






这里介绍OpenVINO工具套件中与模型推理相关的3个功能。
当你使用AI模型进行推理时,往往需要设置一些参数与选项,相应地,OpenVINO 工具套件为此提供了一些自动设定参数选项的功能。本文主要介绍OpenVINO工具套件中与模型推理相关的3个功能,它们它们分别是:用于input数据足够多时,提供最大throughput的Auto-batching功能;用于自动选择设备进行推理的Auto Plugin功能;以及用于满足特定模型动态输入的Dynamic Shape功能。本文将逐一介绍这三个实用的功能,并在文末给出这三功能的优缺点总结对比。
功能介绍
Auto-batching
Auto-batching设计目的是让开发者利用最少的代码去实现使用Intel®显卡做模型推理的数据吞吐量最大化。在没有设定input以及没有限制范围的情况下,它会按照集成显卡或者是独立显卡能承受的最大吞吐量去设定推理线程数。如果应用程序有大量的输入数据且以高频率连续提交推理请求,推荐使用Auto-batching功能。
该功能通过几行代码实现了最多推理线程的响应,同时也不会对原先的示例代码造成影响。如果在推理设备设置中,将"device"参数设置为:"BATCH:GPU" 该功能将会被激活。例如,在benchmark_app应用使用Auto-batching的方式如下:
另外一种方法是:在GPU推理时,选择性能模式为"THROUGHPUT",该功能将会被自动触发。所以在示例代码中添加如下两行,即可在GPU进行推理时,启动Auto-batching功能:
