







原文标题:特征金字塔网络FPN的直觉与架构
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
编者按:深度学习知名博主Jonathan Hui简要介绍了FPN(特征金字塔网络)的直觉、架构和表现。个人理解,本质上是用高层强语义特征增强底层浅语义层,进而提取到更强表现力的特征。本质上是一种加强主干网络CNN特征表达的方法。

检测不同尺度的目标(尤其是其中的小目标)很有挑战性。我们可以使用同一图像的不同尺度版本来检测目标(下图左部)。然而,处理多尺度图像很费时,内存需求过高,难以同时进行端到端训练。因此,我们可能只在推理阶段使用这种方法,以尽可能提高精确度,特别是在竞赛之类不顾及速度的场景中。我们也可以创建特征金字塔来检测目标(下图右部)。然而接近图像的、由低层结构组成的特征映射在精确目标预测上效果不佳。

来源:FPN论文
特征金字塔网络(Feature Pyramid Network, FPN)是为这一金字塔概念设计的特征提取器,设计时考虑到了精确性和速度。它代替了Faster R-CNN之类的检测模型的特征提取器,生成多层特征映射(多尺度特征映射),信息的质量比普通的用于特征检测的特征金字塔更好。
数据流
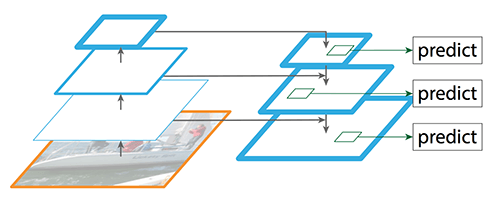
来源:FPN论文
FPN由自底向上和自顶向下两个路径组成。自底向上的路径是通常的提取特征的卷积网络。自底向上,空间分辨率递减,检测更多高层结构,网络层的语义值相应增加。
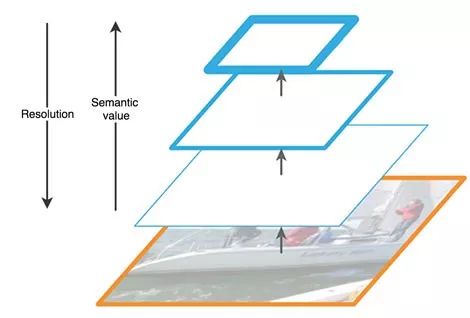
FPN特征提取(修改自FPN论文中的图片)
SSD基于多个特征映射进行检测。然而,低层并不用于目标检测——这些层的分辨率很高,但语义值不够高,因此,为了避免显著的速度下降,目标检测时不使用这些层。因为SSD检测时仅适用高层,所以在小目标上的表现要差很多。

修改自FPN论文中的图片
而FPN提供了自顶向下的路径,基于语义较丰富的层构建分辨率较高的层。

修改自FPN论文中的图片
尽管重建的层语义足够丰富,但经过这些下采样和上采样过程,目标的位置不再准确了。因此FPN在重建层和相应的特征映射间增加了横向连接,以帮助检测器更好地预测位置。这些横向连接同时起到了跳跃连接(skip connection)的作用(类似残差网络的做法)。

