







原文:我是如何赢得GPT-4提示工程大赛冠军的
原文的原文: How I Won Singapore’s GPT-4 Prompt Engineering Competition
- 插件:OpenAI 为 GPT-4 版本的 ChatGPT 提供的 Advanced Data Analysis(高级数据分析)插件 —— 高级(付费用户)可以使用。这让用户可以向 ChatGPT 上传数据集,然后直接在数据集上运行代码,实现精准的数据分析。
1 . LLM 不擅长的数据集分析类型
LLM 执行准确数学计算的能力有限,这使得它们不适合需要对数据集进行精确定量分析的任务,比如:
描述性统计数值计算:以定量方式总结数值列,使用的度量包括均值或方差。相关性分析: 获得列之间的精确相关系数。统计分析:比如假设测试,可以确定不同数据点分组之间是否存在统计学上的显著差异。机器学习:在数据集上执行预测性建模,可以使用的方法包括线性回归、梯度提升树或神经网络。
2. LLM 擅长的数据集分析类型
LLM 擅长识别模式和趋势。这种能力源自 LLM 训练时使用的大量多样化数据,这让它们可以识别出可能并不显而易见的复杂模式。
异常检测:基于一列或多列数值识别偏离正常模式的异常数据点。聚类:基于列之间的相似特征对数据点进行分组。跨列关系:识别列之间的综合趋势。文本分析(针对基于文本的列): 基于主题或情绪执行分类。趋势分析(针对具有时间属性的数据集):识别列之中随时间演进的模式、季节变化或趋势。
3. 仅使用 LLM 来分析 Kaggle 数据集
真实世界 Kaggle 数据集,是为客户个性分析任务收集整理的,其中的任务目标是对客户群进行细分,以更好地了解客户。
取用一个子集验证 LLM 的分析结果,其中包含 50 行和最相关的列。之后,用于分析的数据集如下所示,其中每一行都代表一个客户,列则描述了客户信息:
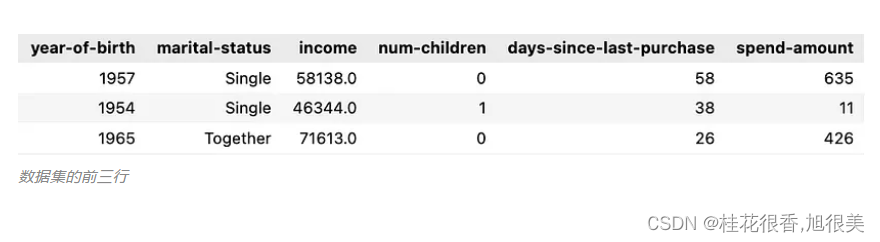
假设你的任务:使用这个客户信息数据集来指导营销工作。
这个任务分为两步:
- 第一步,使用数据集生成有意义的细分客户群。
- 第二步,针对每个细分群生成最好的营销策略。
现在,这个问题就成了模式发现(第一步)的实际业务问题,这也正是 LLM 擅长的能力。
下面针对这个任务草拟一个 prompt,这里用到了 4 种提示工程技术(后面还有更多!):
- 将复杂任务
分解为简单步骤 - 索引每一步的
中间输出 - 设置 LLM 的
响应的格式 - 将
指令与数据集分离开
#System Prompt:
I want you to act as a data scientist to analyze datasets. Do not make up information that is not in the dataset. For each analysis I ask for, provide me with the exact and definitive answer and do not provide me with code or instructions to do the analysis on other platforms.
#Prompt:
# CONTEXT #
I sell wine. I have a dataset of information on my customers: [year of birth, marital status, income, number of children, days since last purchase, amount spent].
#############
# OBJECTIVE #
I want you use the dataset to cluster my customers into groups and then give me ideas on how to target my marketing efforts towards each group. Use this step-by-step process and do not use code:
1. CLUSTERS: Use the columns of the dataset to cluster the rows of the dataset, such that customers within the same cluster have similar column values while customers in different clusters have distinctly different column values. Ensure that each row only belongs to 1 cluster.
