







📌Chapter02图片处理与数据加载
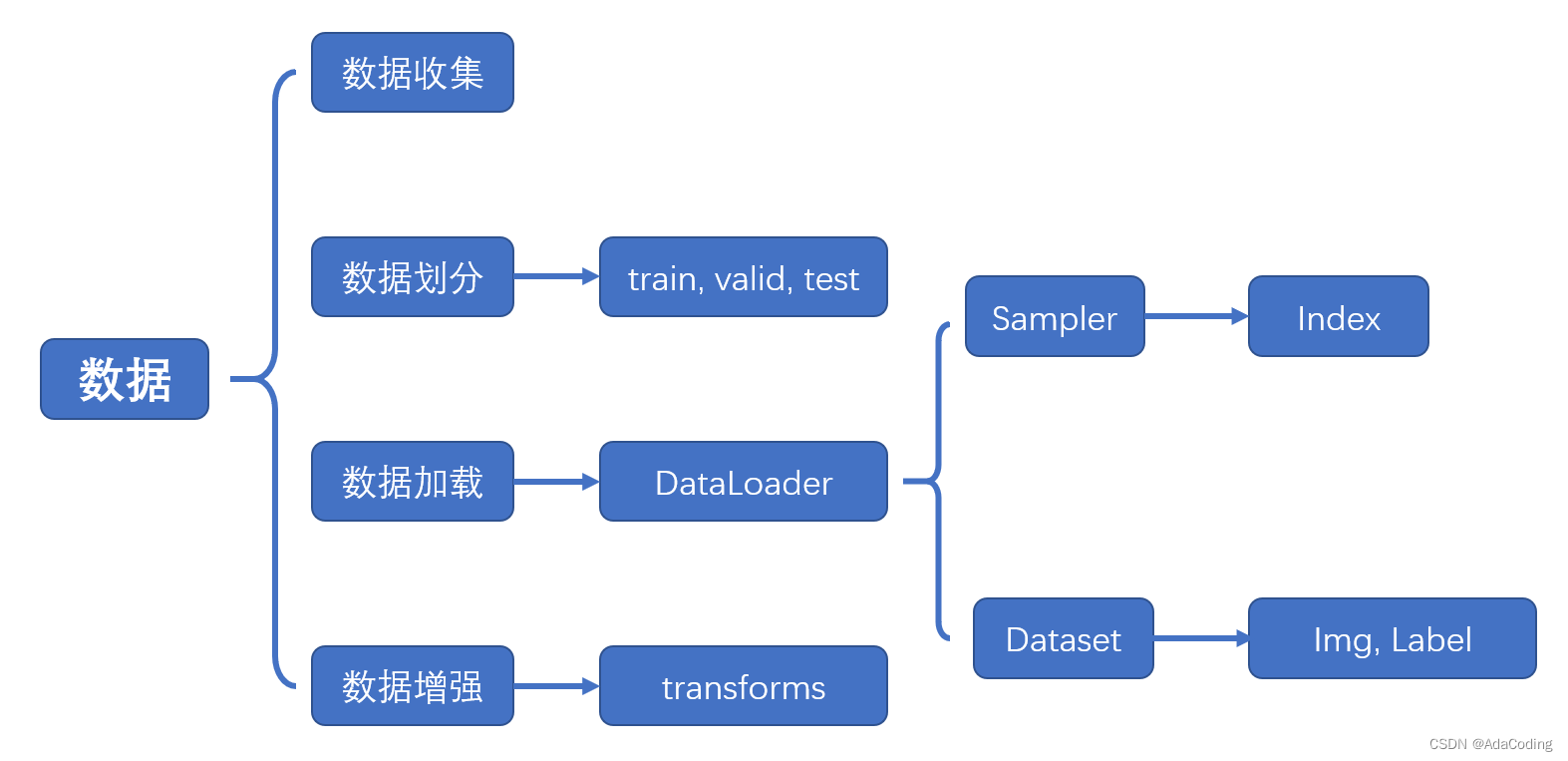
2.1 DataLoader 与 DataSet
本章代码:https://github.com/zhangxiann/PyTorch_Practice/blob/master/lesson2/rmb_classification/
人民币 二分类
实现 1 元人民币和 100 元人民币的图片二分类。
前面讲过 PyTorch 的五大模块:数据、模型、损失函数、优化器和迭代训练。
数据模块又可以细分为 4 个部分:
- 数据收集:样本和标签。
- 数据划分:训练集、验证集和测试集
- 数据读取:对应于PyTorch 的 DataLoader。其中 DataLoader 包括 Sampler 和 DataSet。Sampler 的功能是生成索引, DataSet 是根据生成的索引读取样本以及标签。
- 数据预处理:对应于 PyTorch 的 transforms
torch.utils.data.DataLoader()
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None)
功能:构建可迭代的数据装载器
- dataset: Dataset 类,决定数据从哪里读取以及如何读取
- batchsize: 批大小
- num_works:num_works: 是否多进程读取数据
- sheuffle: 每个 epoch 是否乱序
- drop_last: 当样本数不能被 batchsize 整除时,是否舍弃最后一批数据
Epoch, Iteration, Batchsize
- Epoch: 所有训练样本都已经输入到模型中,称为一个 Epoch
- Iteration: 一批样本输入到模型中,称为一个 Iteration
- Batchsize: 批大小,决定一个 iteration 有多少样本,也决定了一个 Epoch 有多少个 Iteration
假设样本总数有 80,设置 Batchsize 为 8,则共有 80 ÷ 8 = 10 80 \div 8=10 80÷8=10 个 Iteration。这里 1 E p o c h = 10 I t e r a t i o n 1 Epoch = 10 Iteration 1Epoch=10Iteration。
假设样本总数有 86,设置 Batchsize 为 8。如果drop_last=True则共有 10 个 Iteration;如果drop_last=False则共有 11 个 Iteration。
torch.utils.data.Dataset
功能:Dataset 是抽象类,所有自定义的 Dataset 都需要继承该类,并且重写__getitem()方法和__len()方法 。__getitem()__方法的作用是接收一个索引,返回索引对应的样本和标签,这是我们自己需要实现的逻辑。len()方法是返回所有样本的数量。
数据读取包含 3 个方面
- 读取哪些数据:每个 Iteration 读取一个 Batchsize 大小的数据,每个 Iteration 应该读取哪些数据。
- 从哪里读取数据:如何找到硬盘中的数据,应该在哪里设置文件路径参数
- 如何读取数据:不同的文件需要使用不同的读取方法和库。
这里的路径结构如下,有两类人民币图片:1 元和 100 元,每一类各有 100 张图片。
RMB_data
- 1
- 100
首先划分数据集为训练集、验证集和测试集,比例为 8:1:1。
数据划分好后的路径构造如下:
rmb_split
- train
- 1
- 100
- valid
- 1
- 100
- test
- 1
- 100
实现读取数据的 Dataset,编写一个get_img_info()方法,读取每一个图片的路径和对应的标签,组成一个元组,再把所有的元组作为 list 存放到self.data_info变量中,这里需要注意的是标签需要映射到 0 开始的整数: rmb_label = {“1”: 0, “100”: 1}。
@staticmethod
def get_img_info(data_dir):
data_info = list()
# data_dir 是训练集、验证集或者测试集的路径
for root, dirs, _ in os.walk(data_dir):
# 遍历类别
# dirs ['1', '100']
for sub_dir in dirs:
# 文件列表
img_names = os.listdir(os.path.join(root, sub_dir))
# 取出 jpg 结尾的文件
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names))
# 遍历图片
for i in range(len(img_names)):
img_name = img_names[i]
# 图片的绝对路径
path_img = os.path.join(root, sub_dir, img_name)
# 标签,这里需要映射为 0、1 两个类别
label = rmb_label[sub_dir]
# 保存在 data_info 变量中
data_info.append((path_img, int(label)))