无论是通过设置BATCH:GPU,还是选择"THROUGHPUT"的推理模式,推理的batch size值都会自动进行选取。选取的方式是查询当前设备的 ov::optimal_batch_size (https://docs.openvino.ai/latest/groupov_runtime_cpp_prop_api.html#doxid-group-ov-runtime-cpp-prop-api-1ga129bad2da2fc2a40a7d746d86fc9c68d)属性并且通过模型拓扑结构的输入端获取batch size的值作为模型推理的batch size值。
接下来,是使用Benchmark APP做的对比实验:
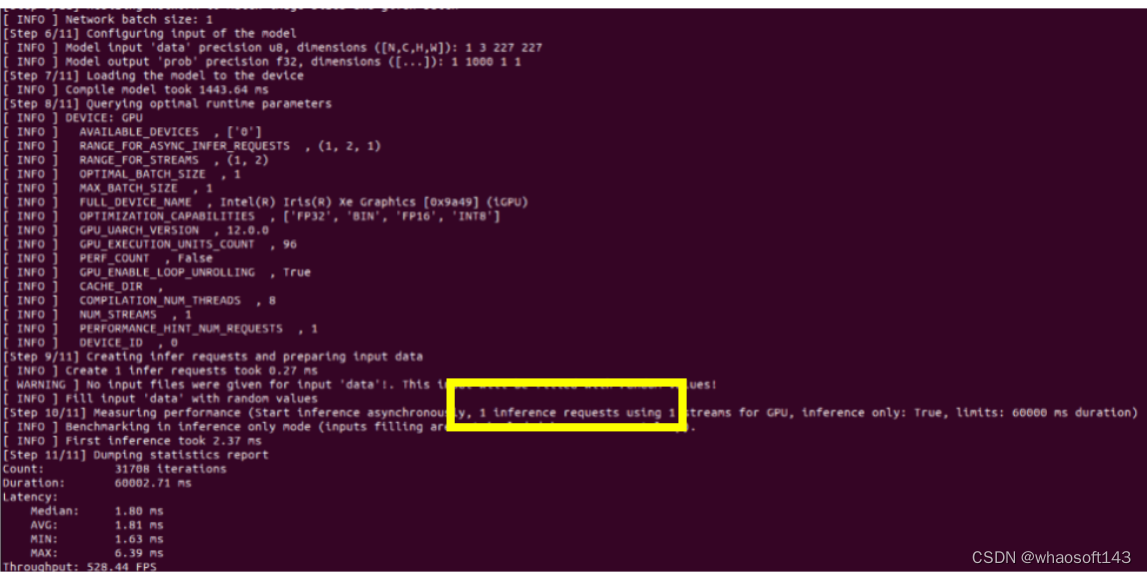
图1:Disable Auto-batching
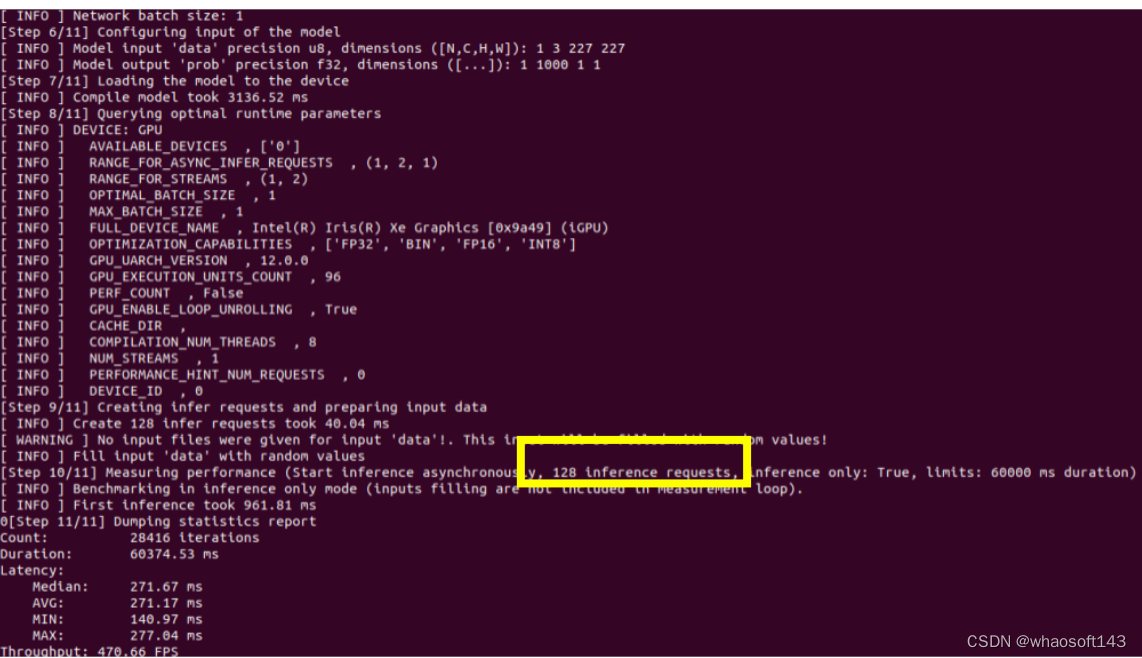
图2:Enable Auto-batching
通过对比Auto-batching功能开闭的推理结果图,可以看到当此功能开启的时候:即使推理设备选择的是集成显卡,推理线程数仍旧被推上了128个,说明此功能确实会尝试使用当前状态下压力最大的推理线程数,来达到推理最大的吞吐量。但是结果是当推理性能有限的集成显卡启动了128个线程的时候,整体的throughput的数值比单推理线程的throughput要低一些,所以当硬件推理性能有限时,需要对推理线程数进行限定。同样,在Auto-batching中限定推理线程有两种方式分别为,设置BATCH: GPU (4)或设置ov :: hint :: num_requests参数可以将推理线程设为4:
Auto-batching中内置了Auto_batch_timeout参数,该参数用于监测输入数据送达的时延,初始值为1000,表示若1000毫秒后无数据输入则提示推理超时。注意,如果推理频率较低,或者根据Auto_batch_timeout参数发现推理超时,可以手动关闭Auto-batching:
AUTO Plugin
在OpenVINO工具套件的推理插件(Plugin)选择上,除了常规的CPU,iGPU,Myriad,您还可以选择使用AUTO Plugin。开发者通过它快速部署AI示例用于实验,且不用考虑推理设备的选择就能获得一个不错的推理性能。不需要指定设备,它会自动配置推理硬件,当有多个设备时,它也会自动联合调用多个硬件进行推理。
AUTO Plugin的工作流程是:首先,检测当前环境下所有的可用设备,之后根据预制的硬件选择规则,选择相应的推理设备,并且优化推理的整体配置,最后执行AI推理。AUTO Plugin 对于推理设备选择遵循以下的规则:
dGPU (e.g. Intel® Iris® Xe MAX) ->
iGPU (e.g. Intel® UHD Graphics 620 (iGPU)) ->
Intel® Movidius™ Myriad™ X VPU(e.g. Intel® Neural Compute Stick 2 (Intel® NCS2)) ->
Intel® CPU (e.g. Intel® Core™ i7-1165G7)
AUTO Plugin 内置有三个模式可供选择:
- THROUGHPUT
默认模式。该模式优先考虑高吞吐量,在延迟和功率之间进行平衡,最适合于涉及多个任务的推理,例如推理视频源或大量图像。注:此模式只会对CPU与GPU进行调用。若该模式下调用GPU进行推理,将会自动触发"Auto-batching"功能。