修改自FPN论文中的图片
自底向上路径
自底向上路径由很多卷积模块组成,每个模块包含许多卷积层。自底向上的过程中,空间维度逐模块减半(步长翻倍)。每个卷积模块的输出将在自顶向下的路径中使用。
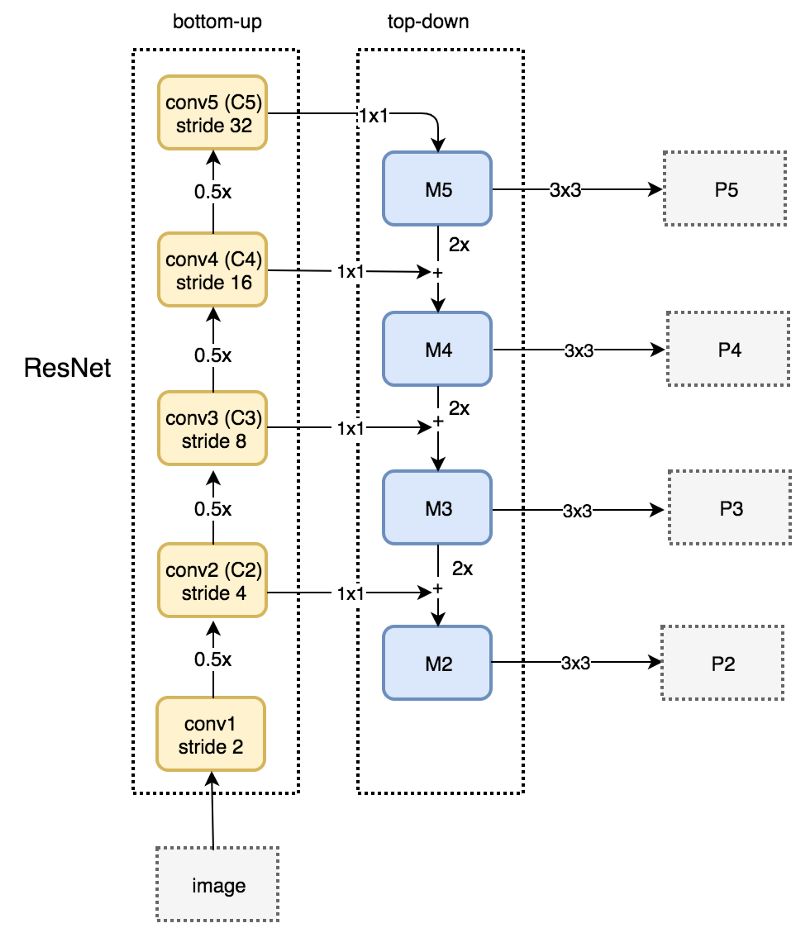
自顶向下路径
上图中,FPN使用一个1x1的卷积过滤器将C5(最上面的卷积模块)的频道深度降至256维,得到M5。接着应用一个3x3的卷积得到P5,P5正是用于目标预测的第一个特征映射。
沿着自顶向下的路径往下,FPN对之前的层应用最近邻上采样(x2)。同时,FPN对自底向上通路中的相应特征映射应用1x1卷积。接着应用分素相加。最后同样应用3x3卷积得到目标检测的特征映射。这一过滤器减轻了上采样的混叠效应。
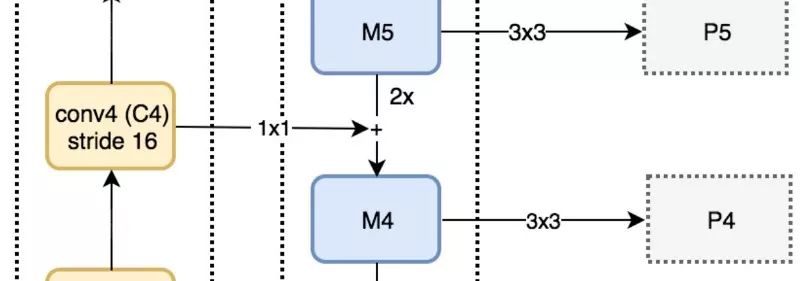
这一过程在P2后停止,因为C1的空间维度太高了。如果不停,依法炮制得到P1的话,会大大拖慢进程。
FPN搭配RPN
FPN自身并不是目标检测器,而是一个配合目标检测器使用的特征检测器。例如,使用FPN提取多层特征映射后将其传给RPN(基于卷积和锚的目标检测器)检测目标。RPN在特征映射上应用3x3卷积,之后在为分类预测和包围盒回归分别应用1x1卷积。这些3x3和1x1卷积层称为RPN头(head)。其他特征映射应用同样的RPN头。
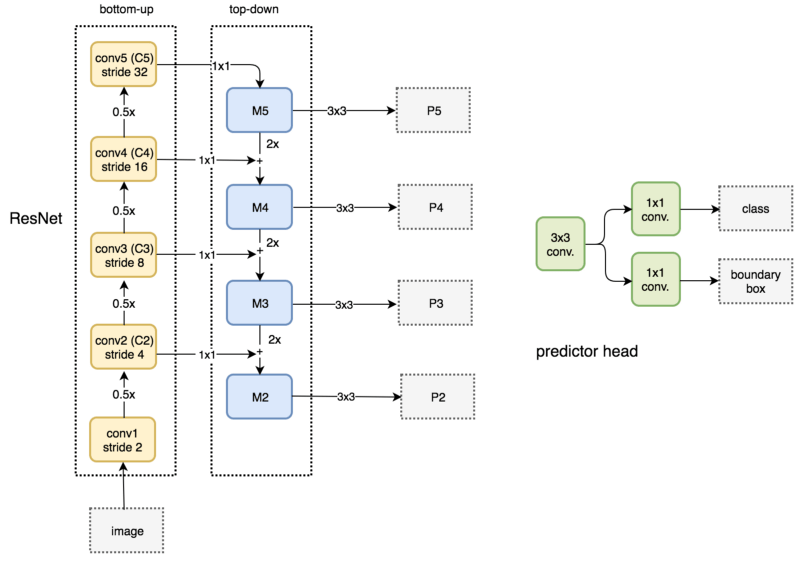
FPN搭配Fast R-CNN和Faster R-CNN
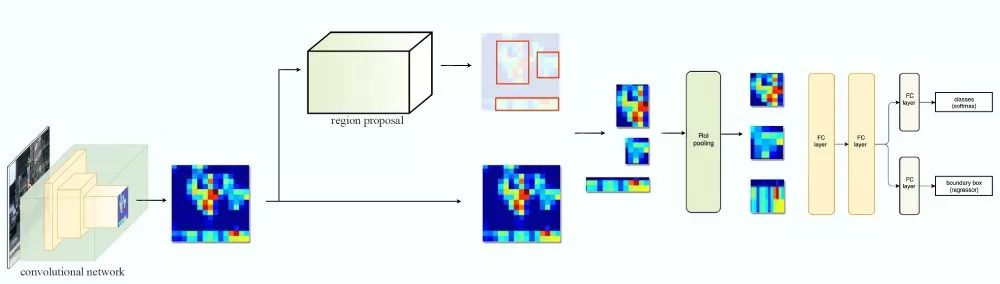
首先简短地概览下Fast R-CNN和Faster R-CNN的数据流。它基于特征映射层创建ROI(感兴趣区域)。然后使用ROI和特征映射层创建特征片,以传给ROI池化。
FPN生成了特征映射金字塔后,应用RPN(见上一节)生成ROI。根据ROI的尺寸,选择最合适的尺度上的特征映射以提取特征片。
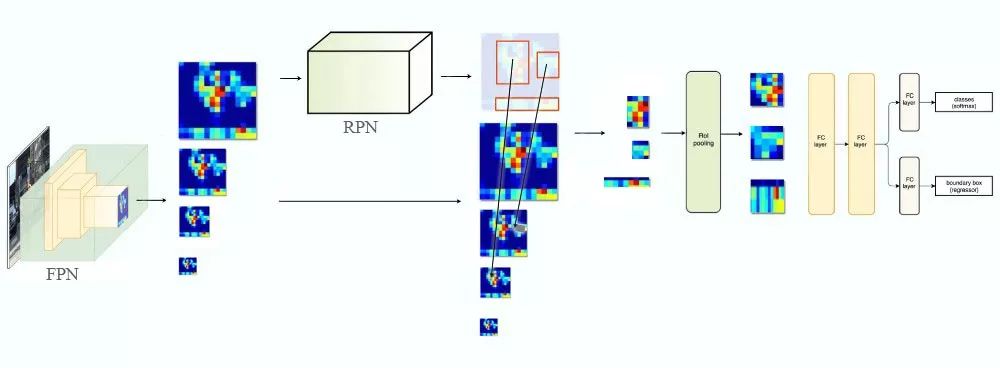
基于ROI尺寸选择特征映射的具体公式为:

