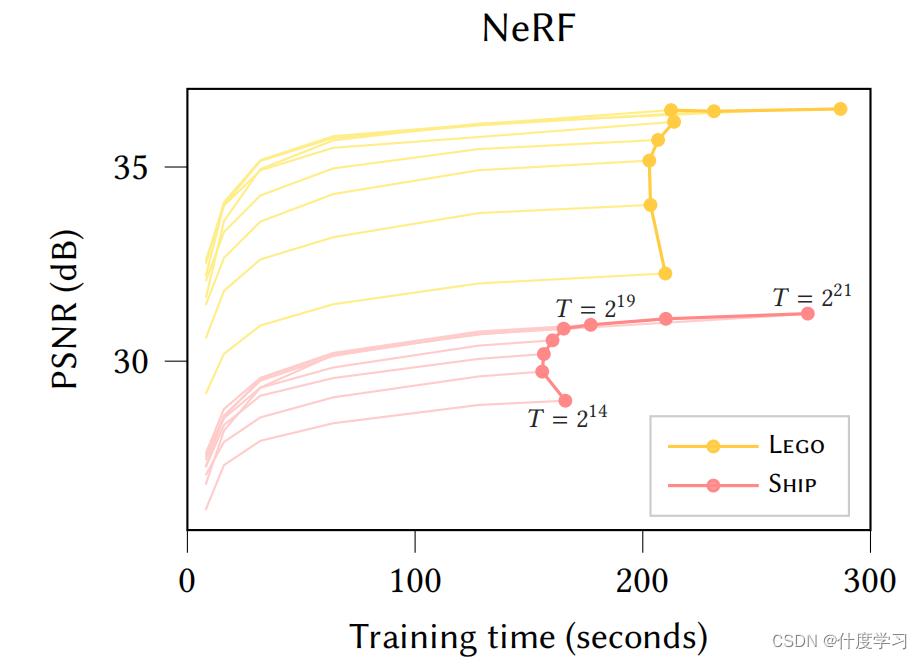
上图是不同的T值在NeRF场景下的实验
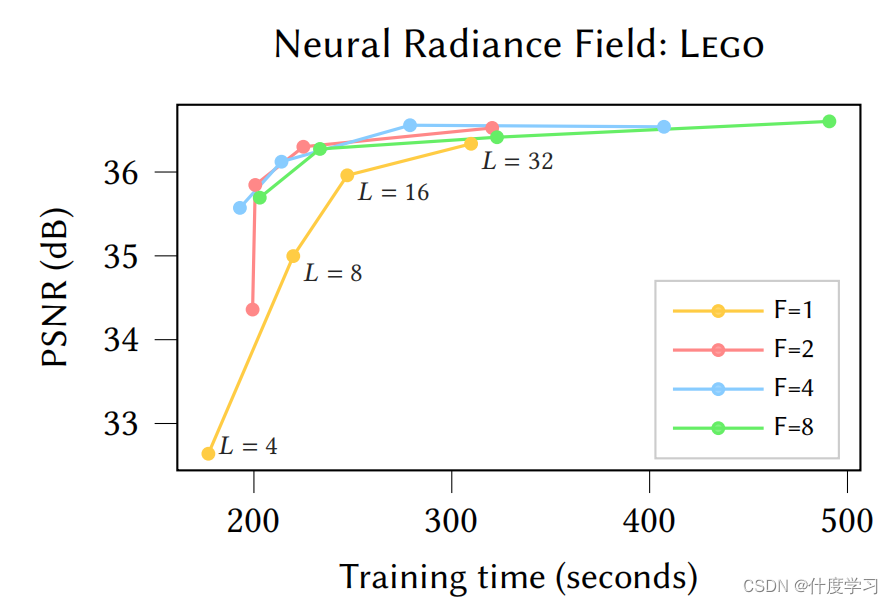
上图是不同的F值在NeRF场景下的实验
在NeRF上的实验
NGP的NeRF实现,与香草NeRF有些不同
- 香草NeRF使用了两次MLP,一次粗模型训练,一次精细模型训练
- NGP并无没有区分粗网络和精细网络,NGP的粗糙精细体现在了不同Level上
- NGP使用了两个MLP,一个负责计算体积密度,第二个在其后面计算RGB
第一个体积密度MLP的输出维度是16
第二个RGB MLP的输入为:
- 体积密度的16维度的输出
- 视角方向投影到球谐基的前16个系数
第一个MLP只有一个隐藏层,第二个MLP有两个隐藏层,这比原始NeRF的MLP要少很多
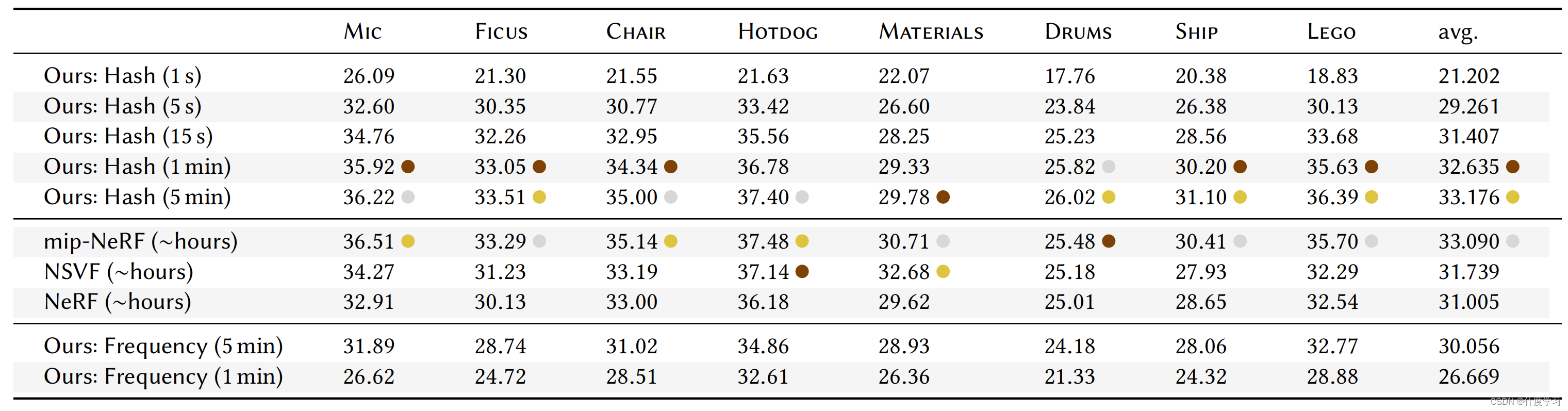
上图是NGP与NeRF,NSVF,Mip-NeRF的对比,其中的颜色代表金银铜,表示第一第二第三
可以看到在3个场景中是最高值,最后的平均值是这些模型中最好的

















 3325
3325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









