







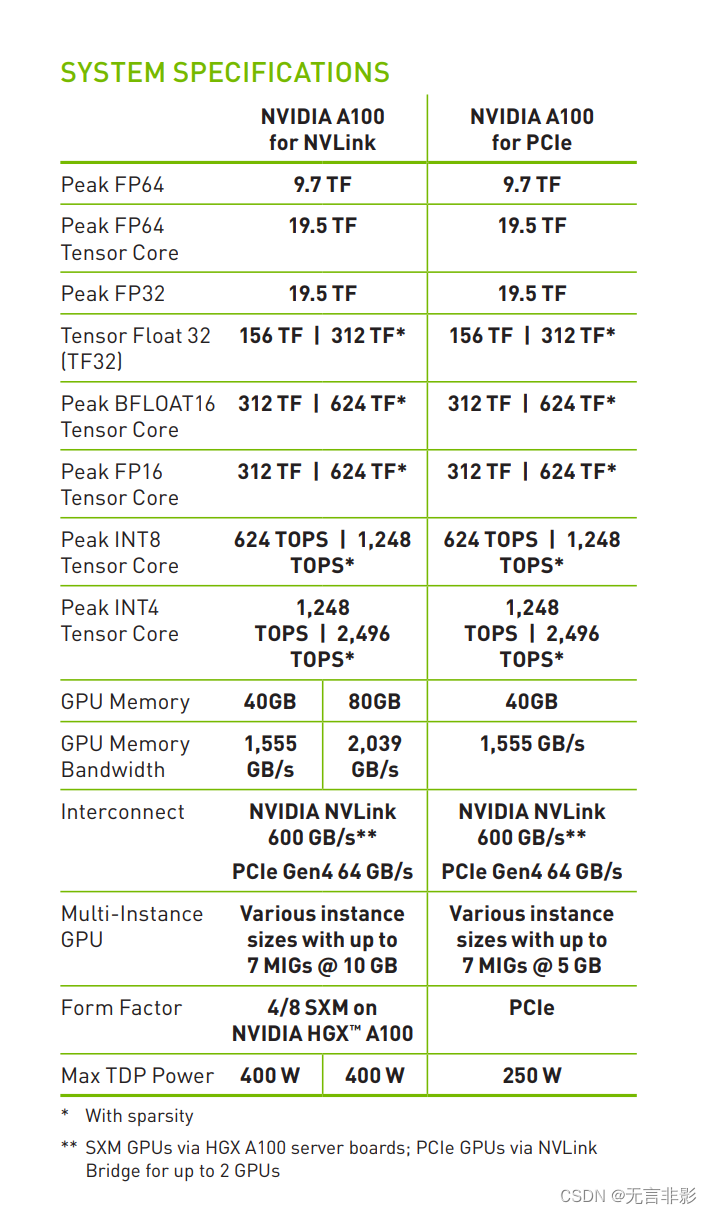
NVIDIA A100 NVLink 和 NVIDIA A100 PCIe 是两种不同连接方式的 NVIDIA A100 GPU。
-
NVIDIA A100 NVLink: 这种版本的 A100 GPU 使用 NVLink 连接方式,可以实现更高的带宽和更低的延迟。NVLink 是 NVIDIA 的一种专有连接技术,用于连接多个 GPU,使它们能够以高速率共享数据。这对于需要大量并行处理和数据交换的应用程序(如深度学习、科学计算)非常有利。使用 NVLink 连接的 A100 GPU 通常用于高性能计算 (HPC) 系统和大规模 AI 集群。
-
NVIDIA A100 PCIe: 这种版本的 A100 GPU 使用标准的 PCIe 连接方式。虽然 PCIe 的带宽和延迟性能不如 NVLink,但它提供了更好的兼容性和灵活性。A100 PCIe GPU 可以在标准的 PCIe 插槽中安装,因此它可以轻松地集成到各种服务器和工作站中。这使得 A100 PCIe 版本更适合那些不需要极端带宽或低延迟,但仍然需要 A100 强大计算能力的应用场景。
总的来说,选择哪种版本取决于你的具体需求和应用场景。
如果需要最高的性能和数据传输速度,NVLink 版本可能是更好的选择。
如果需要更好的兼容性和灵活性,那么 PCIe 版本可能更适合。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