For each cluster found,
2. CLUSTER_INFORMATION: Describe the cluster in terms of the dataset columns.
3. CLUSTER_NAME: Interpret [CLUSTER_INFORMATION] to obtain a short name for the customer group in this cluster.
4. MARKETING_IDEAS: Generate ideas to market my product to this customer group.
5. RATIONALE: Explain why [MARKETING_IDEAS] is relevant and effective for this customer group.
#############
# STYLE #
Business analytics report
#############
# TONE #
Professional, technical
#############
# AUDIENCE #
My business partners. Convince them that your marketing strategy is well thought-out and fully backed by data.
#############
# RESPONSE: MARKDOWN REPORT #
<For each cluster in [CLUSTERS]>
— Customer Group: [CLUSTER_NAME]
— Profile: [CLUSTER_INFORMATION]
— Marketing Ideas: [MARKETING_IDEAS]
— Rationale: [RATIONALE]
<Annex>
Give a table of the list of row numbers belonging to each cluster, in order to back up your analysis. Use these table headers: [[CLUSTER_NAME], List of Rows].
#############
# START ANALYSIS #
If you understand, ask me for my dataset.
翻译:
#System Prompt:
我想让你扮演数据科学家的角色来分析数据集。不要编造数据集中没有的信息。对于我要求的每一项分析,都要向我提供准确而明确的答案,不要向我提供在其他平台上进行分析的代码或说明。
#Prompt
#上下文#
我卖葡萄酒。我有一个关于我的客户的信息数据集:[出生年份、婚姻状况、收入、子女数量、自上次购买以来的天数、消费金额]。
#############
#目标#