return data_info
然后在Dataset 的初始化函数中调用get_img_info()方法。
def __init__(self, data_dir, transform=None):
"""
rmb面额分类任务的Dataset
:param data_dir: str, 数据集所在路径
:param transform: torch.transform,数据预处理
"""
# data_info存储所有图片路径和标签,在DataLoader中通过index读取样本
self.data_info = self.get_img_info(data_dir)
self.transform = transform
然后在__getitem__()方法中根据index 读取self.data_info中路径对应的数据,并在这里做 transform 操作,返回的是样本和标签。
def __getitem__(self, index):
# 通过 index 读取样本
path_img, label = self.data_info[index]
# 注意这里需要 convert('RGB')
img = Image.open(path_img).convert('RGB') # 0~255
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
# 返回是样本和标签
return img, label
在__len__()方法中返回self.data_info的长度,即为所有样本的数量。
# 返回所有样本的数量
def __len__(self):
return len(self.data_info)
在train_lenet.py中,分 5 步构建模型。
第 1 步设置数据。首先定义训练集、验证集、测试集的路径,定义训练集和测试集的transforms。然后构建训练集和验证集的RMBDataset对象,把对应的路径和transforms传进去。再构建DataLoder,设置 batch_size,其中训练集设置shuffle=True,表示每个 Epoch 都打乱样本。
# 构建MyDataset实例train_data = RMBDataset(data_dir=train_dir, transform=train_transform)valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)
# 构建DataLoder
# 其中训练集设置 shuffle=True,表示每个 Epoch 都打乱样本
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
第 2 步构建模型,这里采用经典的 Lenet 图片分类网络。
net = LeNet(classes=2)
net.initialize_weights()
第 3 步设置损失函数,这里使用交叉熵损失函数。
criterion = nn.CrossEntropyLoss()
第 4 步设置优化器。这里采用 SGD 优化器。
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1) # 设置学习率下降策略
第 5 步迭代训练模型,在每一个 epoch 里面,需要遍历 train_loader 取出数据,每次取得数据是一个 batchsize 大小。这里又分为 4 步。第 1 步进行前向传播,第 2 步进行反向传播求导,第 3 步使用optimizer更新权重,第 4 步统计训练情况。每一个 epoch 完成时都需要使用scheduler更新学习率,和计算验证集的准确率、loss。
for epoch in range(MAX_EPOCH):
loss_mean = 0.
correct = 0.
total = 0.
net.train()
# 遍历 train_loader 取数据
for i, data in enumerate(train_loader):
# forward
inputs, labels = data
outputs = net(inputs)
# backward
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
# update weights
optimizer.step()
# 统计分类情况
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).squeeze().sum().numpy()
# 打印训练信息
loss_mean += loss.item()
train_curve.append(loss.item())
if (i+1) % log_interval == 0:
loss_mean = loss_mean / log_interval
print("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, i+1, len(train_loader), loss_mean, correct / total))
loss_mean = 0.
scheduler.step() # 更新学习率
# 每个 epoch 计算验证集得准确率和loss
...
...
