






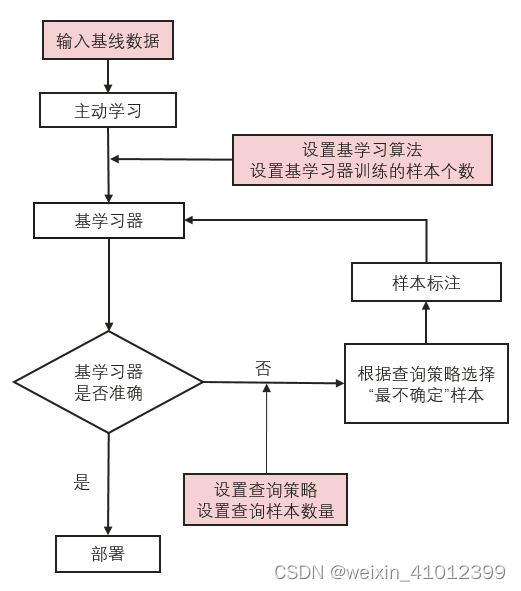
active learning与passive(supervised) learning最大的不同是其不需要大量的专家标注样本训练模型。 主动学习是利用少量标注样本,然后由模型(Learner)主动选择hard sample返回给用户或专家(Oracle)打标签,进而不断迭代以获得较好的模型,该过程必须要有Oracle的参与,这也是active learning区别于semi-supervised learning的不同之处。
主动学习:首先采用比如15%的数据训练出一个基学习器,然后基学习器基于某种查询策略主动在真实数据集中挑选基学习器难以区分的样本,交给Oracle进行标注,然后一步步迭代更新模型,最终采用较少的数据便可以训练出一个回归模型使得其在真实数据集上得到较好的表现。
参考:https://zhuanlan.zhihu.com/p/172479306
https://blog.csdn.net/qq_35759272/article/details/119887099
方法. MI-AOD——《Multiple Instance Active Learning for Object Detection》
标题:用于目标检测的多实例主动学习
论文:https://arxiv.org/pdf/2104.02324.pdf
代码:https://github.com/yuantn/MI-AOD
详细解读:知乎:MI-AOD: 少量样本实现高检测性能
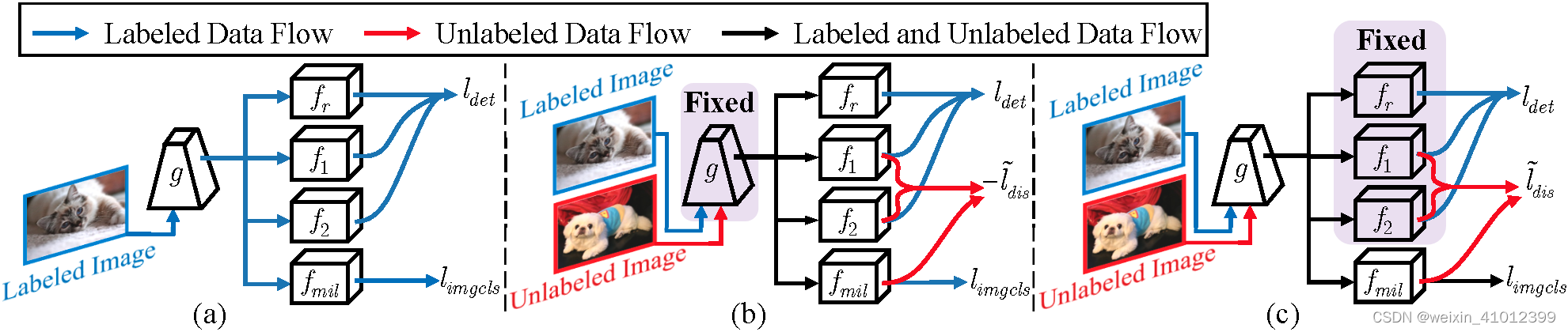
1.一小部分有标注数据和一大部分未标注数据。每张图片的标签的bbox加class。
2.用这些有标签的数据初始化一个模型M_0,对于初始化的模型M0,主动学习的目标是从未标注数据中选择一组要手动标记的图像,并将其与标注数据合并,以获得新的标记集X_L1。所选图像集应该是信息量最大的,即可以尽可能提高检测性能。
3.上图中的信息性体现为不确定性。也就是说,将未标注数据中的样本输入到当前模型中,如果每个类的模型输出得分更均匀,则该样本的不确定性更高。
4.用手动更新完的X_L1重新更新模型M1。模型训练和样本选择重复一些周期,直到标记集的大小达到注释预算。
5.MI-AOD定义了一个不确定性学习模块,该模块训练两个对抗性分类器来预测未标记集的实例不确定性。MI-AOD将未标记的图像视为实例包,将图像中的特征锚定视为实例,并以多实例学习(MIL)的方式重新加权来估计图像的不确定性。迭代不确定性学习和重新加权有助于抑制噪声实例,从而弥合实例不确定性和图像级不确定性之间的差距。

















 734
734

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