我希望您使用该数据集将我的客户分组,然后就如何将我的营销工作针对每个群体给出想法。使用此分步过程,不要使用代码:
1.CLUSTERS:使用数据集的列对数据集的行进行聚类,使得同一集群内的客户具有相似的列值,而不同集群中的客户具有明显不同的列值。确保每一行只属于一个集群。
对于找到的每个聚类,
2.CLUSTER_INFORMATION:根据数据集列来描述集群。
3.CLUSTER_NAME:解释[CLUSTER_INFORMATION]以获得该集群中客户组的短名称。
4.营销创意:产生创意,将我的产品推向这个客户群。
5.理由:解释为什么[MARKETING_IDEAS]与该客户群体相关且有效。
#############
#风格#
业务分析报告
#############
#语气#
专业、技术
#############
#受众#
我的商业伙伴。让他们相信你的营销策略是经过深思熟虑的,并且有充分的数据支持。
#############
#响应:降价报告#
<对于[CLUSTERS]>中的每个集群
--客户组:[CLUSTER_NAME]
--配置文件:[CLUSTER_INFORMATION]
--营销理念:[Marketing_Ideas]
--理由:[理由]
附件
给出属于每个集群的行号列表,以支持您的分析。使用以下表格标题:[[CLUSTER_NAME],行列表]。
#############
#启动分析#
如果你理解,请向我索取我的数据集。
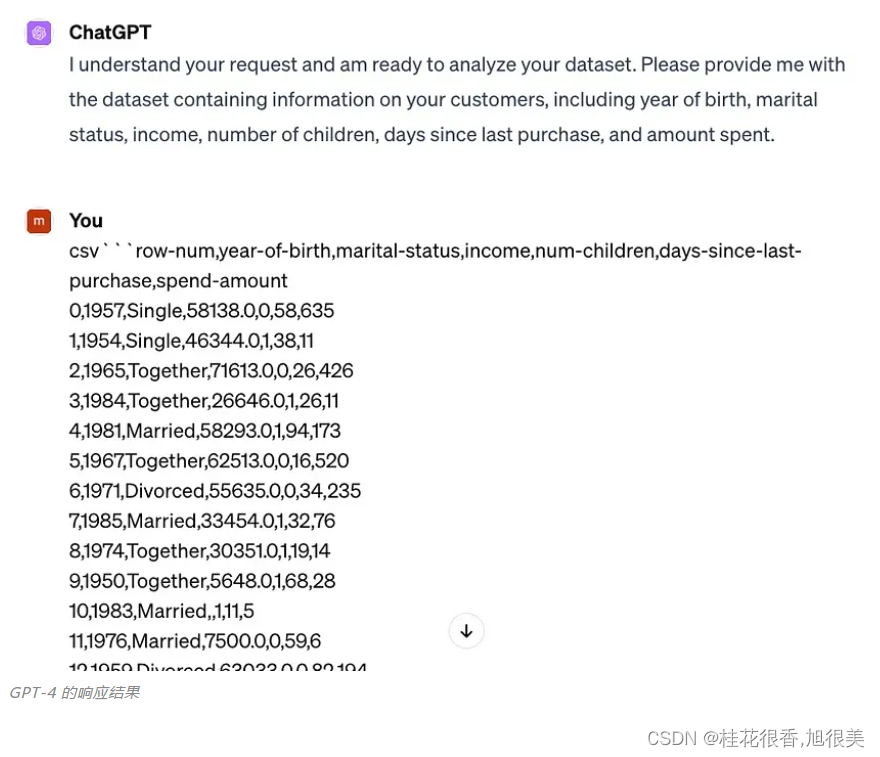
GPT-4 的回复如下,我们继续以 CSV 字符串的形式向其传递数据集。
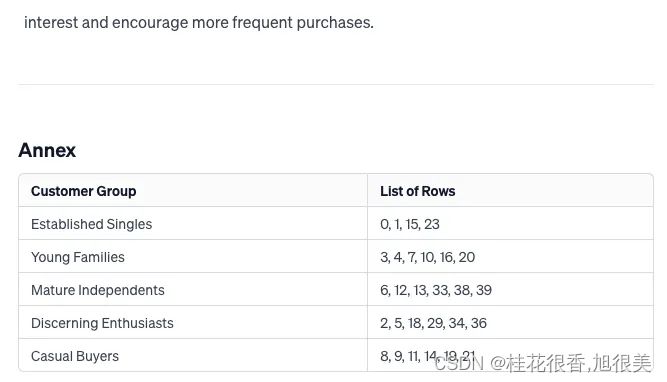
之后,GPT-4 以我们要求的 markdown 报告格式回复其分析结果:


4. 验证 LLM 的分析结果
为了简单起见将选取 LLM 生成的 2 个客户群来进行验证,即年轻家庭(Young Families)和高品位爱好者(Discerning Enthusiasts)。
4.1 年轻家庭
- LLM 分析出的人群画像:1980 年后出生,已婚或同居,中低收入,频繁进行小额购买。
- 被 LLM 聚类到这一分组的行:3, 4, 7, 10, 16, 20
- 深入研究这些数据集,这些行的完整数据为:
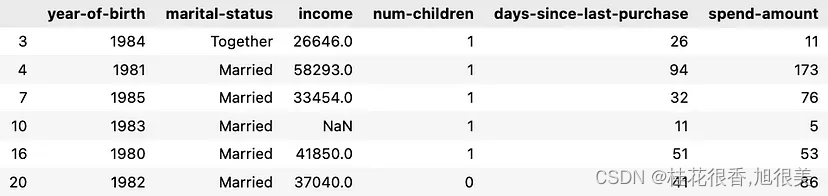
其刚好对应于 LLM 识别出的人群画像。它甚至能在不事先预处理的情况下聚类空值行!
4.2 高品位爱好者
- LLM 分析出的人群画像:年轻范围广,任意婚姻状况,高收入,不同的子女情况,购物支出高。
- 被 LLM 聚类到这一分组的行:2, 5, 18, 29, 34, 36
- 深入研究这些数据集,这些行的完整数据为:
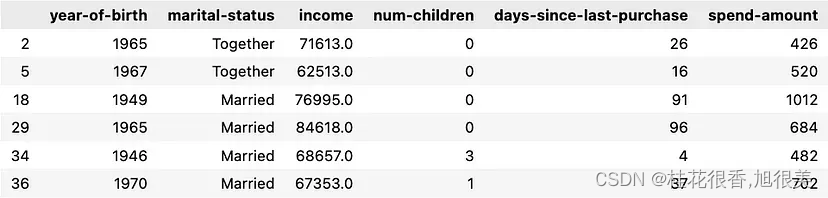
这同样与 LLM 识别出的人群画像非常符合!