其中,w和h为ROI的宽度和高度,k0 = 4,k对应FPN中的Pk层。
所以,如果k = 3,我们将选择P3作为特征映射,应用ROI池化,并将结果传给Fast R-CNN/Faster R-CNN头(两者的头一致),以完成预测。
分割
类似Mask R-CNN,FPN也是一个优良的图像分割提取掩码。下图中,应用5x5的滑窗于特征映射,以生成14x14分割。之后,合并不同尺度的掩码以形成最终的掩码预测。
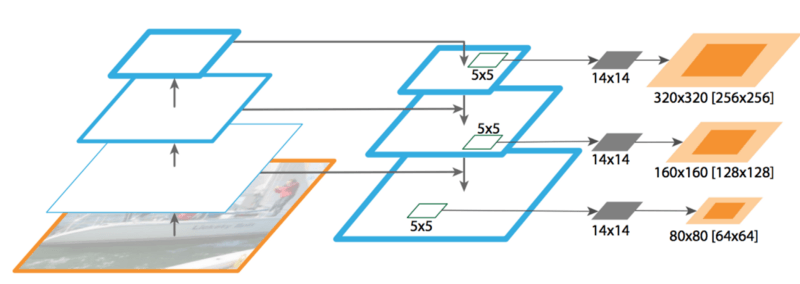
来源:FPN论文
结果
FPN搭配RPN,提升AR(average recall,平均召回)至56.3,相比RPN基线提升了8. 在小目标上的提升更是达到了12.9.

