









1. 简介
Direct Preference Optimization(DPO) ,通过直接优化语言模型以符合人类偏好,无需显性奖励模型或强化学习。该算法隐式地优化与现有 RLHF 算法相同的目标(奖励最大化,带有 KL 散度约束),但易于实现且容易训练。
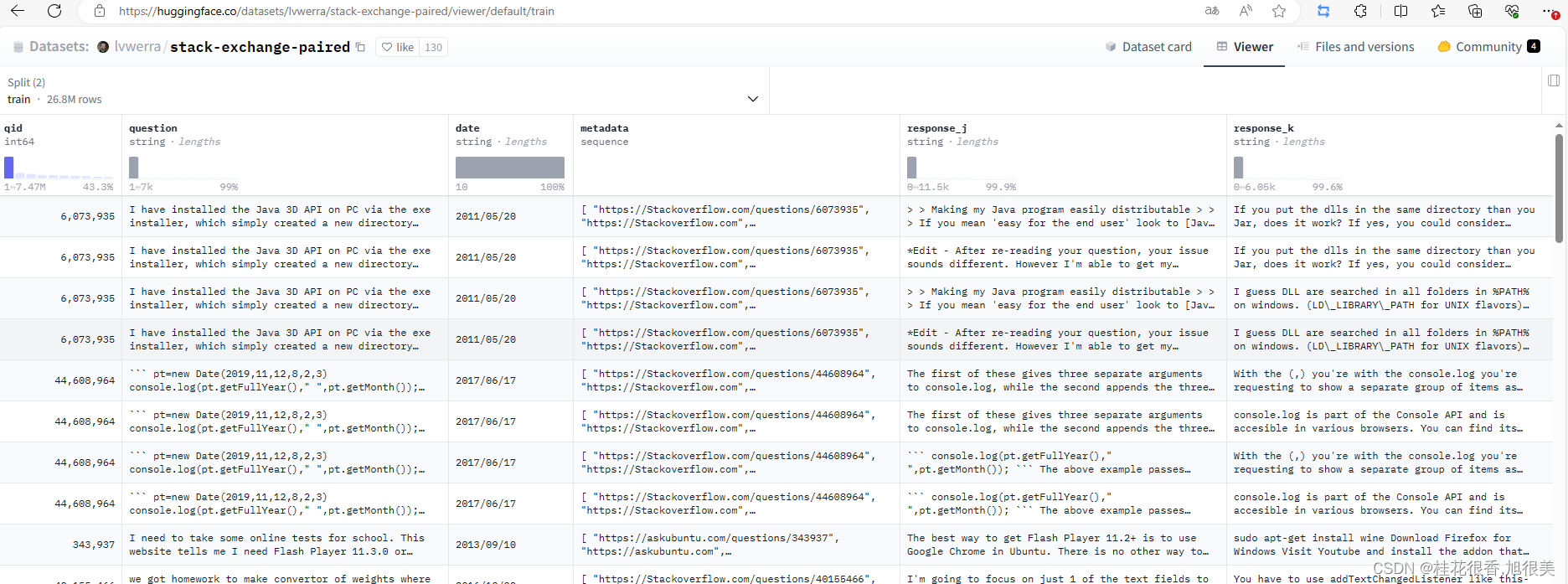
直接偏好优化 (Direct Preference Optimization,DPO) 法在 stack-exchange preference 数据集上微调最新的 Llama v2 7B 模型, stack-exchange preference 数据集中包含了各个 stack-exchange 门户上的各种问题及其排序后的回答。
stack-exchange preference 数据样式:
2. DPO 与 PPO
在通过 RL 优化人类衍生偏好时,一直以来的传统做法是使用一个辅助奖励模型来微调目标模型,以通过 RL 机制最大化目标模型所能获得的奖励。直观上,我们使用奖励模型向待优化模型提供反馈,以促使它多生成高奖励输出,少生成低奖励输出。同时,我们使用冻结的参考模型来确保输出偏差不会太大,且继续保持输出的多样性。这通常需要在目标函数设计时,除了奖励最大化目标外再添加一个相对于参考模型的 KL 惩罚项,这样做有助于防止模型学习作弊或钻营奖励模型。
DPO 绕过了建模奖励函数这一步,这源于一个关键洞见: 从奖励函数到最优 RL 策略的分析映射。这个映射直观地度量了给定奖励函数与给定偏好数据的匹配程度。有了它,作者就可与将基于奖励和参考模型的 RL 损失直接转换为仅基于参考模型的损失,从而直接在偏好数据上优化语言模型!因此,DPO 从寻找最小化 RLHF 损失的最佳方案开始,通过改变参量的方式推导出一个 仅需 参考模型的损失!