这个例子彰显了 LLM发现模式的能力,其能从多维度的数据集中解读和提炼出有意义的见解,这能确保其分析深深植根于数据集的事实真相。
补充:对于 3 中的prompt分解关键性prompt技术
技术 1:将复杂任务分解为简单步骤
比如上面prompt中的 OBJECTIVE 模块
#############
# OBJECTIVE #
I want you use the dataset to cluster my customers into groups and then give me ideas on how to target my marketing efforts towards each group. Use this step-by-step process and do not use code:
1. CLUSTERS: Use the columns of the dataset to cluster the rows of the dataset, such that customers within the same cluster have similar column values while customers in different clusters have distinctly different column values. Ensure that each row only belongs to 1 cluster.
For each cluster found,
2. CLUSTER_INFORMATION: Describe the cluster in terms of the dataset columns.
3. CLUSTER_NAME: Interpret [CLUSTER_INFORMATION] to obtain a short name for the customer group in this cluster.
4. MARKETING_IDEAS: Generate ideas to market my product to this customer group.
5. RATIONALE: Explain why [MARKETING_IDEAS] is relevant and effective for this customer group.
#############
翻译:
#############
#目标#
我希望您使用该数据集将我的客户分组,然后就如何将我的营销工作针对每个群体给出想法。使用此分步过程,不要使用代码:
1.CLUSTERS:使用数据集的列对数据集的行进行聚类,使得同一集群内的客户具有相似的列值,而不同集群中的客户具有明显不同的列值。确保每一行只属于一个集群。
对于找到的每个聚类,
2.CLUSTER_INFORMATION:根据数据集列来描述集群。
3.CLUSTER_NAME:解释[CLUSTER_INFORMATION]以获得该集群中客户组的短名称。
4.营销创意:产生创意,将我的产品推向这个客户群。
5.理由:解释为什么[MARKETING_IDEAS]与该客户群体相关且有效。
#############
这里没直接简单地给 LLM 提供一个整体的任务描述,比如「将客户聚类成不同的客户群,然后针对每个客户群给出营销见解。」
通过使用逐步指示,LLM 更有可能给出正确结果。
技术 2:索引每一步的中间输出
在为 LLM 提供逐步过程时,给出了每一步的中间输出结果,其中用的大写变量名指代,即 CLUSTERS、CLUSTER_INFORMATION、CLUSTER_NAME、MARKETING_IDEAS 和 RATIONALE。
使用大写可以将这些变量名与指令主体区分开。然后,可以通过加方括号的形式 [变量名] 索引这些中间输出。
技术 3:设置 LLM 的响应的格式
上面要求输出 markdown 报告格式,这能美化 LLM 的响应结果。在这里,中间输出的变量名再次派上用场,可以更方便地指定报告的结构。
# RESPONSE: MARKDOWN REPORT #
<For each cluster in [CLUSTERS]>
— Customer Group: [CLUSTER_NAME]
— Profile: [CLUSTER_INFORMATION]
— Marketing Ideas: [MARKETING_IDEAS]
— Rationale: [RATIONALE]
<Annex>
Give a table of the list of row numbers belonging to each cluster, in order to back up your analysis. Use these table headers: [[CLUSTER_NAME], List of Rows].
事实上,你之后也可以让 ChatGPT 提供可下载的报告文件,让其直接完成你的最终报告。

技术 4:将任务指令与数据集分离开
可以看到,我们从未在第一个 prompt 中向 LLM 提供数据集。相反,该 prompt 只给出了数据集分析的任务指令,最后再加上了以下内容:
# START ANALYSIS #
If you understand, ask me for my dataset.
然后,ChatGPT 答复它理解了,然后我们再在下一个 prompt 中以 CSV 字符串的形式将数据集传递给它。
4.1 但为什么要将任务指令与数据集分离开?
这样做有助于 LLM 清晰理解每一部分,降低遗漏信息的可能性;尤其是当任务更复杂时,例如例子中这个指令较长的任务。你可能经历过 LLM「意外遗忘」长 prompt 中某个特定指令的情况。
举个例子:如果你让 LLM 给出 100 词的响应,但其反馈的结果却长得多。而如果让 LLM 先接收指令,然后再接收指令处理的数据集,就能让 LLM 先消化其应当做的事情,之后再基于后面提供的数据集来执行它。
请注意,这种指令与数据集分离的操作仅适用于有对话记忆的聊天式 LLM,不适用于没有对话记忆的任务完成式 LLM。


















 2341
2341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









