






一、nvidia-smi参数详解
参考:https://www.cnblogs.com/freedom-w/articles/17867561.html
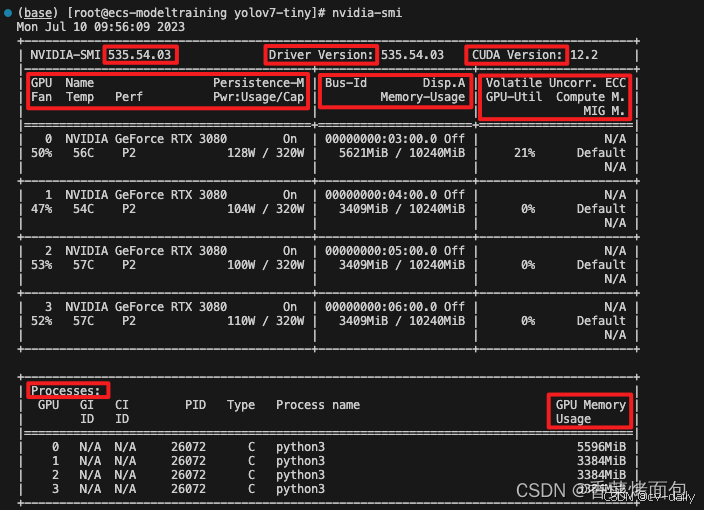
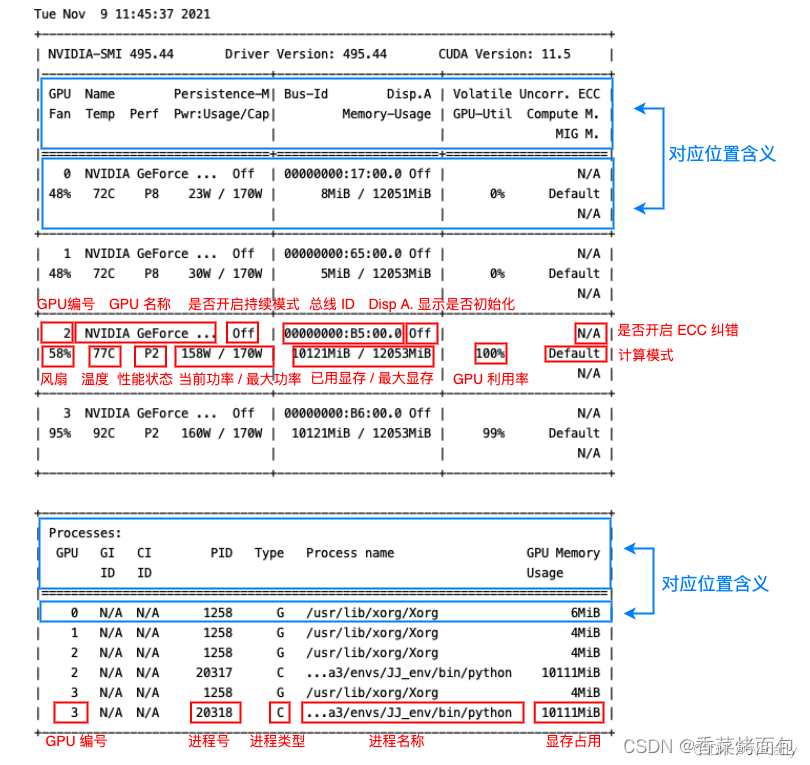
GPU:本机中的GPU编号,从0开始,上图为0,1,2,3四块GPU
Fan:风扇转速(0%-100%),N/A表示没有风扇
Name:GPU名字/类型,上图四块均为NVIDIA GeForce RTX 3080
Temp:GPU温度(GPU温度过高会导致GPU频率下降)
Perf:性能状态,从P0(最大性能)到P12(最小性能),上图均为P2
Pwr:Usager/Cap:GPU功耗,Usage表示用了多少,Cap表示总共多少
Persistence-M:持续模式状态,持续模式耗能大,但在新的GPU应用启动时花费时间更少,上图均为On
Bus-Id:GPU总线
Disp.A:Display Active,表示GPU是否初始化
Memory-Usage:显存使用率
Volatile GPU-UTil:GPU使用率,与显存使用率的区别可参考显存与GPU
Uncorr. ECC:是否开启错误检查和纠错技术,0/DISABLED,1/ENABLED,上图均为N/A
Compute M:计算模式,0/DEFAULT,1/EXCLUSIVE_PROCESS,2/PROHIBITED,上图均为Default
Processes:显示每个进程占用的显存使用率、进程号、占用的哪个GPU
-h 查看帮助手册:nvidia-smi -h
动态地观察 GPU 的状态:watch -n 0.5 nvidia-smi
-i 查看指定GPU:nvidia-smi -i 0
-L 查看GPU列表及其UUID:nvidia-smi -L
-l 指定动态刷新时间,默认5秒刷新一次,通过Ctrl+C停止:nvidia-smi -l 5
-q 查询GPU详细信息:nvidia-smi -q
只列出某一GPU的详细信息,可使用 -i 选项指定:nvidia-smi -q -i 0
在所有 GPU 上启用持久性模式:nvidia-smi -pm 1
指定开启某个显卡的持久模式:nvidia-smi -pm 1 -i 0
以 1 秒的更新间隔监控整体 GPU 使用情况:nvidia-smi dmon
以 1 秒的更新间隔监控每个进程的 GPU 使用情况:nvidia-smi pmon
- 显存与GPU的区别
显存(Video RAM,VRAM)和 GPU(Graphics Processing Unit)是计算机图形处理中的两个不同概念。
显存(VRAM):显存是一种特殊类型的内存,用于存储图形数据和纹理等与图像显示相关的数据。它通常位于独立的显卡(或显卡集成在主板上的集成图形处理器)中,也被称为图形存储器。显存具有高带宽和低延迟的特点,可用于快速读取和写入图像数据,以供 GPU 进行图形渲染和处理。显存的容量通常以兆字节(MB)或千兆字节(GB)为单位。