有了它,我们可以直接优化该似然目标,而不需要奖励模型或繁琐的强化学习优化过程。
3. 使用 TRL 进行训练
一个典型的 RLHF 流水线通常包含以下几个环节:
- 有监督微调 (supervised fine-tuning,
SFT) - 用偏好标签标注数据
- 基于偏好数据训练奖励模型
- RL 优化
DPO 训练直接消灭了奖励建模和 RL 这两个环节 (环节 3 和 4),直接根据标注好的偏好数据优化 DPO 目标。
使用 DPO,我们仍然需要执行环节 1,但我们仅需在 TRL 中向 DPOTrainer 提供环节 2 准备好的偏好数据,而不再需要环节 3 和 4。标注好的偏好数据需要遵循特定的格式,它是一个含有以下 3 个键的字典:
- prompt : 即推理时输入给模型的提示
- chosen : 即针对给定提示的较优回答
- rejected : 即针对给定提示的较劣回答或非给定提示的回答, 需要注意的是,单个提示可能对应于数据集数组中的多个响应,这在数据集的数组中反映了重复的条目。
数据例子:
dpo_dataset_dict = {
"prompt": ["hello", "how are you", …],
"chosen": ["hi, nice to meet you", "I am fine", …],
"rejected": ["leave me alone", "I am not fine", …],
}
对于 stack-exchange preference 数据集,我们可以通过以下工具函数将数据集中的样本映射至上述字典格式并删除所有原始列:
from transformers import AutoModelForCausalLM
from datasets import load_dataset
from trl import SFTTrainer
def return_prompt_and_responses(samples) -> Dict[str, str, str]:
return {
"prompt": [
"Question: " + question + "\n\nAnswer: "
for question in samples["question"]
],
"chosen": samples["response_j"], # rated better than k
"rejected": samples["response_k"], # rated worse than j
}
dataset = load_dataset(
"lvwerra/stack-exchange-paired",
split="train",
data_dir="data/rl"
)
original_columns = dataset.column_names
dataset.map(
return_prompt_and_responses,
batched=True,
remove_columns=original_columns
)
一旦有了排序数据集,DPO 损失其实本质上就是一种有监督损失,其经由参考模型获得隐式奖励。因此,从上层来看,DPOTrainer 需要我们输入待优化的基础模型以及参考模型:
dpo_trainer = DPOTrainer(
model, # 经 SFT 的基础模型
model_ref, # 一般为经 SFT 的基础模型的一个拷贝
beta=0.1, # DPO 的温度超参
train_dataset=dataset, # 上文准备好的数据集
tokenizer=tokenizer, # 分词器
args=training_args, # 训练参数,如: batch size, 学习率等
)
其中,超参 beta 是 DPO 损失的温度,通常在 0.1 到 0.5 之间。它控制了我们对参考模型的关注程度,beta 越小,我们就越忽略参考模型。对训练器初始化后,我们就可以简单调用以下方法,使用给定的 training_args 在给定数据集上进行训练了:
dpo_trainer.train()
4. 基于 Llama v2 进行实验
在 TRL 中实现 DPO 训练器的好处:可以利用 TRL 及其依赖库 (如 Peft 和 Accelerate) 中已有的 LLM 相关功能。有了这些库,我们甚至可以使用 bitsandbytes 库提供的 QLoRA 技术 来训练 Llama v2 模型。
4.1 有监督微调
先用 TRL 的 SFTTrainer 在 SFT 数据子集上使用 QLoRA 对 7B Llama v2 模型进行有监督微调:
# load the base model in 4-bit quantization
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
base_model = AutoModelForCausalLM.from_pretrained(
script_args.model_name, # "meta-llama/Llama-2-7b-hf"
quantization_config=bnb_config,
device_map={"": 0},
trust_remote_code=True,
use_auth_token=True,
)
base_model.config.use_cache = False
# add LoRA layers on top of the quantized base model
peft_config = LoraConfig(
r=script_args.lora_r,
lora_alpha=script_args.lora_alpha,
lora_dropout=script_args.lora_dropout,
target_modules=["q_proj", "v_proj"],
bias="none",
task_type="CAUSAL_LM",
)
...
trainer = SFTTrainer(
model=base_model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
peft_config=peft_config,
packing=True,
max_seq_length=None,
tokenizer=tokenizer,
args=training_args, # HF Trainer arguments
)
trainer.train()
#trainer.save_model()
4.2 DPO 训练
SFT 结束后,我们保存好生成的模型。接着,我们继续进行 DPO 训练,我们把 SFT 生成的模型作为 DPO 的基础模型和参考模型,并在上文生成的 stack-exchange preference 数据上,以 DPO 为目标函数训练模型。我们选择对模型进行 LoRa 微调,因此我们使用 Peft 的 AutoPeftModelForCausalLM 函数加载模型:
model = AutoPeftModelForCausalLM.from_pretrained(
script_args.model_name_or_path, # location of saved SFT model
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
load_in_4bit=True,
is_trainable=True,
)
model_ref = AutoPeftModelForCausalLM.from_pretrained(
script_args.model_name_or_path, # same model as the main one
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
load_in_4bit=True,
)
...