我们可以看到每个 iteration,我们是从train_loader中取出数据的。
def __iter__(self):
if self.num_workers == 0:
return _SingleProcessDataLoaderIter(self)
else:
return _MultiProcessingDataLoaderIter(self)
这里我们没有设置多进程,会执行_SingleProcessDataLoaderIter的方法。我们以_SingleProcessDataLoaderIter为例。在_SingleProcessDataLoaderIter里只有一个方法_next_data(),如下:
def _next_data(self):
index = self._next_index() # may raise StopIteration
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
if self._pin_memory:
data = _utils.pin_memory.pin_memory(data)
return data
在该方法中,self._next_index()是获取一个 batchsize 大小的 index 列表,代码如下:
def _next_index(self):
return next(self._sampler_iter) # may raise StopIteration
其中调用的sampler类的__iter__()方法返回 batch_size 大小的随机 index 列表。
def __iter__(self):
batch = []
for idx in self.sampler:
batch.append(idx)
if len(batch) == self.batch_size:
yield batch
batch = []
if len(batch) > 0 and not self.drop_last:
yield batch
然后再返回看 dataloader的_next_data()方法:
def _next_data(self):
index = self._next_index() # may raise StopIteration
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
if self._pin_memory:
data = _utils.pin_memory.pin_memory(data)
return data
在第二行中调用了self._dataset_fetcher.fetch(index)获取数据。这里会调用_MapDatasetFetcher中的fetch()函数:
def fetch(self, possibly_batched_index):
if self.auto_collation:
data = [self.dataset[idx] for idx in possibly_batched_index]
else:
data = self.dataset[possibly_batched_index]
return self.collate_fn(data)
这里调用了self.dataset[idx],这个函数会调用dataset.getitem()方法获取具体的数据,所以__getitem__()方法是我们必须实现的。我们拿到的data是一个 list,每个元素是一个 tunple,每个 tunple 包括样本和标签。所以最后要使用self.collate_fn(data)把 data 转换为两个 list,第一个 元素 是样本的batch 形式,形状为 [16, 3, 32, 32] (16 是 batch size,[3, 32, 32] 是图片像素);第二个元素是标签的 batch 形式,形状为 [16]。
所以在代码中,我们使用inputs, labels = data来接收数据。
PyTorch 数据读取流程图
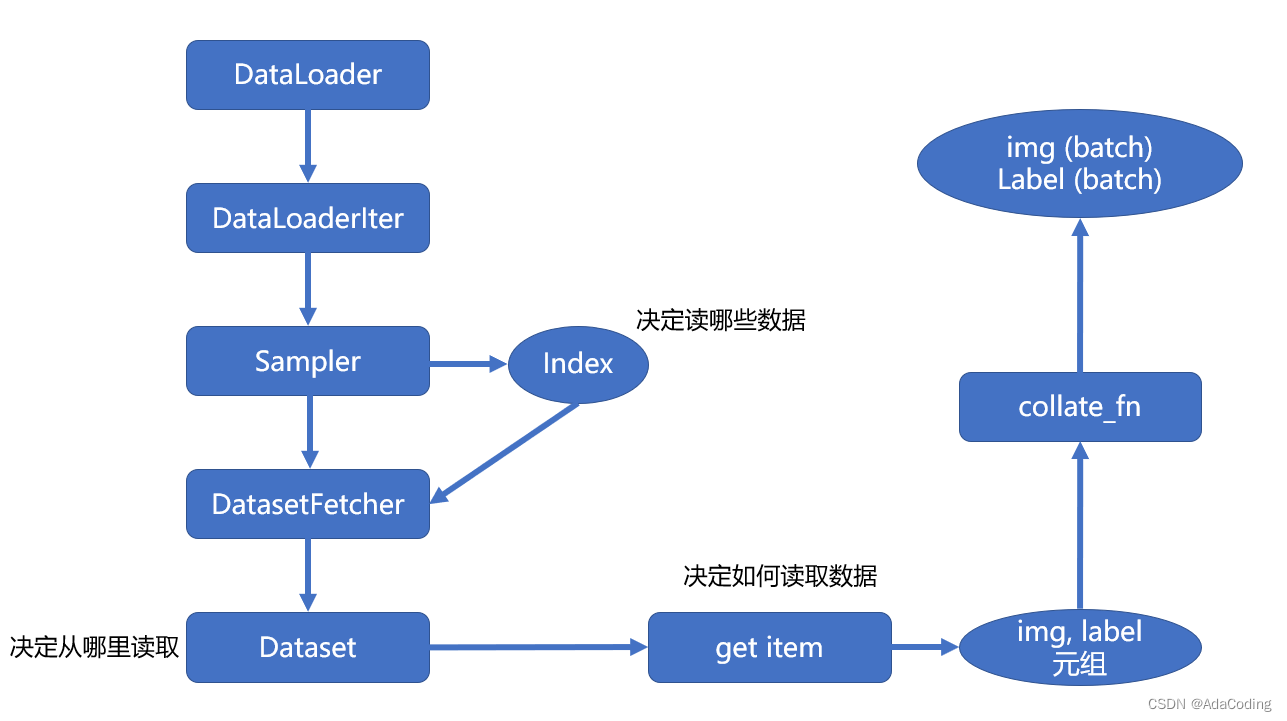
首先在 for 循环中遍历DataLoader,然后根据是否采用多进程,决定使用单进程或者多进程的DataLoaderIter。在DataLoaderIter里调用Sampler生成Index的 list,再调用DatasetFetcher根据index获取数据。在DatasetFetcher里会调用Dataset的__getitem__()方法获取真正的数据。这里获取的数据是一个 list,其中每个元素是 (img, label) 的元组,再使用 collate_fn()函数整理成一个 list,里面包含两个元素,分别是 img 和 label 的tenser。
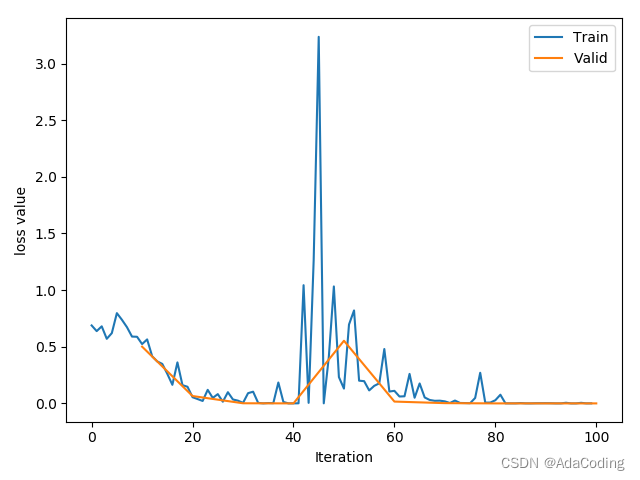
下图是我们的训练过程的 loss 曲线:
2.2 图片预处理 transforms 模块机制
PyTorch 的数据增强
我们在安装PyTorch时,还安装了torchvision,这是一个计算机视觉工具包。有 3 个主要的模块:
- torchvision.transforms: 里面包括常用的图像预处理方法
- torchvision.datasets: 里面包括常用数据集如 mnist、CIFAR-10、Image-Net 等
- torchvision.models: 里面包括常用的预训练好的模型,如 AlexNet、VGG、ResNet、GoogleNet 等
深度学习模型是由数据驱动的,数据的数量和分布对模型训练的结果起到决定性作用。所以我们需要对数据进行预处理和数据增强。下面是用数据增强,从一张图片经过各种变换生成 64 张图片,增加了数据的多样性,这可以提高模型的泛化能力。

常用的图像预处理方法有:
- 数据中心化
- 数据标准化
- 缩放
- 裁剪
- 旋转
- 翻转
- 填充
- 噪声添加
- 灰度变换
- 线性变换
- 仿射变换
- 亮度、饱和度以及对比度变换。
在人民币图片二分类实验中,我们对数据进行了一定的增强。
# 设置训练集的数据增强和转化
train_transform = transforms.Compose([
transforms.Resize((32, 32)),# 缩放
transforms.RandomCrop(32, padding=4), #裁剪
transforms.ToTensor(), # 转为张量,同时归一化
transforms.Normalize(norm_mean, norm_std),# 标准化
])
# 设置验证集的数据增强和转化,不需要 RandomCrop
valid_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
当我们需要多个transforms操作时,需要作为一个list放在transforms.Compose中。需要注意的是transforms.ToTensor()是把图片转换为张量,同时进行归一化操作,把每个通道 0255 的值归一化为 01。在验证集的数据增强中,不再需要transforms.RandomCrop()操作。然后把这两个transform操作作为参数传给Dataset,在Dataset的__getitem__()方法中做图像增强。