- LATENCY
此选项优先考虑低延迟,为每个推理任务提供比较短的响应时间。它对于需要对单个输入图像进行推断的任务(例如超声扫描图像的医学分析)。此外,它还适用于实时或接近实时应用的任务,例如工业机器人对其环境中动作的响应或自动驾驶车辆的避障。注:此模式只会对CPU与GPU进行调用。
compiled_model = core**.compile_model(model=model, device_name="AUTO", config=**{"PERFORMANCE_HINT":"LATENCY"})
- CUMULATIVE_THROUGHPUT
CUMULTIVE_THROUGHPUT模式允许同时在多个设备上运行推理以获得更高的吞吐量。使用CUMULTIVE_THROUGHPUT模式时,AUTO Plugin将网络模型加载到候选列表中的所有可用设备,然后根据默认的优先级载入设备运行推理。
注意:如果指定了没有任何设备名称的AUTO,并且系统有两个以上的GPU设备,则AUTO将从设备候选列表中删除CPU,以保持GPU以满容量运行。如果指定了设备优先级,AUTO将根据优先级在设备上运行推理请求。
Dynamic Shape
模型的动态输入对于某些领域十分重要,比如说在自然语言处理(NLP)中就需要实时对语句进行分割,所以模型的输入是实时变化的,又比如在图像识别中,分割块的形状大小也会根据目标的大小实时变动。对于分割之后的图像来说,进行resize操作往往会破坏它的特征属性,导致在后期推理中造成推理准确性降低。动态形状输入功能的引入使得一些基于图像识别的模型,运行结果的准确度提高。使用Dynamic Shape功能能够更好地保留图像的特征,根据输入图像的大小,动态调节模型输入,最终模型推理的准确率获得了提升。