dpo_trainer = DPOTrainer(
model,
model_ref,
args=training_args,
beta=script_args.beta,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
peft_config=peft_config,
)
dpo_trainer.train()
dpo_trainer.save_model()
以 4 比特的方式加载模型,然后通过 peft_config 参数选择 QLora 方法对其进行训练。训练器(dpo_trainer)还会用评估数据集评估训练进度,并报告一些关键指标,例如可以选择通过 WandB 记录并显示隐式奖励。最后,我们可以将训练好的模型推送到 HuggingFace Hub。
4.3 Merging the adaptors
python examples/research_projects/stack_llama/scripts/merge_peft_adapter.py --base_model_name="meta-llama/Llama-2-7b-hf" --adapter_model_name="dpo/final_checkpoint/" --output_name="stack-llama-2"
4.4 Running the model
加载DPO训练步骤保存的经过DPO训练的LoRA适配器,并通过以下方式加载:
加载DPO训练步骤保存的经过DPO训练的LoRA适配器,并通过以下方式加载:
补充
SFT 和 DPO 训练脚本的完整源代码可在该目录 examples/stack_llama_2 处找到,训好的已合并模型也已上传至 HF Hub (见 此处)。
你可以在 这儿 找到模型在训练过程的 WandB 日志,其中包含了 DPOTrainer 在训练和评估期间记录下来的以下奖励指标:
- rewards/chosen (较优回答的奖励) : 针对较优回答,策略模型与参考模型的对数概率二者之差的均值,按 beta 缩放。
- rewards/rejected (较劣回答的奖励) : 针对较劣回答,策略模型与参考模型的对数概率二者之差的均值,按 beta 缩放。
- rewards/accuracy (奖励准确率) : 较优回答的奖励大于相应较劣回答的奖励的频率的均值
- rewards/margins (奖励余裕值) : 较优回答的奖励与相应较劣回答的奖励二者之差的均值。
直观上讲,在训练过程中,希望余裕值增加并且准确率达到 1.0,换句话说,较优回答的奖励高于较劣回答的奖励 (或余裕值大于零)。随后还可以在评估数据集上计算这些指标。
stack_llama/scripts/merge_peft_adapter.py:
from dataclasses import dataclass, field
from typing import Optional
import torch
from peft import PeftConfig, PeftModel
from transformers import AutoModelForCausalLM, AutoModelForSequenceClassification, AutoTokenizer, HfArgumentParser
@dataclass
class ScriptArguments:
"""
The input names representing the Adapter and Base model fine-tuned with PEFT, and the output name representing the
merged model.
"""
adapter_model_name: Optional[str] = field(default=None, metadata={"help": "the adapter name"})
base_model_name: Optional[str] = field(default=None, metadata={"help": "the base model name"})
output_name: Optional[str] = field(default=None, metadata={"help": "the merged model name"})
parser = HfArgumentParser(ScriptArguments)
script_args = parser.parse_args_into_dataclasses()[0]
assert script_args.adapter_model_name is not None, "please provide the name of the Adapter you would like to merge"
assert script_args.base_model_name is not None, "please provide the name of the Base model"
assert script_args.output_name is not None, "please provide the output name of the merged model"
peft_config = PeftConfig.from_pretrained(script_args.adapter_model_name)
if peft_config.task_type == "SEQ_CLS":
# The sequence classification task is used for the reward model in PPO
model = AutoModelForSequenceClassification.from_pretrained(
script_args.base_model_name, num_labels=1, torch_dtype=torch.bfloat16
)
else:
model = AutoModelForCausalLM.from_pretrained(
script_args.base_model_name, return_dict=True, torch_dtype=torch.bfloat16
)
tokenizer = AutoTokenizer.from_pretrained(script_args.base_model_name)
# Load the PEFT model
model = PeftModel.from_pretrained(model, script_args.adapter_model_name)
model.eval()
model = model.merge_and_unload()
model.save_pretrained(f"{script_args.output_name}")
tokenizer.save_pretrained(f"{script_args.output_name}")
model.push_to_hub(f"{script_args.output_name}", use_temp_dir=False)
参考
stack-exchange preference 数据集
trainer 文档
v4.40.2/src/transformers/trainer.py
sft_trainer.py
dpo_trainer.py
直接偏好优化(DPO):让语言模型拥有更好的奖励机制
使用 DPO 微调 Llama 2
Fine-tune Llama 2 with DPO
SFT 和 DPO 训练脚本的完整源代码


















 1554
1554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









