






参考:https://blog.csdn.net/DD_PP_JJ/article/details/111829869
https://blog.csdn.net/weixin_54048889/article/details/127934092
一、分析GPU
nvidia-smi
二、分析CPU使用率
htop
查看cpu96个核的使用率
三、分析磁盘IO
apt-get install iotop
iotop
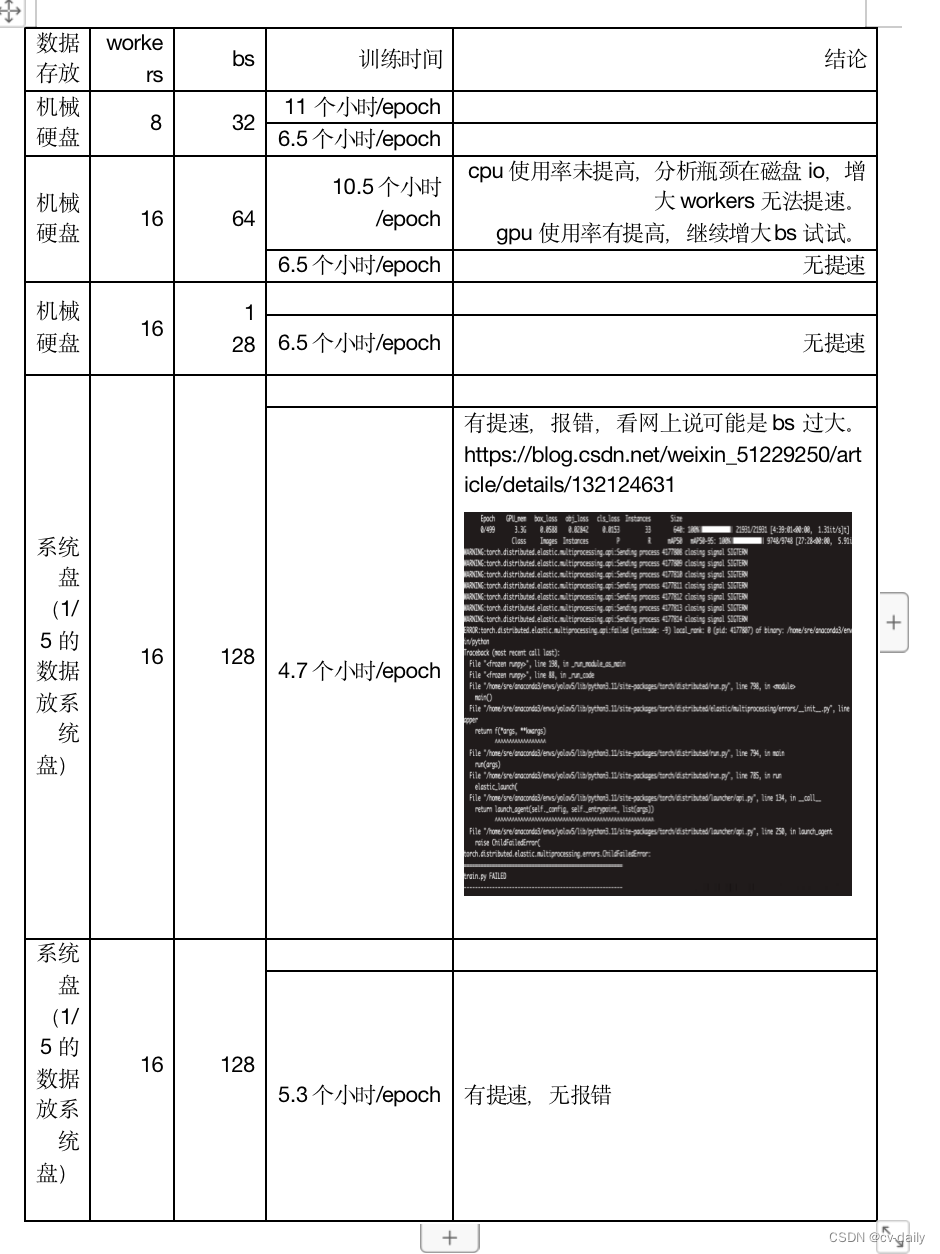
分析GPU和CPU都没有使用完,瓶颈在磁盘IO。
DDR3内存读写速度大概10G每秒(10000M)
固态硬盘速度是300M每秒,是内存的三十分之一
机械硬盘的速度是100M每秒,是内存的百分之一
linux测试系统内存和磁盘的读写速度。
测试指令参考:https://www.cnbanwagong.com/linux-speed-test.html
wget -qO- bench.sh | bash ##测试速度