来源:FPN论文
基于FPN的Faster R-CNN的推理时间为0.148秒/张(单Nvidia M40 GPU,ResNet-50),单尺度ResNet-50基线的速度是0.32秒/张。

来源:FPN论文
FPN和当前最先进的检测器实力相当。事实上,FPN击败了COCO 2016和2015挑战的赢家。
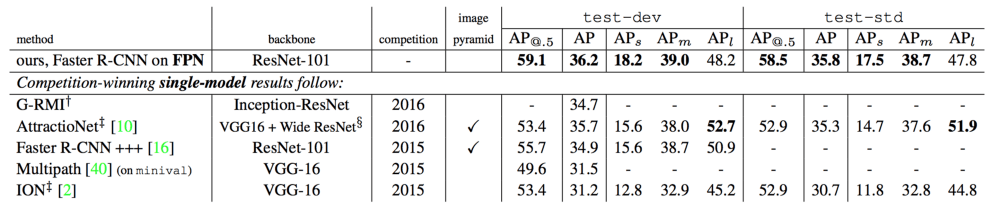
来源:FPN论文
经验总结
下面是从试验数据中总结出的一些经验。
(1)在单个高分辨率特征映射层上增加更多锚不足以提升精确度。
(2)自顶向下路径重建了富含语义信息的分辨率。 但我们需要横向连接,以便将更多准确的目标空间信息加回来。
(3)在COCO数据集上,自顶向下路径和横向连接将精确度提升了8。小目标的提升达到了12.9.
模型实现
用keras写了一个ResNet-FPN,网络层数、参数规模很大,网络复杂度也比较高。
结果图如下所示:

嗯,示意图原图过大,上传不了,粗略截图上传了。
参考:
1.直觉、架构和表现 http://www.elecfans.com/d/724390.html
2. FPN:一种高效的CNN特征提取方法 https://www.jianshu.com/p/5a28ae9b365d















 1497
1497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









