








论文地址:https://openaccess.thecvf.com/content/CVPR2022/html/Zamir_Restormer_Efficient_Transformer_for_High-Resolution_Image_Restoration_CVPR_2022_paper.html
源码地址:https://github.com/swz30/Restormer
概述
图像恢复任务旨在从受到各种扰动(噪声、模糊、雨滴等)影响的低质量图像中恢复出高质量图像,该任务需要强大的先验知识作为引导。基于卷积神经网络的方法感受野受限,无法对像素间的长程依赖进行建模,且在推理过程卷积核的参数固定,无法应对多变的输入内容。相对而言,Transformer中的自注意力机制可以解决以上的问题,而传统的Transformer空间注意力计算过程显存消耗大。为了解决以上的问题,文中提出一种高效的Transformer框架(Restormer)用于图像恢复任务。该框架主要包含两个核心组件:多深度卷积头转置注意力(MDTA)模块和门控深度卷积前馈网络(GDFN)模块。
- MDTA在特征维度上计算每个通道之间的协方差来得到一个注意力矩阵,用于对输入的特征加权。该注意力矩阵的大小只和通道数有关,降低了计算复杂度。此外,MDTA模块在计算协方差之前,还使用了1×1卷积和深度卷积来对输入的特征进行局部的混合,这样可以增强特征的空间信息,同时也可以隐含地模拟全局的像素关系。
- GDFN用于增强特征的表达能力,通过使用了一个门控机制(即两个线性投影层的元素级乘积,其中一个投影层经过了GELU激活函数)控制信息的流动,抑制不重要的特征,而让有用的特征向前传递。此外,GDFN模块使用深度卷积来对特征进行局部的融合,从而平衡空间和通道的信息。
得益于以上模块的引入,模型在保持计算效率的同时,能够捕捉图像中的局部和全局的像素关系,从而提高图像恢复的质量。在多个数据集上的实验结果表明,该模型可以达到了最先进的性能表现。
模型架构
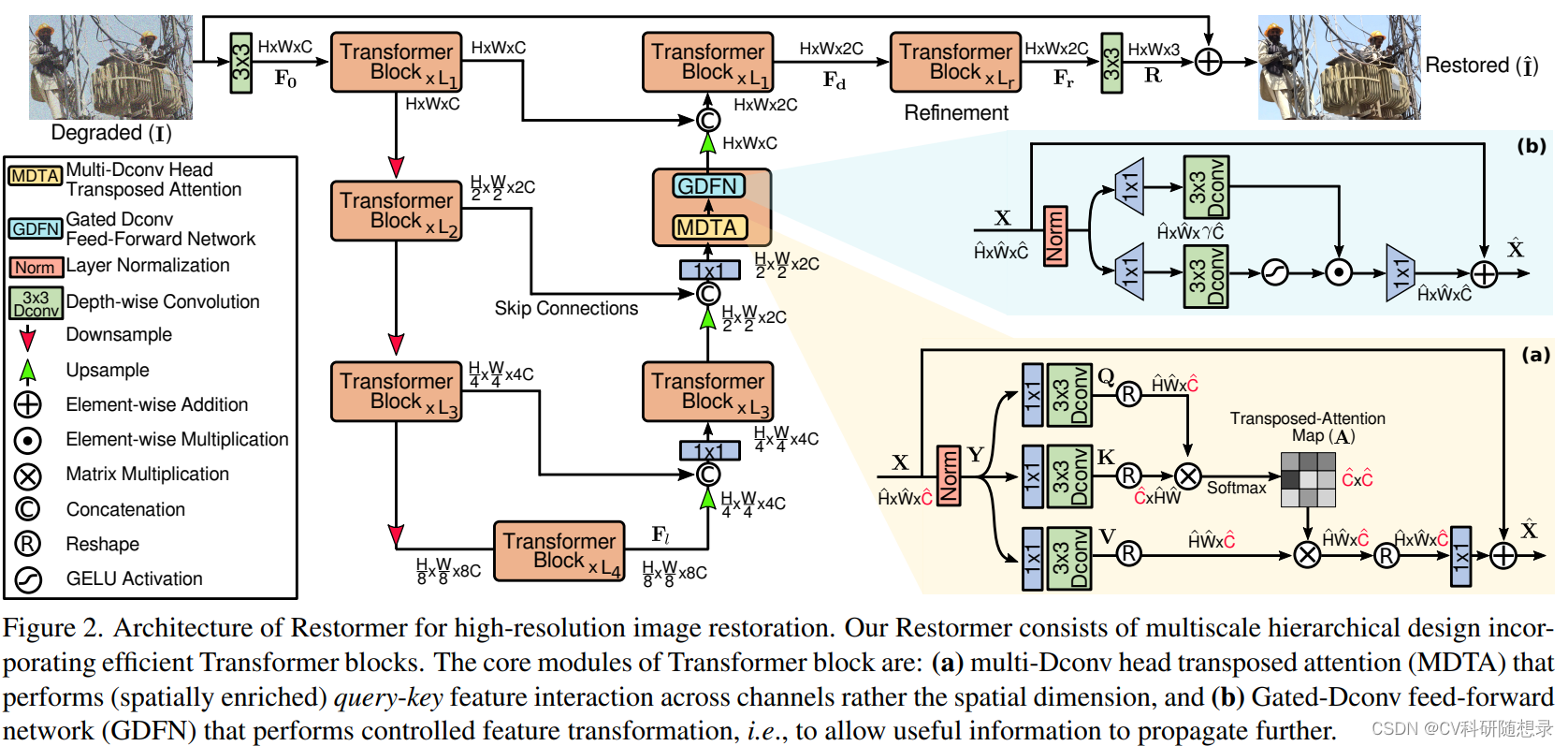
给定输入图像
I
∈
R
H
×
W
×
3
\mathbf{I}\in\mathbb{R}^{H\times W\times3}
I∈RH×W×3 ,Restormer将输入图像送入特征编码层得到浅层编码特征
F
0
∈
R
H
×
W
×
C
\mathbf{F_0}\in\mathbb{R}^{H\times W\times C}
F0∈RH×W×C。继而将
F
0
\mathbf{F_0}
F0 送入4层的对称编码解码结构中提取深层特征
F
d
∈
R
H
×
W
×
2
C
\mathbf{F_d}\in\mathbb{R}^{H\times W\times 2C}
Fd∈RH×W×2C . 每层编解码结构包含多个Transformer块,其中块的数量是从上到下递增模式,以提高模型的效率,经过编码器之后的特征维度为
F
l
∈
R
H
8
×
W
8
×
8
C
\mathbf{F}_l\in\mathbb{R}^{\frac H8\times\frac W8\times8C}
Fl∈R8H×8W×8C. 然后将下采样后的特征送入解码器中逐渐恢复高分辨率图像。Restormer使用 pixel-unshuffle 与 pixel-shuffle 来实现特征图的上采样与下采样,并借鉴UNet的形式,使用跳跃链接链接编码器与解码器的特征。在拼接特征之前使用
1
×
1
1\times 1
1×1 卷积将输入特征通道减半。在顶层将浅层特征与深层特征融合得到
F
d
\mathbf{F_d}
Fd,保留图像中的细节纹理信息。将
F
d
\mathbf{F_d}
Fd 送入视差精细化模块中得到细化特征后送入
3
×
3
3\times 3
3×3的卷积层生成残差图
R
∈
R
H
×
W
×
3
\mathbf{R}\in\mathbb{R}^{H\times W\times3}