sudo lshw -class disk 查看硬盘类型
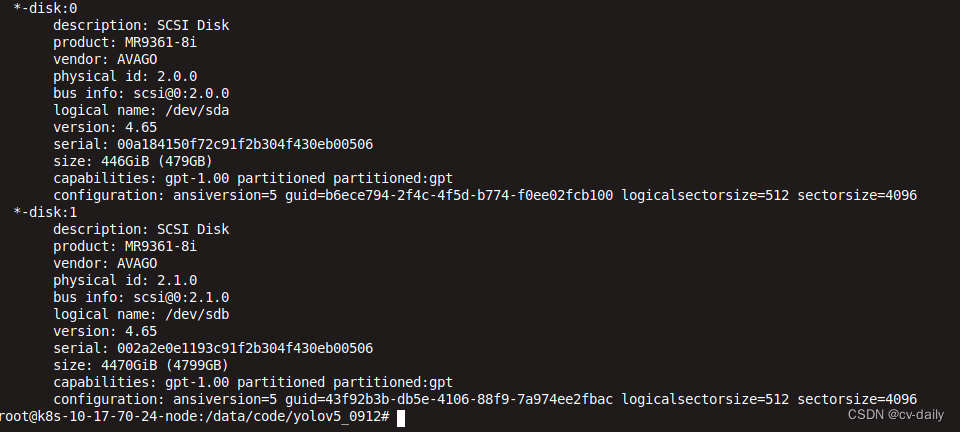 查看硬盘读写速度。
查看硬盘读写速度。
参考:https://baijiahao.baidu.com/s?id=1768766502851278651&wfr=spider&for=pc
hdparm -Tt /dev/sda
上述命令会显示硬盘的缓存读取速度 (Cached Read Speed) 和不带缓存的读取速度 (Buffered Disk Read Speed)。

四、磁盘IO瓶颈解决方法
1、拼成一张图片,
2、多张图内存拼在一起,
3、增大磁盘内存的使用率,把部分数据放在内存条存储上,从内存条上读取数据,可以加快速度。
4、更换更快的硬盘,ssd,nvme硬盘等。
五、其他方法
1、开启图片缓存,会生成图片对应的numpy数据,以后直接读取numpy数据。需要足够大的存储空间。
2、使用混合精度训练试试。yolov5 v7.0代码里支持,默认开启混合精度训练。
amp = check_amp(model) # check AMP
scaler = torch.cuda.amp.GradScaler(enabled=amp)
torch.cuda.amp.GradScaler解析:https://zhuanlan.zhihu.com/p/348554267
3、图片解码加速
PyTorch中默认使用的是Pillow进行图像的解码,但是其效率要比Opencv差一些,如果图片全部是JPEG格式,可以考虑使用TurboJpeg库解码。具体速度对比如下图所示:

对于jpeg读取也可以考虑使用jpeg4py库(pip install jpeg4py),重写一个loader即可。
存bmp图也可以降低解码耗时,其他方案还有recordIO,hdf5,pth,n5,lmdb等格式。
4、数据增强加速,使用dali库(使用gpu进行数据增强操作)
在PyTorch中,通常使用transformer做图片分类任务的数据增强,而其调用的是CPU做一些Crop、Flip、Jitter等操作。如果你通过观察发现你的CPU利用率非常高,GPU利用率比较低,那说明瓶颈在于CPU预处理,可以使用Nvidia提供的DALI库在GPU端完成这部分数据增强操作。
Dali链接:https://github.com/NVIDIA/DALI
文档也非常详细:
Dali文档:https://docs.nvidia.com/deeplearning/sdk/dali-developer-guide/index.html
当然,Dali提供的操作比较有限,仅仅实现了常用的方法,有些新的方法比如cutout需要自己搞。
具体实现可以参考这一篇:https://zhuanlan.zhihu.com/p/77633542
5、 data Prefetch
Nvidia Apex中提供的解决方案
参考来源:https://zhuanlan.zhihu.com/p/66145913
我们能看到 Nvidia 是在读取每次数据返回给网络的时候,预读取下一次迭代需要的数据,那么对我们自己的训练代码只需要做下面的改造:
training_data_loader = DataLoader(
dataset=train_dataset,
num_workers=opts.threads,
batch_size=opts.batchSize,
pin_memory=True,
shuffle=True,
)
for iteration, batch in enumerate(training_data_loader, 1):
# 训练代码
#-------------升级后---------
data, label = prefetcher.next()
iteration = 0
while data is not None:
iteration += 1
# 训练代码
data, label = prefetcher.next()
安装:
pip install prefetch_generator
使用:
from torch.utils.data import DataLoader
from prefetch_generator import BackgroundGenerator
class DataLoaderX(DataLoader):
def __iter__(self):
return BackgroundGenerator(super().__iter__())
然后用DataLoaderX替换原本的DataLoader
六、如何测试训练过程的瓶颈
参考:https://blog.csdn.net/DD_PP_JJ/article/details/111829869
https://blog.csdn.net/wizardforcel/article/details/88321661
1、https://www.cnblogs.com/lfri/p/15586649.html
python -m torch.utils.bottleneck 待测脚本路径
2、
python -m cProfile -o 100_percent_gpu_utilization.prof train.py
3、复杂的(比如多GPU)
torch.autograd.profiler.profile().
这些只能看到程序运行的耗时,不能从这些里边看出瓶颈在磁盘io吧。
















 4875
4875











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









