






作为一名个人AI开发者,面对预算的限制,我深知自己无法像大型企业或机构那样投入几百万购买国产高端AI算力硬件。因此,我的目标是找到性价比高的AI算力工具,能够在一两万预算内提供足够的计算能力,辅助我进行深度学习模型的开发、训练和推理工作。基于这一背景,我将探索市场上适合个人开发者使用的显卡和硬件配置,确保既能满足工作需求,又不至于超出预算限制。
在选择AI算力硬件时,我会优先考虑以下几个方面:计算能力(尤其是在深度学习和推理任务中的表现)、硬件的稳定性与可靠性、以及能否与现有开发环境(如TensorFlow、PyTorch等)兼容。同时,也会关注显卡的显存大小,因为深度学习模型通常需要大容量显存来处理复杂的数据集和计算任务。
在32GB显存的情况下,你确实可以在bp16(即半精度浮点数)精度下部署多个大型语言模型(LLMs),包括Qwen 14B系列、DeepSeek系列和GLM-4-9B系列模型。不过,能否顺利部署取决于多个因素,包括具体的显存管理、模型压缩以及输入数据的批次大小等。
1. Qwen 14B系列模型
- 显存需求:Qwen 14B系列模型的大小大约为14B参数,在使用fp16精度时,通常需要约28GB左右的显存。假设你使用了bp16精度(即混合精度训练),理论上32GB的显存足够容纳一个14B参数的模型并运行,但需要注意批次大小(batch size)和推理的输入长度,尤其是在大规模推理时。
2. DeepSeek系列模型
- 显存需求:DeepSeek模型的参数量和显存需求因具体的版本和配置而有所不同。如果你所提到的是类似于DeepSeek 13B或类似规模的模型,那么在bp16精度下,你应该能够在32GB显存的显卡上进行推理。对于更大的模型,如DeepSeek 20B及以上版本,32GB显存可能会显得稍显紧张,但依然可以通过混合精度和合适的批次大小来应对。
3. GLM-4-9B模型
- 显存需求:GLM-4-9B模型相对较小,参数量大约为9B,在fp16精度下,显存需求大概在18GB-20GB左右。32GB显存足够支持该模型,尤其是在使用混合精度(bp16)时,显存消耗会进一步降低,这使得你能够进行更大批次的推理或同时加载多个模型。
总结:
- 32GB显存可以支持在bp16精度下部署如Qwen 14B、DeepSeek 13B和GLM-4-9B等模型,特别是在进行推理时,如果合理设置批次大小和管理输入长度,你可以在显存限制内运行这些模型。
- 关键因素包括选择合适的推理工具和框架(如NVIDIA TensorRT、DeepSpeed等),它们能帮助优化显存使用并提高推理效率。
- 对于更大的模型(如Qwen 20B及以上),你可能需要更高显存配置,或者使用分布式推理方案。
我在美国封锁RTX 4090销售之前买了一块4090。这是我作为个人AI开发者的一次明智投资,因为这款显卡的强大性能为我带来了巨大的计算能力,尤其是在进行深度学习任务时,能够显著提高训练和推理的效率。4090的24GB显存和强大的CUDA核心,几乎可以应对市面上大多数复杂的AI模型,尤其是在大规模的神经网络训练中,它的表现远超许多其他显卡。
更重要的是,这款显卡不仅能够加速我现有的AI工作流,还能够为未来的开发提供足够的性能保证,尤其是在逐步扩展我的项目规模时,4090的计算资源将确保我能够顺利应对模型复杂度的提升。随着深度学习技术的不断发展,我也希望能通过更多的技术优化,使得这块显卡的性能最大化。
当然,在购买之前我也做了很多市场调查,尽管价格不菲,但考虑到性价比和未来的使用需求,我认为这是一次值得的投资。尤其是在AI算力逐步成为发展核心的今天,拥有一块强大的GPU意味着我能更快地迭代模型,提升工作效率,推动我的AI项目向前发展。
不过,随着RTX 4090在美国市场的封锁,也让我意识到高端硬件的获取可能会越来越困难。因此,我更加珍惜手中的这块显卡,并且会充分利用它进行更复杂的AI模型开发和训练。
随着预算的限制,我也在考虑如何通过合理配置和精细调优,来最大化RTX 4090的算力,以便在有限的资源下做到高效生产。如果未来市场上出现更高效、更适合我需求的显卡,我也会根据实际情况进行调整和优化,但当前,RTX 4090无疑是我AI开发的重要工具。接下来,我将根据这些标准,逐步筛选出适合我需求的硬件配置,以期找到最优解。