def __getitem__(self, index):
# 通过 index 读取样本
path_img, label = self.data_info[index]
# 注意这里需要 convert('RGB')
img = Image.open(path_img).convert('RGB') # 0~255
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
# 返回是样本和标签
return img, label
其中self.transform(img)会调用Compose的__call__()函数:
def __call__(self, img):
for t in self.transforms:
img = t(img)
return img
可以看到,这里是遍历transforms中的函数,按顺序应用到 img 中。
transforms.Normalize
torchvision.transforms.Normalize(mean, std, inplace=False)
功能:逐 channel 地对图像进行标准化
output = ( input - mean ) / std
mean: 各通道的均值
std: 各通道的标准差
inplace: 是否原地操作
该方法调用的是F.normalize(tensor, self.mean, self.std, self.inplace)
而```F.normalize()``方法如下:
def normalize(tensor, mean, std, inplace=False):
if not _is_tensor_image(tensor):
raise TypeError('tensor is not a torch image.')
if not inplace:
tensor = tensor.clone()
dtype = tensor.dtype
mean = torch.as_tensor(mean, dtype=dtype, device=tensor.device)
std = torch.as_tensor(std, dtype=dtype, device=tensor.device)
tensor.sub_(mean[:, None, None]).div_(std[:, None, None])
return tensor
首先判断是否为 tensor,如果不是 tensor 则抛出异常。然后根据inplace是否为 true 进行 clone,接着把mean 和 std 都转换为tensor (原本是 list),最后减去均值除以方差:tensor.sub_(mean[:, None, None]).div_(std[:, None, None])
对数据进行均值为 0,标准差为 1 的标准化,可以加快模型的收敛。
在逻辑回归的实验中,我们的数据生成代码如下:
sample_nums = 100
mean_value = 1.7
bias = 1
n_data = torch.ones(sample_nums, 2)
# 使用正态分布随机生成样本,均值为张量,方差为标量
x0 = torch.normal(mean_value * n_data, 1) + bias # 类别0 数据 shape=(100, 2)
# 生成对应标签
y0 = torch.zeros(sample_nums) # 类别0 标签 shape=(100, 1)
# 使用正态分布随机生成样本,均值为张量,方差为标量
x1 = torch.normal(-mean_value * n_data, 1) + bias # 类别1 数据 shape=(100, 2)
# 生成对应标签
y1 = torch.ones(sample_nums) # 类别1 标签 shape=(100, 1)
train_x = torch.cat((x0, x1), 0)
train_y = torch.cat((y0, y1), 0)
生成的数据均值是mean_value+bias=1.7+1=2.7,比较靠近 0 均值。模型在 380 次迭代时,准确率就超过了 99.5%。
如果我们把 bias 修改为 5。那么数据的均值变成了 6.7,偏离 0 均值较远,这时模型训练需要更多次才能收敛 (准确率达到 99.5%)。
2.3 二十二种 transforms 图片数据预处理方法
本章代码:https://github.com/zhangxiann/PyTorch_Practice/blob/master/lesson2/transforms/
由于图片经过 transform 操作之后是 tensor,像素值在 0~1 之间,并且标准差和方差不是正常图片的。所以定义了transform_invert()方法。功能是对 tensor 进行反标准化操作,并且把 tensor 转换为 image,方便可视化。
我们主要修改的是transforms.Compose代码块中的内容,其中transforms.Resize((224, 224))是把图片缩放到 (224, 224) 大小 (下面的所有操作都是基于缩放之后的图片进行的),然后再进行其他 transform 操作。
原图如下:

经过缩放之后,图片如下:

裁剪
transforms.CenterCrop
torchvision.transforms.CenterCrop(size)
功能:从图像中心裁剪图片
size: 所需裁剪的图片尺寸
transforms.CenterCrop(196)的效果如下:

如果裁剪的 size 比原图大,那么会填充值为 0 的像素。transforms.CenterCrop(512)的效果如下:

transforms.RandomCrop
torchvision.transforms.RandomCrop(size, padding=None, pad_if_needed=False, fill=0, padding_mode='constant')
功能:从图片中随机裁剪出尺寸为 size 的图片,如果有 padding,那么先进行 padding,再随机裁剪 size 大小的图片。
size:
padding: 设置填充大小
当为 a 时,上下左右均填充 a 个像素
当为 (a, b) 时,左右填充 a 个像素,上下填充 b 个像素
当为 (a, b, c, d) 时,左上右下分别填充 a,b,c,d
pad_if_need: 当图片小于设置的 size,是否填充
padding_mode:
constant: 像素值由 fill 设定
edge: 像素值由图像边缘像素设定
reflect: 镜像填充,最后一个像素不镜像。([1,2,3,4] -> [3,2,1,2,3,4,3,2])
symmetric: 镜像填充,最后一个像素也镜像。([1,2,3,4] -> [2,1,1,2,3,4,4,4,3])
