







b站刘二大人《PyTorch深度学习实践》课程第五讲用PyTorch实现线性回归笔记与代码:https://www.bilibili.com/video/BV1Y7411d7Ys?p=5&vd_source=b17f113d28933824d753a0915d5e3a90
PyTorch官网教程:https://pytorch.org/tutorials/beginner/pytorch_with_examples.html
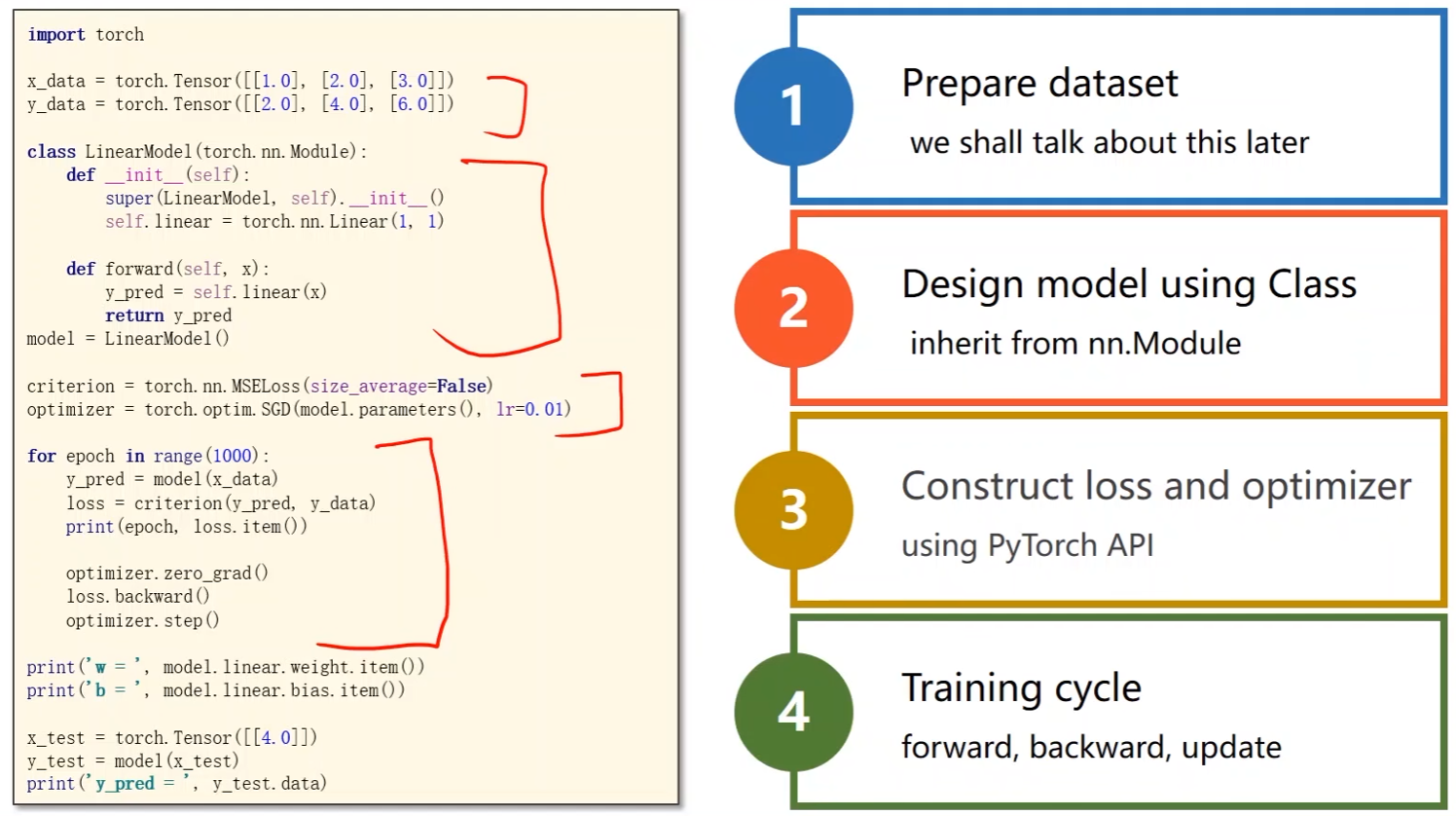
PyTorch Fashion
- 准备数据集
- 设计模型,写成类的形式(nn.Module)
- 前向传播,计算 y ^ \hat{y} y^
- 构造损失函数loss和优化器(使用PyTorch的API)
- 构造loss用于反向传播;优化器用于更新梯度
- 写训练周期(前馈 -> 反馈 -> 更新)
线性回归第一步:准备数据集
- 在PyTorch中,计算图是采用的mini-batch形式计算
import torch
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])
线性回归第二步:设计模型
-
线性单元
- 要确定权重 w w w的维度,则需要知道输入 x x x和输出 y ^ \hat{y} y^的维度;
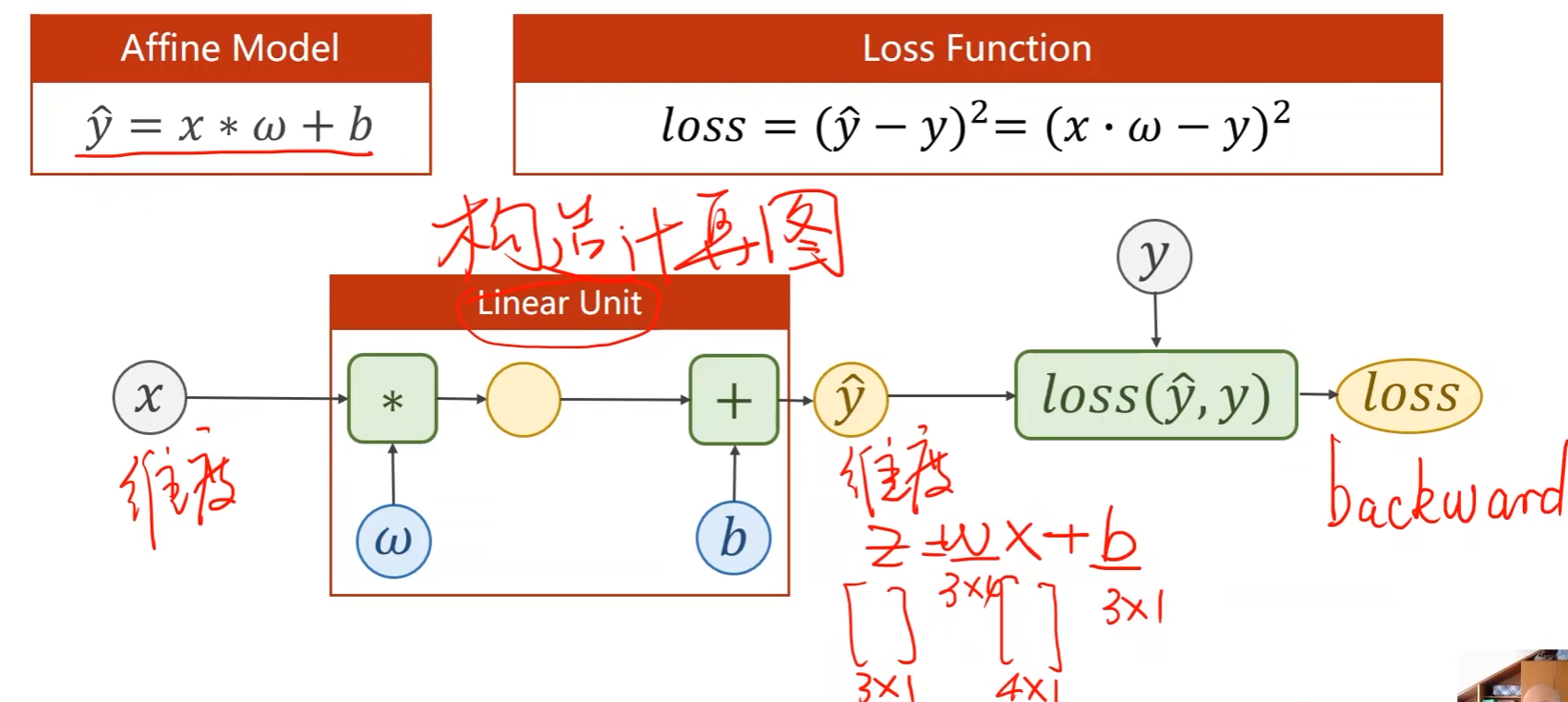
-
将模型定义成一个类
"""
Our model class should be inherit from nn.Module, which is Base class for all neural network modules
模型类都是从nn.Module继承,nn.Module是所有神经网络模型的基类
成员方法至少包含__init__()和forward()
"""