R∈RH×W×3。残差图与原图像相加后得到最后的恢复图像。
Multi-Dconv Head Transposed Attention

MDTA 的核心思想是在多头自注意力层中,采用跨通道的自注意力机制来替代跨空间维度的自注意力机制,从而实现线性复杂度。此外,使用深度可分离卷积来增强局部上下文信息。
对于输入
X
X
X经过层归一化后得到
Y
∈
R
H
^
×
W
^
×
C
^
\mathbf{Y}\in\mathbb{R}^{\hat{H}\times\hat{W}\times\hat{C}}
Y∈RH^×W^×C^,然后分别经过3个卷积块(
1
×
1
1\times 1
1×1卷积与
3
×
3
3\times 3
3×3 通道可分离卷积)分支得到
Q
K
V
\mathbf{QKV}
QKV即
Q
=
W
d
Q
W
p
Q
Y
,
K
=
W
d
K
W
p
K
Y
a
n
d
V
=
W
d
V
W
p
V
Y
\mathbf{Q}\mathrm{=}W_d^QW_p^Q\mathbf{Y},\mathbf{K}\mathrm{=}W_d^KW_p^K\mathbf{Y}\mathrm{~and~}\mathbf{V}\mathrm{=}W_d^VW_p^V\mathbf{Y}
Q=WdQWpQY,K=WdKWpKY and V=WdVWpVY。对
Q
K
\mathbf{QK}
QK后进行维度变换后进行点乘得到转置注意力
A
∈
R
C
^
×
C
^
A\in \mathbb{R}^{\hat{C}\times\hat{C}}
A∈RC^×C^,整体的MDTA可以表示为:
X
^
=
W
p
Attention
(
Q
^
,
K
^
,
V
^
)
+
X
,
Attention
(
Q
^
,
K
^
,
V
^
)
=
V
^
⋅
Softmax
(
K
^
⋅
Q
^
/
α
)
,
(1)
\begin{aligned}\hat{\mathbf{X}}&=W_p\operatorname{Attention}\left(\hat{\mathbf{Q}},\hat{\mathbf{K}},\hat{\mathbf{V}}\right)+\mathbf{X},\\\operatorname{Attention}\left(\hat{\mathbf{Q}},\hat{\mathbf{K}},\hat{\mathbf{V}}\right)&=\hat{\mathbf{V}}\cdot\operatorname{Softmax}\left(\hat{\mathbf{K}}\cdot\hat{\mathbf{Q}}/\alpha\right),\end{aligned}\tag{1}
X^Attention(Q^,K^,V^)=WpAttention(Q^,K^,V^)+X,=V^⋅Softmax(K^⋅Q^/α),(1)
其中
X
\mathbf{X}
X 与
X
^
\mathbf{\hat{X}}
X^ 为输入与输出特征图。
Q
^
∈
R
H
^
W
^
×
C
^
;
K
^
∈
R
C
^
×
H
^
W
^
;
V
^
∈
R
H
^
W
^
×
C
^
\hat{\mathbf{Q}}\in\mathbb{R}^{\hat{H}\hat{W}\times\hat{C}};\hat{\mathbf{K}}\in\mathbb{R}^{\hat{C}\times\hat{H}\hat{W}};\hat{\mathbf{V}}\in\mathbb{R}^{\hat{H}\hat{W}\times\hat{C}}
Q^∈RH^W^×C^;K^∈RC^×H^W^;V^∈RH^W^×C^。
α
\alpha
α 是一个可学习的缩放参数,用于控制在应用softmax函数之前,
K
^
\mathbf{\hat{K}}
K^和
Q
^
\mathbf{\hat{Q}}
Q^点积的大小。这样可以调节注意力的分布,避免过大或过小的值影响梯度更新。
Gated-Dconv Feed-Forward Network