fill: 当 padding_mode 为 constant 时,设置填充的像素值
transforms.RandomCrop(224, padding=16)的效果如下,这里的 padding 为 16,所以会先在 4 边进行 16 的padding,默认填充 0,然后随机裁剪出 (224,224) 大小的图片,这里裁剪了左上角的区域。

transforms.RandomCrop(224, padding=(16, 64))的效果如下,首先在左右进行 16 的 padding,上下进行 64 的 padding,然后随机裁剪出 (224,224) 大小的图片。

transforms.RandomCrop(224, padding=16, fill=(255, 0, 0))的效果如下,首先在上下左右进行 16 的 padding,填充值为 (255, 0, 0),然后随机裁剪出 (224,224) 大小的图片。

transforms.RandomCrop(512, pad_if_needed=True)的效果如下,设置pad_if_needed=True,图片小于设置的 size,用 (0,0,0) 填充。

transforms.RandomCrop(224, padding=64, padding_mode=‘edge’)的效果如下,首先在上下左右进行 64 的 padding,使用边缘像素填充,然后随机裁剪出 (224,224) 大小的图片。

transforms.RandomCrop(224, padding=64, padding_mode=‘reflect’)的效果如下,首先在上下左右进行 64 的 padding,使用镜像填充,然后随机裁剪出 (224,224) 大小的图片。

transforms.RandomCrop(1024, padding=1024, padding_mode=‘symmetric’)的效果如下,首先在上下左右进行 1024 的 padding,使用镜像填充,然后随机裁剪出 (1024, 1024) 大小的图片。

transforms.RandomResizedCrop
torchvision.transforms.RandomResizedCrop(size, scale=(0.08, 1.0), ratio=(0.75, 1.3333333333333333), interpolation=2)
功能:随机大小、随机宽高比裁剪图片。首先根据 scale 的比例裁剪原图,然后根据 ratio 的长宽比再裁剪,最后使用插值法把图片变换为 size 大小。
- size: 裁剪的图片尺寸
- scale: 随机缩放面积比例,默认随机选取 (0.08, 1) 之间的一个数
- ratio: 随机长宽比,默认随机选取 ( 3 4 \displaystyle\frac{3}{4} 43, 4 3 \displaystyle\frac{4}{3} 34 ) 之间的一个数。因为超过这个比例会有明显的失真
- interpolation: 当裁剪出来的图片小于 size 时,就要使用插值方法 resize
PIL.Image.NEAREST
PIL.Image.BILINEAR
PIL.Image.BICUBIC
transforms.RandomResizedCrop(size=224, scale=(0.08, 1))的效果如下,首先随机选择 (0.08, 1) 中 的一个比例缩放,然后随机裁剪出 (224, 224) 大小的图片。
transforms.RandomResizedCrop(size=224, scale=(0.5, 0.5))的效果如下,首先缩放 0.5 倍,然后随机裁剪出 (224, 224) 大小的图片。
transforms.FiveCrop(TenCrop)
torchvision.transforms.FiveCrop(size)
torchvision.transforms.TenCrop(size, vertical_flip=False)
功能:FiveCrop在图像的上下左右以及中心裁剪出尺寸为 size 的 5 张图片。Tencrop对这 5 张图片进行水平或者垂直镜像获得 10 张图片。
- size: 最后裁剪的图片尺寸
- vertical_flip: 是否垂直翻转
由于这两个方法返回的是 tuple,每个元素表示一个图片,我们还需要把这个 tuple 转换为一张图片的tensor。代码如下:
transforms.FiveCrop(112),
transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops]))
并且把transforms.Compose中最后两行注释:
# transforms.ToTensor(), # toTensor()接收的参数是 Image,由于上面已经进行了 toTensor(), 因此这里注释
# transforms.Normalize(norm_mean, norm_std), # 由于是 4 维的 Tensor,因此不能执行 Normalize() 方法
-
transforms.toTensor()接收的参数是 Image,由于上面已经进行了 toTensor()。因此注释这一行。
-
transforms.Normalize()方法接收的是 3 维的 tensor (在 _is_tensor_image()方法 里检查是否满足这一条件,不满足则报错),而经过transforms.FiveCrop返回的是 4 维张量,因此注释这一行。
最后的 tensor 形状是 [ncrops, c, h, w],图片可视化的代码也需要做修改:
## 展示 FiveCrop 和 TenCrop 的图片
ncrops, c, h, w = img_tensor.shape
columns=2 # 两列
rows= math.ceil(ncrops/2) # 计算多少行
# 把每个 tensor ([c,h,w]) 转换为 image
for i in range(ncrops):
img = transform_invert(img_tensor[i], train_transform)
plt.subplot(rows, columns, i+1)
plt.imshow(img)
plt.show()
5 张图片分别是左上角,右上角,左下角,右下角,中心。图片如下:
transforms.TenCrop的操作同理,只是返回的是 10 张图片,在transforms.FiveCrop的基础上多了镜像。
旋转和翻转
transforms.RandomHorizontalFlip(RandomVerticalFlip)
功能:根据概率,在水平或者垂直方向翻转图片
- p: 翻转概率
transforms.RandomHorizontalFlip(p=0.5),那么一半的图片会被水平翻转。
transforms.RandomHorizontalFlip(p=1),那么所有图片会被水平翻转。
transforms.RandomHorizontalFlip(p=1),水平翻转的效果如下。