在2022.1以前的OpenVINO版本中,使用WPOD-NET (GitHub - sergiomsilva/alpr-unconstrained: License Plate Detection and Recognition in Unconstrained Scenarios)模型进行车牌识别,如果出现动态形态输入的话,在MO转换时就会报错,必须强制转成静态输入,例如:
这会导致该模型在特定的例子下识别精度降低:
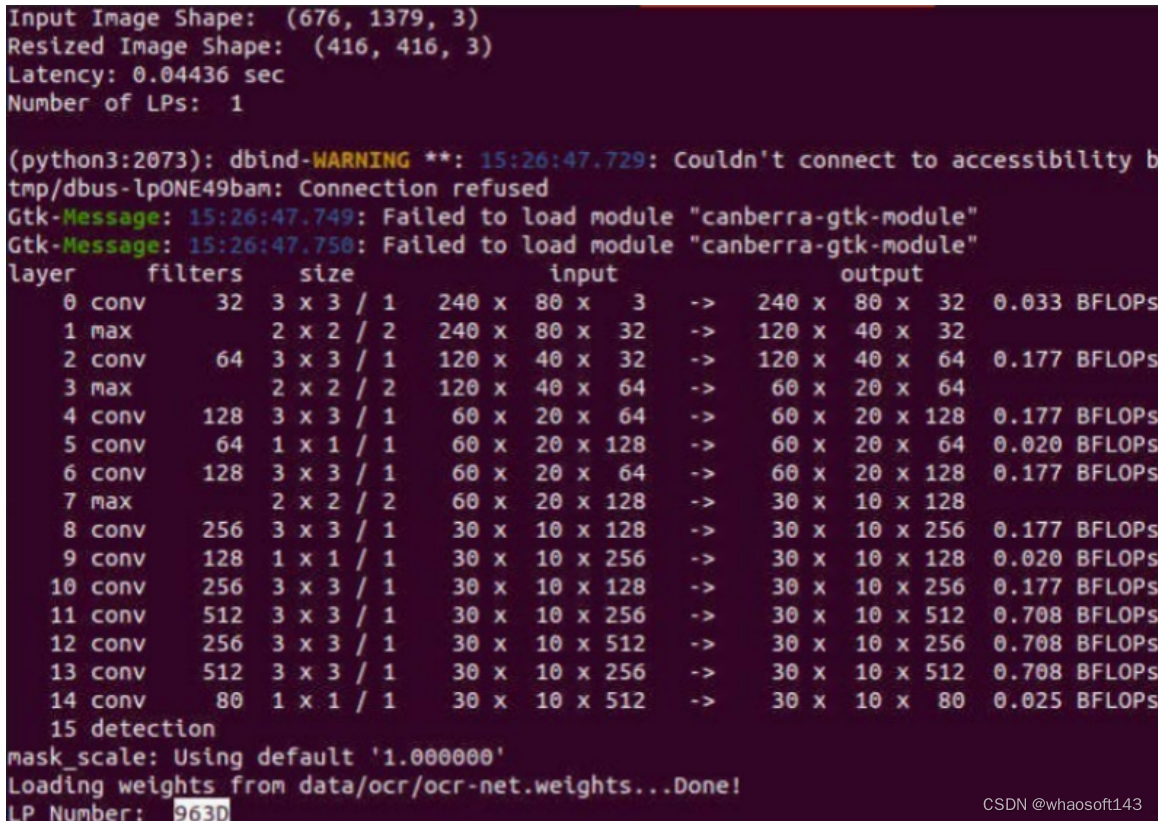

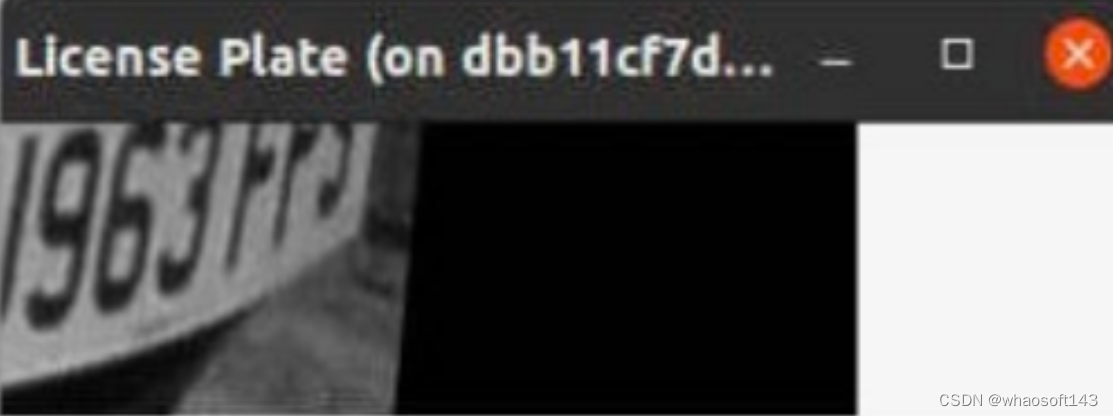
图例:输入图像Resize 为固定尺寸后进行模型推理
由于模型被强制转成了静态输入,可以很明显的发现输入的图像被被强制Resize到了(416,416),图像分割的错误,最后导致了最后车牌识别的结果是不正确的。
在2022.1以后的OpenVINO版本中,MO支持了Dynamic Shape的功能,故使用新版本OpenVINO工具套件中的模型优化器进行模型转换:
在生成的xml文件中,可以开到input shape被识别为动态输入,动态参数以"?"或"-1"进行显示:
使用包含动态输入的模型进行试验,实验结果如下:
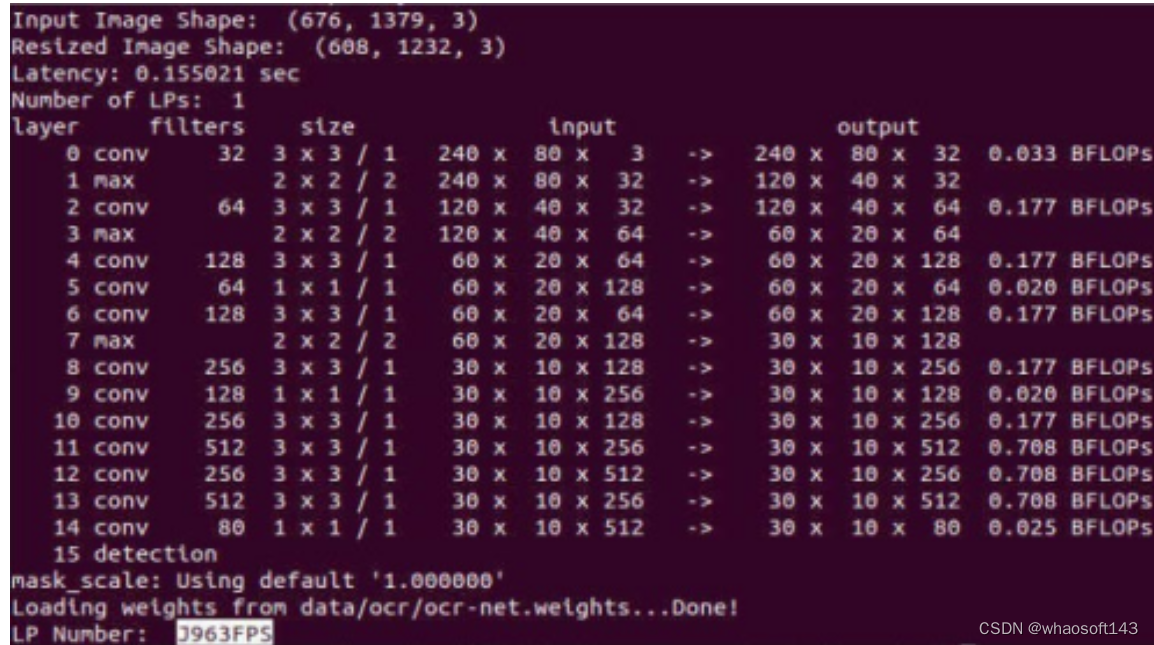


图例:模型使用动态输入进行推理
通过WPOD-NET的内置算法,计算得到合适的Resize长和宽(1232x608),将图片Resize至1232x608,分割到的车牌是清晰完整且最终车牌号码识别是正确的。