class LinearModel(torch.nn.Module):
def __int__(self):
# 构造函数,用于初始化对象
super(LinearModel, self).__int__() # super是调用父类的构造,第一个参数LinearModel是类名称
self.linear = torch.nn.Linear(1, 1) # 构造对象。nn.Linear包含两个张量成员:权重w和偏置b
def forward(self, x):
# 前馈计算
y_pred = self.linear(x) # y_hat,在一个对象(linear)后面加括号,表明实现了一个可调用的对象
return y_pred
model = LinearModel() # 实例化,model是可调用的,如model(x),x会传入forward中

-
in_features:输入样本的维度(特征)
-
out_features:输出样本的维度

-
*args:表示可变参数,会存放所有未命名的变量参数,在函数调用的时候自动组装为一个元组
-
**kwargs:表示关键字参数,在函数内部自动组装成一个字典
# 例子:假设定义一个func函数,并定义了形参 def func(a, b, c, x, y): pass # 在调用的时候,传入的实参必须要和形参对应 func(1, 2, 3, x=3, y=5) # 问题是如果调用的时候参数更多该怎么办? func(1, 2, 4, 3, x=3, y=5) # 比上面多一个值,这样调用就会出错 --- # 对func进行修改,将a,b,c换成*args,那么在调用func的时候所有没有命名的实参都会传到args中 def func(*args, x, y): pass --- # 对于x和y这种命名的参数可以写成**kwargs,在调用func的时候命名的实参都会传到kwargs中 def func(*args, **kwargs): pass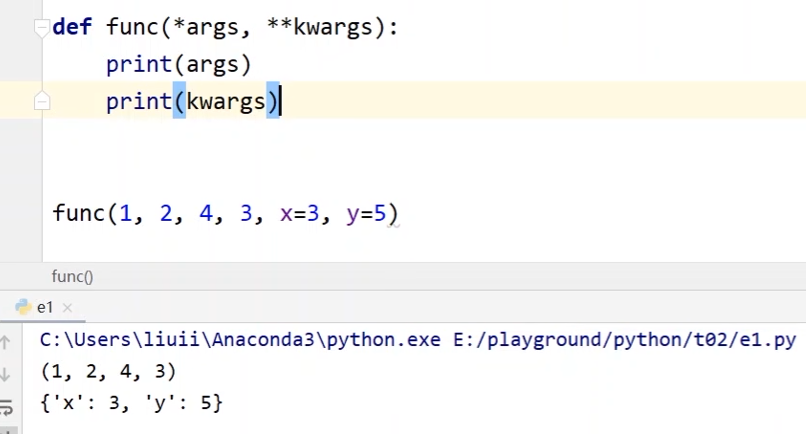
# 定义一个可调用的类
class Foobar:
def __init__(self):
# 先定义__init__,因为没起作用就写个pass
pass
# 要想对象可调用,则需要定义一个__call__函数。pycharm中会自动提示如下形式
# *args:表示可变参数,会存放所有未命名的变量参数,在函数调用的时候自动组装为一个元组
# **kwargs:表示关键字参数,在函数内部自动组装成一个字典
def __call__(self, *args, **kwargs):
print("Hello" + str(args[0])) # 假设就接受args的第一个参数
foobar = Foobar() # 定义一个Foobar类的变量foobar
# 由于类中定义了__call__()函数,所以可以进行如下操作,给foobar传入参数
foobar(1, 2, 3)
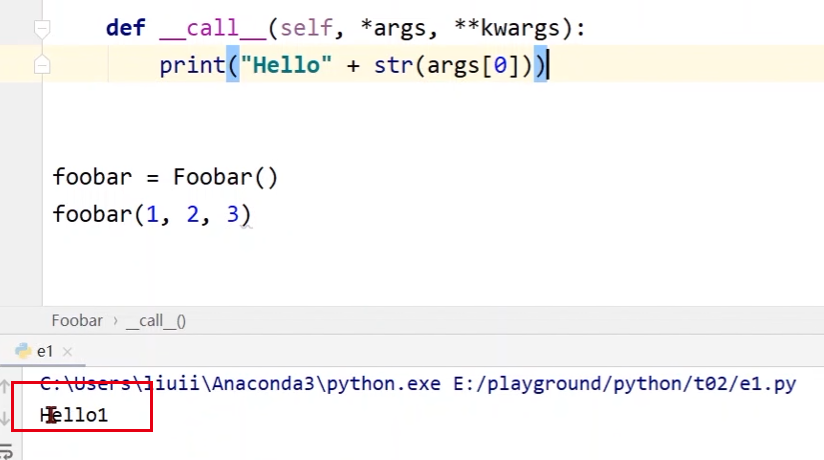
- PyTorch中的Module的call函数里面有一条语句是要调用forward(),因此在我们自己写的module类中必须要实现forward()来覆盖掉父类中的forward()
线性回归第三步:构造loss函数和优化器
criterion = torch.nn.MSELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
-
损失函数使用MSE
- MSELoss继承自nn.Module,参与计算图的构建
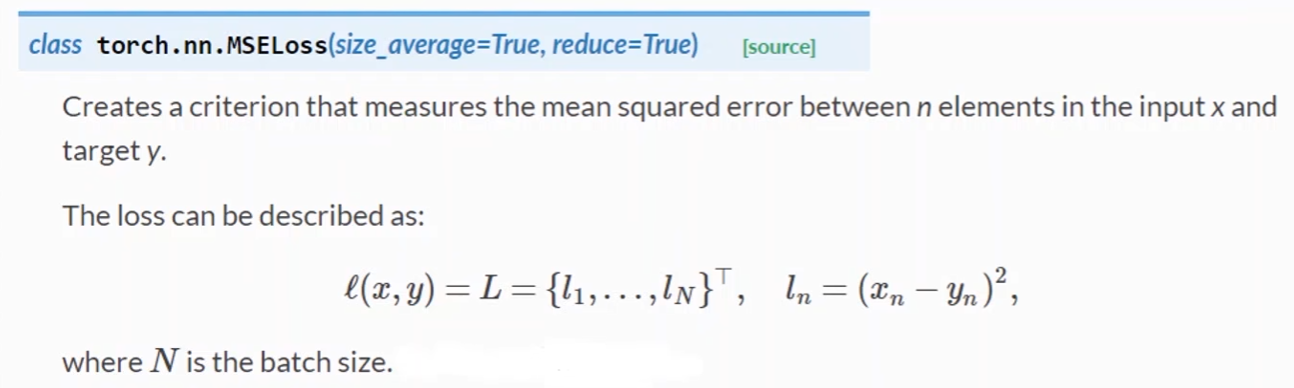
- size_average:是否要求均值(可求可不求)
- reduce:是否要降维(一般只考虑size_average)
-
优化器使用SGD
-