transforms.RandomVerticalFlip(p=1),垂直翻转的效果如下。
transforms.RandomRotation
torchvision.transforms.RandomRotation(degrees, resample=False, expand=False, center=None, fill=None)
功能:随机旋转图片
-
degree: 旋转角度
- 当为 a 时,在 (-a, a) 之间随机选择旋转角度
- 当为 (a, b) 时,在 (a, b) 之间随机选择旋转角度
-
resample: 重采样方法
-
expand: 是否扩大矩形框,以保持原图信息。根据中心旋转点计算扩大后的图片。如果旋转点不是中心,即使设置 expand = True,还是会有部分信息丢失。
-
center: 旋转点设置,是坐标,默认中心旋转。如设置左上角为:(0, 0)
transforms.RandomRotation(90)的效果如下,shape 为 (224, 224),原来图片的 4 个角有部分信息丢失。
transforms.RandomRotation((90), expand=True)的效果如下,,shape 大于 (224, 224),具体的 shape 的大小会根据旋转角度和原图大小计算。原来图片的 4 个角都保留了下来。
但是需要注意的是,如果设置 expand=True, batch size 大于 1,那么在一个 Batch 中,每张图片的 shape 都不一样了,会报错 Sizes of tensors must match except in dimension 0。所以如果 expand=True,那么还需要进行 resize 操作。
transforms.RandomRotation(30, center=(0, 0)),设置旋转点为左上角,效果如下。
transforms.RandomRotation(30, center=(0, 0), expand=True)的效果如下,如果旋转点不是中心,即使设置 expand = True,还是会有部分信息丢失。
图像变换
Pad
torchvision.transforms.Pad(padding, fill=0, padding_mode='constant')
功能:对图像边缘进行填充
- padding: 设置填充大小
- 当为 a 时,上下左右均填充 a 个像素
- 当为 (a, b) 时,左右填充 a 个像素,上下填充 b 个像素
- 当为 (a, b, c, d) 时,左上右下分别填充 a,b,c,d
- padding_mode: 填充模式,有 4 种模式,constant、edge、reflect、symmetric
- fill: 当 padding_mode 为 constant 时,设置填充的像素值,(R, G, B) 或者 (Gray)
transforms.Pad(padding=32, fill=(255, 0, 0), padding_mode=‘constant’)的效果如下,上下左右的 padding 为 16,填充为 (255, 0, 0)。
transforms.Pad(padding=(8, 64), fill=(255, 0, 0), padding_mode=‘constant’)的效果如下,左右的 padding 为 8,上下的 padding 为 64,填充为 (255, 0, 0)。
transforms.Pad(padding=(8, 16, 32, 64), fill=(255, 0, 0), padding_mode=‘constant’)的效果如下,左、上、右、下的 padding 分别为 8、16、32、64,填充为 (255, 0, 0)。
transforms.Pad(padding=(8, 16, 32, 64), fill=(255, 0, 0), padding_mode=‘symmetric’)的效果如下,镜像填充。这时padding_mode属性不是constant, fill 属性不再生效。
torchvision.transforms.ColorJitter
torchvision.transforms.ColorJitter(brightness=0, contrast=0, saturation=0, hue=0)
功能:调整亮度、对比度、饱和度、色相。在照片的拍照过程中,可能会由于设备、光线问题,造成色彩上的偏差,因此需要调整这些属性,抵消这些因素带来的扰动。
- brightness: 亮度调整因子
- contrast: 对比度参数
- saturation: 饱和度参数
- brightness、contrast、saturation参数:当为 a 时,从 [max(0, 1-a), 1+a] 中随机选择;当为 (a, b) 时,从 [a, b] 中选择。
- hue: 色相参数
-
当为 a 时,从 [-a, a] 中选择参数。其中 0 ≤ a ≤ 0.5 0\le a \le 0.5 0≤a≤0.5。
-
当为 (a, b) 时,从 [a, b] 中选择参数。其中 0 ≤ a ≤ b ≤ 0.5 0 \le a \le b \le 0.5 0≤a≤b≤0.5。
-
transforms.ColorJitter(brightness=0.5)的效果如下。
transforms.ColorJitter(contrast=0.5)的效果如下。
transforms.ColorJitter(saturation=0.5)的效果如下。
transforms.ColorJitter(hue=0.3)的效果如下。
transforms.Grayscale(RandomGrayscale)
torchvision.transforms.Grayscale(num_output_channels=1)
功能:将图片转换为灰度图
- num_output_channels: 输出的通道数。只能设置为 1 或者 3 (如果在后面使用了transforms.Normalize,则要设置为 3,因为transforms.Normalize只能接收 3 通道的输入)
torchvision.transforms.RandomGrayscale(p=0.1, num_output_channels=1)
-
p: 概率值,图像被转换为灰度图的概率
-
num_output_channels: 输出的通道数。只能设置为 1 或者 3
功能:根据一定概率将图片转换为灰度图
transforms.Grayscale(num_output_channels=3)的效果如下。
transforms.RandomAffine
torchvision.transforms.RandomAffine(degrees, translate=None, scale=None, shear=None, resample=False, fillcolor=0)
功能:对图像进行仿射变换,仿射变换是 2 维的线性变换,由 5 种基本操作组成,分别是旋转、平移、缩放、错切和翻转。
-
degree: 旋转角度设置
-