模型的动态输入在这个例子中显得十分重要,因为动态输入的支持使得模型推理识别的精度更加准确了。如果模型优化器没有识别到模型的动态输入参数,您可以在代码中手动指定Dynamic Shape:
您也可以指定动态输入的动态范围:
由于您的输入图像是动态的,所以说您在初始化input tensor的时候,根据需要进行设定,您可以手动对每一个推理tensor进行指定:
当然,也可以通过模型的input layer进行指定:
总结:
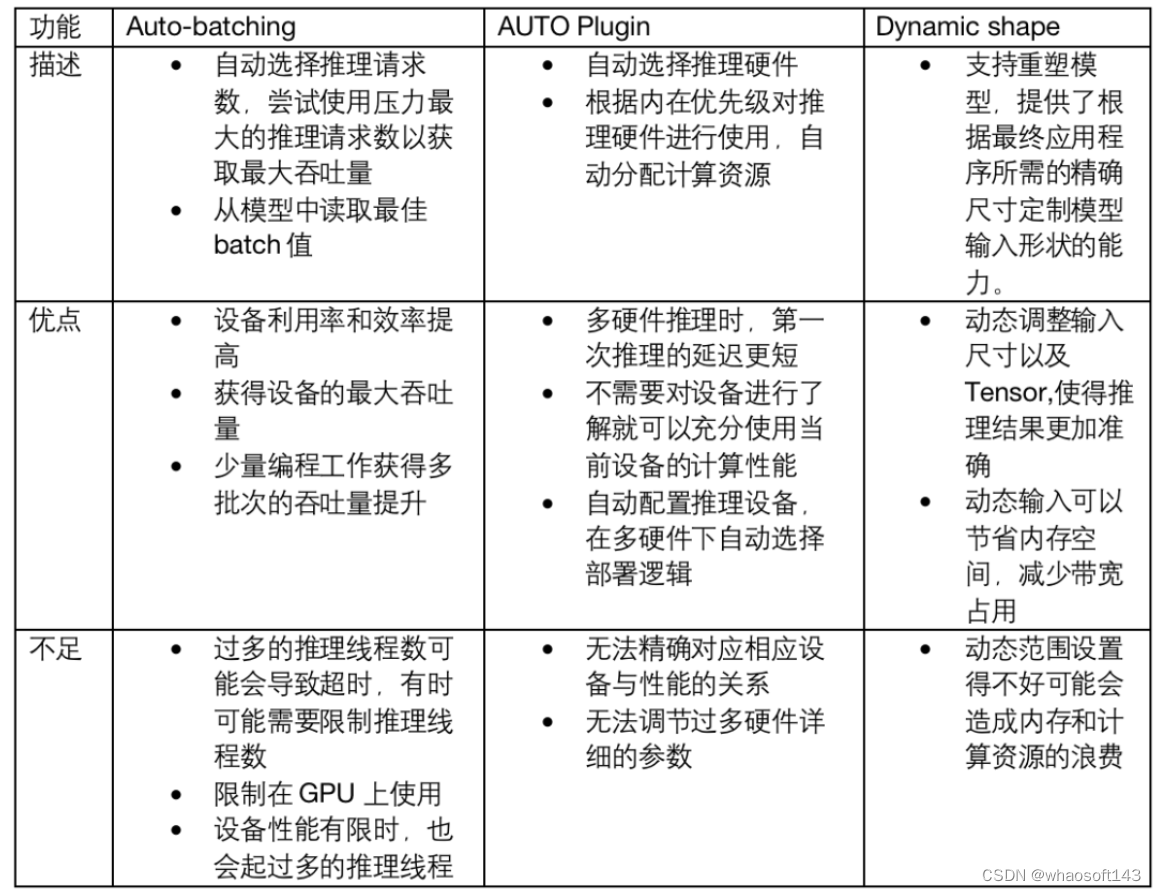
针对不同模型推理场景下, Auto-batching能够自动给予设备最大压力达到最大吞吐量;AUTO Plugin能够自动选择推理设备;Dynamic shape能供根据输入图像动态调整模型的input shape大小。这些功能都依据开发者的需求,在进行模型推理时,帮助住开发者自动完成相应的配置,对开发OpenVINO的示例应用进行辅助。
不过这些功能在使用时,也有一些注意事项需要知晓,请您在使用这些功能之前,了解每个功能的局限性以及每个功能正确的用法.
OpenVINO工具套件下载地址: https://www.intel.cn/content/www/cn/zh/developer/tools/openvino-toolkit/download.html
OpenVINO 使用文档: https://docs.openvino.ai/latest/















 1160
1160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