AI 性能对比
| 显卡型号 | AI 算力 (TOPS) |
|---|---|
| RTX 5090 | 3352 |
| RTX 5090D | 2375 |
| RTX 4090 | 1321 |
| RTX 4090D | 1177 |
分析
- RTX 5090 在 AI 算力方面依然是最强大的,达到了 3352 TOPS。这得益于其最新的 Blackwell 架构和更多的 Tensor 核心。
- RTX 5090D 的 AI 算力为 2375 TOPS,虽然比 RTX 5090 低,但仍然比 RTX 4090 和 RTX 4090D 高出很多。
- RTX 4090 的 AI 算力为 1321 TOPS,相比 RTX 5090 系列有较大差距。
- RTX 4090D 的 AI 算力为 1177 TOPS,是 RTX 4090 的“青春版”,AI 算力也有所缩减。
结论
从 AI 算力来看,RTX 5090 > RTX 5090D > RTX 4090 > RTX 4090D。
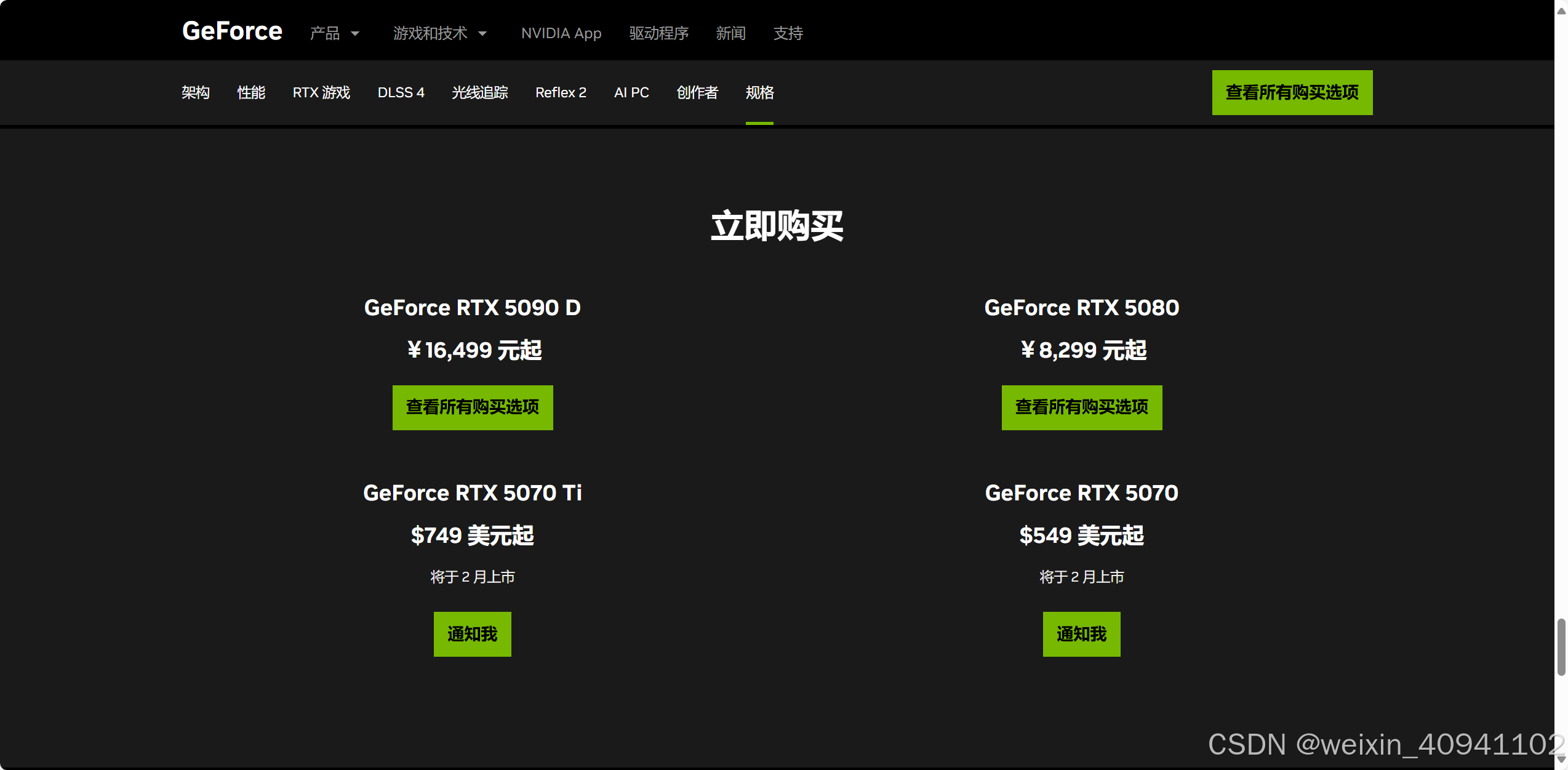
现在国内可以在京东预约抢购5090D显卡。虽然它的算力不如5090,但作为从业者能买到的性价比最高的显卡,已经非常符合我的需求。考虑到预算和性能的平衡,5090D显卡提供了一个相对合理的选择,尤其在AI开发和深度学习任务中,尽管与5090相比有一定差距,但依然能满足大部分的计算需求。
对于个人开发者而言,想要在预算有限的情况下获得高性能硬件,5090D显卡的发布无疑是一个重要的机会。虽然它可能不具备5090那样顶级的性能,但作为中高端显卡,性能足以支撑大规模的AI训练与推理任务,特别是采用混合精度训练的情况下,能充分利用显存,保证高效运算。
此外,考虑到当前显卡市场的动荡,能够购买到5090D这样一款高性能显卡,将有助于我在接下来的项目中更好地提升开发效率和工作产出。尽管RTX 4090已经是我当前AI开发的重要工具,但如果能顺利抢购到5090D,我会将其作为未来工作的备选硬件,进一步优化工作流,并进行不同显卡在各种任务中的性能对比和调优。
总的来说,5090D显卡不仅在性价比上比其他高端显卡更具优势,而且也是我作为从业者能够以合理价格获得的一款值得投资的硬件。如果能成功入手,未来我的AI开发将更加高效,能够应对更多复杂的计算任务。

















 442
442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