前馈网络(FN)是传统的Transformer模型的一个基本组件,用于对每个像素位置的特征进行独立的线性变换。它使用两个1×1卷积,一个用于扩展特征通道(通常是输入通道的
γ
γ
γ倍,
γ
=
4
γ=4
γ=4),另一个用于将通道数降回输入维度。在两个卷积之间,还应用了一个非线性激活函数。在这项工作中,作者对FN进行了两个重要的改进,以提高表示学习的效果:(1)门控机制,和(2)深度卷积,如图2(b)所示。门控机制是由两个平行的线性变换层的逐元素乘积构成的,其中一个变换层使用了GELU非线性激活函数。门控机制的作用是控制信息流的方向和强度,即抑制不重要的特征,只让有用的信息向网络的更深层传递。这样可以让每一层网络专注于学习更细粒度的图像属性,从而提高图像恢复的质量。深度卷积的作用是在进行线性变换之前,对每个通道的特征进行空间上的邻域聚合,以学习局部的图像结构。这样可以结合卷积的优势,增强特征的空间上下文。给定输入
X
∈
R
H
^
×
W
^
×
C
^
,
\mathbf{X}\in\mathbb{R}^{\hat{H}\times\hat{W}\times\hat{C}},
X∈RH^×W^×C^, GDFN模块可以表示为:
X
^
=
W
p
0
Gating
(
X
)
+
X
,
Gating
(
X
)
=
ϕ
(
W
d
1
W
p
1
(
L
N
(
X
)
)
)
⊙
W
d
2
W
p
2
(
L
N
(
X
)
)
,
(2)
\begin{aligned} \hat{\mathbf{X}}& =W_p^0\text{ Gating }(\mathbf{X})+\mathbf{X}, \\ \operatorname{Gating}(\mathbf{X})& =\phi(W_d^1W_p^1(\mathrm{LN}(\mathbf{X})))\odot W_d^2W_p^2(\mathrm{LN}(\mathbf{X})), \end{aligned}\tag{2}
X^Gating(X)=Wp0 Gating (X)+X,=ϕ(Wd1Wp1(LN(X)))⊙Wd2Wp2(LN(X)),(2)
其中
⊙
\odot
⊙ 表示 element-wise 乘积。
ϕ
\phi
ϕ 表示GELU非线性激活层。
L
N
\mathrm{LN}
LN 表示层归一化。GDFN通过门控机制和深度卷积,对输入的特征进行有选择的信息流动和空间上下文增强。这样可以提高特征的表达能力和图像恢复的质量。GDFN在网络中起着不同于MDTA的作用。MDTA主要是用于丰富特征的全局上下文,而GDFN主要是用于控制特征的局部细节。这两个模块相互补充,共同实现高效的图像恢复。由于GDFN相比于传统的FN进行了更多的操作,作者降低了通道扩展因子γ,以保持类似的参数量和计算量以避免过拟合和过度计算的问题。
Progressive Learning
渐进式学习的基本思想是,根据图像恢复的难度,动态地调整训练时的图像块大小。在训练的早期阶段,使用较小的图像块,以便快速学习一些基本的图像特征和先验。在训练的后期阶段,逐渐增大图像块的大小,以便捕获更多的全局图像统计信息和细节信息。渐进式学习可以让Transformer模型适应不同分辨率的图像,从而在测试时提高图像恢复的质量。渐进式学习的策略类似于课程学习的过程,即让模型从简单的任务开始,逐渐过渡到复杂的任务。这样可以避免模型在训练初期受到过于复杂或噪声的图像的干扰,而在训练后期又可以提高模型的泛化能力和鲁棒性。渐进式学习的一个挑战是,随着图像块大小的增加,训练的时间和内存消耗也会增加。为了解决这个问题,文中在增大图像块大小的同时,减小批量大小,以保持每个优化步骤的时间和内存消耗与固定图像块训练相近。使得可以在不牺牲效率的情况下,实现渐进式学习的目标。
实验结果
























 642
642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