GPU(图形处理单元):GPU 是一种专门设计用于处理图形和图像数据的处理器。它是计算机图形渲染和加速的关键组件。GPU 负责执行图形渲染管线中的各个阶段,包括几何计算、光栅化、像素处理等,以生成最终的图像。GPU 还能执行通用计算任务,因此在许多领域,如科学计算、机器学习和密码破解等,GPU 也被广泛应用。显存是 GPU 的一部分,用于存储 GPU 处理所需的图形数据。
总结起来,显存是一种专门用于存储图形数据的内存,而 GPU 是一种专门用于处理图形和图像数据的处理器。显存和 GPU 是紧密相关的,GPU 使用显存来存储和处理图形数据,以实现高性能的图形渲染和处理能力。
二、GPU和显存分析
参考:https://mp.weixin.qq.com/s?__biz=MzU0NjgzMDIxMQ==&mid=2247618711&idx=2&sn=d5fefa822200b43466bf11ce81ffaa31&chksm=fa3789b51da1040bb20a7f79e71ccedaba1c3ab045969aa6a061b91195d4ae1b72ee62adc839&scene=27
显存占用和GPU利用率是两个不一样的东西,显卡是由GPU计算单元和显存等组成的,显存和GPU的关系有点类似于内存和CPU的关系。
如何提高显存利用率?
如何提高GPU使用率?
如果根据模型参数量估计训练时显存占用?显存占用包括三部分:参数占用+梯度与动量占用+输入输出显存占用
参数占用显存 = 参数数目×n
n = 4 :float32
n = 2 : float16
n = 8 : double64
在PyTorch中,当你执行完model=MyGreatModel().cuda()之后就会占用相应的显存,占用的显存大小基本与上述分析的显存差不多(会稍大一些,因为其它开销)。
深度学习中神经网络的显存占用,我们可以得到如下公式:
显存占用 = 模型显存占用 + batch_size × 每个样本的显存占用
可以看出显存不是和batch-size简单的成正比,尤其是模型自身比较复杂的情况下:比如全连接很大,Embedding层很大。
3.1 建议
时间更宝贵,尽可能使模型变快(减少flop)
显存占用不是和batch size简单成正比,模型自身的参数及其延伸出来的数据也要占据显存
batch size越大,速度未必越快。在你充分利用计算资源的时候,加大batch size在速度上的提升很有限
尤其是batch-size,假定GPU处理单元已经充分利用的情况下:
增大batch size能增大速度,但是很有限(主要是并行计算的优化)
增大batch size能减缓梯度震荡,需要更少的迭代优化次数,收敛的更快,但是每次迭代耗时更长。
增大batch size使得一个epoch所能进行的优化次数变少,收敛可能变慢,从而需要更多时间才能收敛(比如batch_size 变成全部样本数目)。

















 1934
1934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