torch.optim.SGD()是一个类,与nn.Module无关,不参与计算图的构建

-
model.parameters()是权重
- model中并没有定义相应的权重,但里面的成员函数linear有权重
- 方法parameters是继承自Module,它会检查model中的所有成员函数,如果成员中有相应的权重,那就将其都加到最终的训练结果上
-
lr:learning rate,一般都设定一个固定的学习率
-
线性回归第四步:训练过程
三个步骤:
- 前馈
- 反馈
- 开始反馈前要先将梯度归零
- 更新
for epoch in range(100):
y_pred = model(x_data) # 前馈:计算y_hat
loss = criterion(y_pred, y_data) # 前馈:计算损失
print(epoch, loss.item())
optimizer.zero_grad() # 反馈:在反向传播开始将上一轮的梯度归零
loss.backward() # 反馈:反向传播(计算梯度)
optimizer.step() # 更新权重w和偏置b
完整的代码(包含模型测试和loss曲线绘制)
import torch
import matplotlib.pyplot as plt
# 数据集
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])
# 用于绘图
epoch_list = []
loss_list =[]
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
y_pred = self.linear(x)
return y_pred
model = LinearModel()
# criterion = torch.nn.MSELoss(size_average=False) pytorch更新后被弃用了
criterion = torch.nn.MSELoss(reduction='sum')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 训练过程
for epoch in range(100):
y_pred = model(x_data) # 前馈:计算y_hat
loss = criterion(y_pred, y_data) # 前馈:计算损失
print(epoch, loss.item())
epoch_list.append(epoch)
loss_list.append(loss.item())
optimizer.zero_grad() # 反馈:在反向传播开始将上一轮的梯度归零
loss.backward() # 反馈:反向传播(计算梯度)
optimizer.step() # 更新权重w和偏置b
# 输出权重和偏置
print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())
# 测试模型
x_test = torch.tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)
# 绘制loss曲线
plt.plot(epoch_list, loss_list)
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()
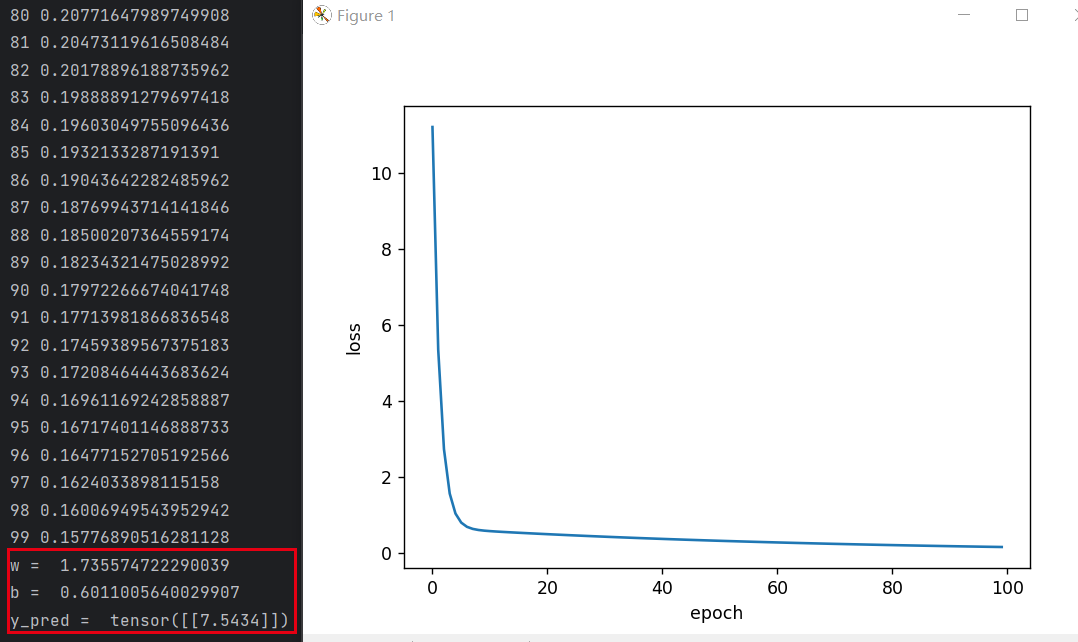
- 训练100轮:
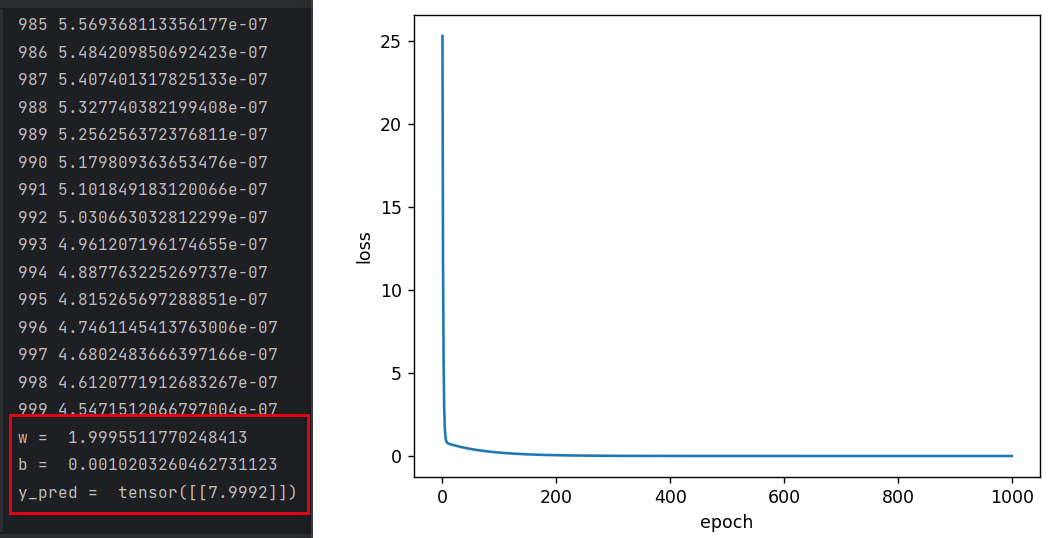
- 训练1000轮:














 844
844











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