translate: 平移区间设置,如 (a, b),a 设置宽 (width),b 设置高 (height)。图像在宽维度平移的区间为 − i m g w i d t h × a < d x < i m g w i d t h × a - img_width \times a < dx < img_width \times a −imgwidth×a<dx<imgwidth×a,高同理
-
scale: 缩放比例,以面积为单位
-
fillcolor: 填充颜色设置
-
shear: 错切角度设置,有水平错切和垂直错切
- 若为 a,则仅在 x 轴错切,在 (-a, a) 之间随机选择错切角度
- 若为 (a, b),x 轴在 (-a, a) 之间随机选择错切角度,y 轴在 (-b, b) 之间随机选择错切角度
- 若为 (a, b, c, d),x 轴在 (a, b) 之间随机选择错切角度,y 轴在 (c, d) 之间随机选择错切角度
-
resample: 重采样方式,有 NEAREST、BILINEAR、BICUBIC。
transforms.RandomAffine(degrees=30)的效果如下,中心旋转 30 度。
transforms.RandomAffine(degrees=0, translate=(0.2, 0.2)的效果如下,设置水平和垂直的平移比例都为 0.2。
transforms.RandomAffine(degrees=0, scale=(0.7, 0.7))的效果如下,设置宽和高的缩放比例都为 0.7。
transforms.RandomAffine(degrees=0, shear=(0, 0, 0, 45))的效果如下,在 x 轴上不错切,在 y 轴上随机选择 (0, 45) 之间的角度进行错切。
transforms.RandomAffine(degrees=0, shear=90, fillcolor=(255, 0, 0))的效果如下。在 x 轴上随机选择 (-90, 90) 之间的角度进行错切,在 y 轴上不错切。
transforms.RandomErasing
torchvision.transforms.RandomErasing(p=0.5, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=0, inplace=False)
功能:对图像进行随机遮挡。这个操作接收的输入是 tensor。因此在此之前需要先执行transforms.ToTensor()。同时注释掉后面的transforms.ToTensor()。
-
p: 概率值,执行该操作的概率
-
scale: 遮挡区域的面积。如(a, b),则会随机选择 (a, b) 中的一个遮挡比例
-
ratio: 遮挡区域长宽比。如(a, b),则会随机选择 (a, b) 中的一个长宽比
-
value: 设置遮挡区域的像素值。(R, G, B) 或者 Gray,或者任意字符串。由于之前执行了transforms.ToTensor(),像素值归一化到了 0~1 之间,因此这里设置的 (R, G, B) 要除以 255
transforms.RandomErasing(p=1, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=(254/255, 0, 0))的效果如下,从scale=(0.02, 0.33)中随机选择遮挡面积的比例,从ratio=(0.3, 3.3)中随机选择一个遮挡区域的长宽比,value 设置的 RGB 值需要归一化到 0~1 之间。
transforms.RandomErasing(p=1, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=‘fads43’)的效果如下,value 设置任意的字符串,就会使用随机的值填充遮挡区域。
transforms.Lambda
自定义 transform 方法。在上面的FiveCrop中就用到了transforms.Lambda。
transforms.FiveCrop(112, vertical_flip=False),
transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops]))
transforms.FiveCrop返回的是长度为 5 的 tuple,因此需要使用transforms.Lambda 把 tuple 转换为 4D 的 tensor。
transforms 的操作
torchvision.transforms.RandomChoice
torchvision.transforms.RandomChoice([transforms1, transforms2, transforms3])
功能:从一系列 transforms 方法中随机选择一个
transforms.RandomApply
torchvision.transforms.RandomApply([transforms1, transforms2, transforms3], p=0.5)
功能:根据概率执行一组 transforms 操作,要么全部执行,要么全部不执行。
transforms.RandomOrder
transforms.RandomOrder([transforms1, transforms2, transforms3])
对一组 transforms 操作打乱顺序
自定义 transforms
自定义 transforms 有两个要素:仅接受一个参数,返回一个参数;注意上下游的输入与输出,上一个 transform 的输出是下一个 transform 的输入。
我们这里通过自定义 transforms 实现椒盐噪声。椒盐噪声又称为脉冲噪声,是一种随机出现的白点或者黑点,白点称为盐噪声,黑点称为椒噪声。信噪比 (Signal-Noise Rate,SNR) 是衡量噪声的比例,图像中正常像素占全部像素的占比。
我们定义一个AddPepperNoise类,作为添加椒盐噪声的 transform。在构造函数中传入信噪比和概率,在__call__()函数中执行具体的逻辑,返回的是 image。
import numpy as np
import random
from PIL import Image
# 自定义添加椒盐噪声的 transform
class AddPepperNoise(object):
"""增加椒盐噪声
Args:
snr (float): Signal Noise Rate
p (float): 概率值,依概率执行该操作
"""
def __init__(self, snr, p=0.9):
assert isinstance(snr, float) or (isinstance(p, float))
self.snr = snr
self.p = p
# transform 会调用该方法
def __call__(self, img):
"""
Args:
img (PIL Image): PIL Image
Returns:
PIL Image: PIL image.
