







1、windows下安装Scrapy框架
cmd进入命令行模式
pip install scrapy
然后就是静静的等待安装完成
常见问题:pip版本有可能太旧,此时只需要更新一下pip就好
(命令行中输入更新代码:python -m pip install --upgrade pip)
2、Scrapy框架的基础知识
2.1 基本组成:
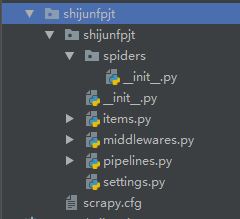
spiders为核心代码,主要是一些爬虫的我们写的核心代码文件
_init_为初始化文件,主要是项目的初始化信息
items为数据容器文件,主要是在其中定义我们要获取的数据
pipelines为管道文件,主要为爬虫设置一些信息
settings为设置文件,主要是项目的一些设置信息
2.2 scrapy中的常见工具命令
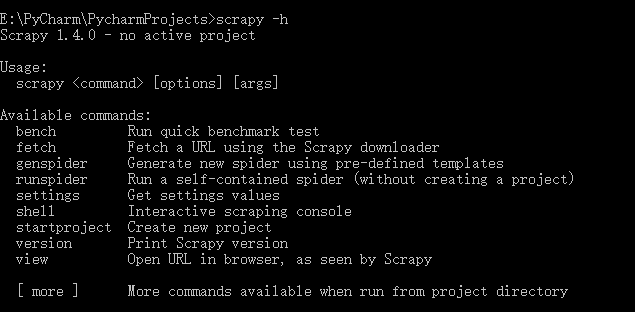
1、查看所有的全局变量:scrapy -h(命令行中输入此代码,记得在没有进入项目文件的时候输入)
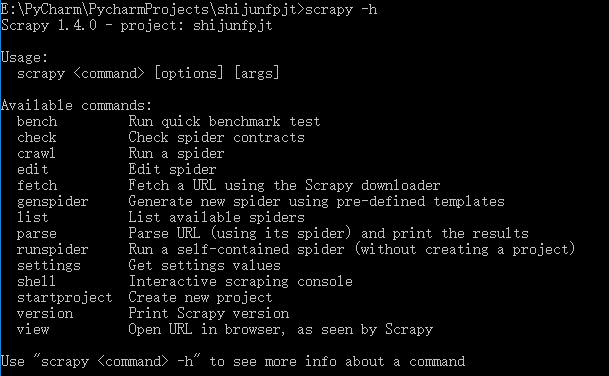
2、查看所有的项目变量:scrapy -h(命令行中输入此代码,记得在进入项目文件的时候输入)
2.3 创建一个爬虫项目
首先使用 “start project 项目名”创建一个爬虫项目
在命令行中输入:start project shijunfpjt
接下来进入该项目:cd shijunfpjt
这样我们就创建了一个shijunfpjt爬虫项目了,用pycharm打开如下图所示:

在命令行中输入scrapy startproject -h,可以调出startproject的帮助信息
2.3.2创建一个爬虫文件
scrapy genspider -l : 查看当前可使用的爬虫模板
scrapy genspider -t basic shijunfspider baidu.com : 创建一个新的爬虫文件shijunfspider
import scrapy class ShijunfspiderSpider(scrapy.Spider): name = 'shijunfspider' allowed_domains = ['baidu.com'] start_urls = ['http://baidu.com/'] def parse(self, response): pass
name : 爬虫文件的名称
allowed_domains = ['baidu.com']:允许爬取的域名
start_urls:代表爬虫爬行时的起始网址
pase:是一个方法,在没有指定回掉函数的时候,scrapy爬虫默认使用该方法
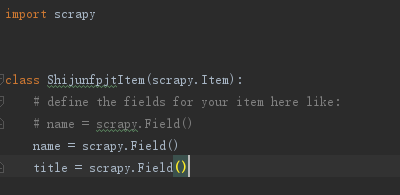
2.4 Items
items为数据容器文件,主要是在其中定义我们要获取的数据。其主要目标是从非结构化数据源(通常是网页)提取结构化数据。
1、规划好我们要结构化的信息
2、到items文件中去定义结构化的信息
定义结构化数据信息的格式:结构化的数据名 = scrapy.Filed()
















 637
637











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











