







 1. Computer Vision计算机视觉包括: --图片分类(图片识别)Image classification --目标检测 object detection --神经风格迁移 neural style transfer,如合成图片创造新的艺术风格计算机视觉面临的一个挑战是输入数据较大,这就带来两个问题,一是神经网络复杂,参数较多,容易发生过拟合,二是计算量大所需内存也多,解决方法就...
1. Computer Vision计算机视觉包括: --图片分类(图片识别)Image classification --目标检测 object detection --神经风格迁移 neural style transfer,如合成图片创造新的艺术风格计算机视觉面临的一个挑战是输入数据较大,这就带来两个问题,一是神经网络复杂,参数较多,容易发生过拟合,二是计算量大所需内存也多,解决方法就...
计算机视觉包括:
--图片分类(图片识别)Image classification
--目标检测 object detection
--神经风格迁移 neural style transfer,如合成图片创造新的艺术风格

计算机视觉面临的一个挑战是输入数据较大,这就带来两个问题,一是神经网络复杂,参数较多,容易发生过拟合,二是计算量大所需内存也多,解决方法就是卷积神经网络。
2. Edge Detection Example边缘检测示例
本节以边缘检测为例说明卷积是怎么回事。
图片的边缘检测可以通过与相应过滤器(有的文章也称之为核)进行卷积来实现。
以垂直边缘检测为例,原始图片尺寸为6x6,过滤器filter尺寸为3x3,卷积后的图片尺寸为4x4,得到结果如下:(注意这里的*表示卷积运算,跟乘法无关,python中,卷积用conv_forward()表示;tensorflow中,卷积用tf.nn.conv2d()表示;keras中,卷积用Conv2D()表示。)
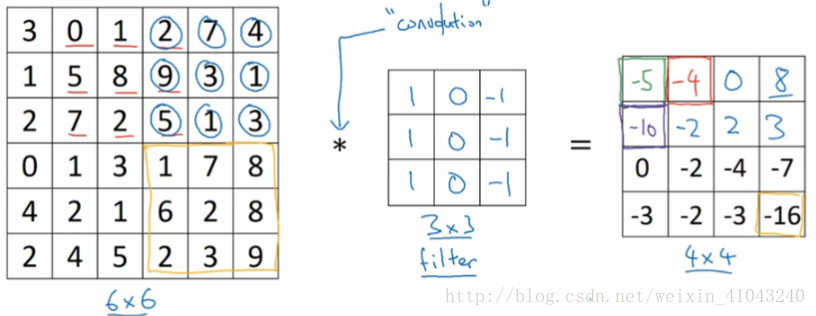
为什么卷积可以检测边缘?
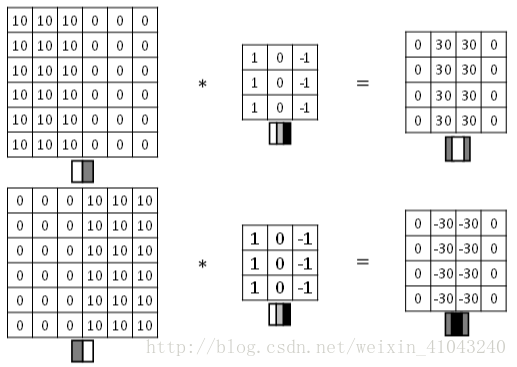
举一个简单的例子,下图最左是原图,可以看出中间有一个明显的竖线,经过卷积得到的图像中间就表示原图的边缘。这里看边缘有些粗,是因为我们的图像太小了,应用到正常图像会发现其检测的边缘相当不错。

本节讲正边和负边的区别,也就是由亮到暗和由暗到亮的区别,以及其他类型的边缘检测。
1)正边和负边
下图展示了两种方式的区别,第一个称为正边,表示图片有亮到暗,第二个称为负边,表示图片由暗到亮。实际应用中,这两种渐变方式并不影响边缘检测结果,如果不在意这种区别的话,可以对输出图片取绝对值操作。
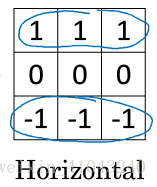
水平边缘检测的过滤器算子如下所示:
除了上面提到的这种简单的Vertical、Horizontal滤波器之外,还有其它常用的filters,例如Sobel filter和Scharr filter。这两种滤波器的特点是增加图片中心区域的权重:

以上是研究者设计好的过滤器算子,在深度学习时代,当检测复杂图像的边缘时,还可以通过反向传播来学习过滤器算子,学习获得的过滤器可能优于任何一个手写的过滤器,因为相对于水平垂直边缘,它可以检测任意倾斜角度的边缘。

按照上面讲的图片卷积,如果原始图片尺寸为n x n,filter尺寸为f x f,则卷积后的图片尺寸为(n-f+1) x (n-f+1),注意f一般为奇数。这样会带来两个问题:
· 每次卷积运算后,输出图片尺寸都会缩小
· 原始图片边缘信息对输出贡献得少,输出图片丢失边缘信息
为了解决这两个问题,可以在卷积之前对图像进行padding(扩充),扩展区域的像素值用0填充,设p为向外拓展的像素数,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1153
1153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