"""
# 如果随机概率小于 seld.p,则执行 transform
if random.uniform(0, 1) < self.p:
# 把 image 转为 array
img_ = np.array(img).copy()
# 获得 shape
h, w, c = img_.shape
# 信噪比
signal_pct = self.snr
# 椒盐噪声的比例 = 1 -信噪比
noise_pct = (1 - self.snr)
# 选择的值为 (0, 1, 2),每个取值的概率分别为 [signal_pct, noise_pct/2., noise_pct/2.]
# 椒噪声和盐噪声分别占 noise_pct 的一半
# 1 为盐噪声,2 为 椒噪声
mask = np.random.choice((0, 1, 2), size=(h, w, 1), p=[signal_pct, noise_pct/2., noise_pct/2.])
mask = np.repeat(mask, c, axis=2)
img_[mask == 1] = 255 # 盐噪声
img_[mask == 2] = 0 # 椒噪声
# 再转换为 image
return Image.fromarray(img_.astype('uint8')).convert('RGB')
# 如果随机概率大于 seld.p,则直接返回原图
else:
return img
AddPepperNoise(0.9, p=0.5)的效果如下。
完整代码如下:
# -*- coding: utf-8 -*-
import os
import numpy as np
import torch
import random
import math
import torchvision.transforms as transforms
from PIL import Image
from matplotlib import pyplot as plt
from enviroments import rmb_split_dir
from lesson2.transforms.addPepperNoise import AddPepperNoise
def set_seed(seed=1):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
set_seed(1) # 设置随机种子
# 参数设置
MAX_EPOCH = 10
BATCH_SIZE = 1
LR = 0.01
log_interval = 10
val_interval = 1
rmb_label = {"1": 0, "100": 1}
#对 tensor 进行反标准化操作,并且把 tensor 转换为 image,方便可视化。
def transform_invert(img_, transform_train):
"""
将data 进行反transfrom操作
:param img_: tensor
:param transform_train: torchvision.transforms
:return: PIL image
"""
# 如果有标准化操作
if 'Normalize' in str(transform_train):
# 取出标准化的 transform
norm_transform = list(filter(lambda x: isinstance(x, transforms.Normalize), transform_train.transforms))
# 取出均值
mean = torch.tensor(norm_transform[0].mean, dtype=img_.dtype, device=img_.device)
# 取出标准差
std = torch.tensor(norm_transform[0].std, dtype=img_.dtype, device=img_.device)
# 乘以标准差,加上均值
img_.mul_(std[:, None, None]).add_(mean[:, None, None])
# 把 C*H*W 变为 H*W*C
img_ = img_.transpose(0, 2).transpose(0, 1) # C*H*W --> H*W*C
# 把 0~1 的值变为 0~255
img_ = np.array(img_) * 255
# 如果是 RGB 图
if img_.shape[2] == 3:
img_ = Image.fromarray(img_.astype('uint8')).convert('RGB')
# 如果是灰度图
elif img_.shape[2] == 1:
img_ = Image.fromarray(img_.astype('uint8').squeeze())
else:
raise Exception("Invalid img shape, expected 1 or 3 in axis 2, but got {}!".format(img_.shape[2]) )
return img_
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
# 缩放到 (224, 224) 大小,会拉伸
transforms.Resize((224, 224)),
# 1 CenterCrop 中心裁剪
# transforms.CenterCrop(512), # 512
# transforms.CenterCrop(196), # 512
# 2 RandomCrop
# transforms.RandomCrop(224, padding=16),
# transforms.RandomCrop(224, padding=(16, 64)),
# transforms.RandomCrop(224, padding=16, fill=(255, 0, 0)),
# transforms.RandomCrop(512, pad_if_needed=True), # pad_if_needed=True
# transforms.RandomCrop(224, padding=64, padding_mode='edge'),
# transforms.RandomCrop(224, padding=64, padding_mode='reflect'),
# transforms.RandomCrop(1024, padding=1024, padding_mode='symmetric'),
# 3 RandomResizedCrop
# transforms.RandomResizedCrop(size=224, scale=(0.08, 1)),
# transforms.RandomResizedCrop(size=224, scale=(0.5, 0.5)),
# 4 FiveCrop
# transforms.FiveCrop(112),
# 返回的是 tuple,因此需要转换为 tensor
# transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops])),
# 5 TenCrop
# transforms.TenCrop(112, vertical_flip=False),
# transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops])),
# 1 Horizontal Flip
# transforms.RandomHorizontalFlip(p=1),
# 2 Vertical Flip
# transforms.RandomVerticalFlip(p=1),
# 3 RandomRotation
# transforms.RandomRotation(90),
# transforms.RandomRotation((90), expand=True),
# transforms.RandomRotation(30, center=(0, 0)),
# transforms.RandomRotation(30, center=(0, 0), expand=True), # expand only for center rotation
# 1 Pad
# transforms.Pad(padding=32, fill=(255, 0, 0), padding_mode='constant'),
# transforms.Pad(padding=(8, 64), fill=(255, 0, 0), padding_mode='constant'),
# transforms.Pad(padding=(8, 16, 32, 64), fill=(255, 0, 0), padding_mode='constant'),
# transforms.Pad(padding=(8, 16, 32, 64), fill=(255, 0, 0), padding_mode='symmetric'),
# 2 ColorJitter
# transforms.ColorJitter(brightness=0.5),
# transforms.ColorJitter(contrast=0.5),
# transforms.ColorJitter(saturation=0.5),
# transforms.ColorJitter(hue=0.3),
# 3 Grayscale
# transforms.Grayscale(num_output_channels=3),
# 4 Affine
# transforms.RandomAffine(degrees=30),
# transforms.RandomAffine(degrees=0, translate=(0.2, 0.2), fillcolor=(255, 0, 0)),
# transforms.RandomAffine(degrees=0, scale=(0.7, 0.7)),
# transforms.RandomAffine(degrees=0, shear=(0, 0, 0, 45)),
# transforms.RandomAffine(degrees=0, shear=90, fillcolor=(255, 0, 0)),
# 5 Erasing
# transforms.ToTensor(),
# transforms.RandomErasing(p=1, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=(254/255, 0, 0)),
# transforms.RandomErasing(p=1, scale=(0.02, 0.33), ratio=(0.3, 3.3), value='fads43'),
# 1 RandomChoice
# transforms.RandomChoice([transforms.RandomVerticalFlip(p=1), transforms.RandomHorizontalFlip(p=1)]),
# 2 RandomApply
# transforms.RandomApply([transforms.RandomAffine(degrees=0, shear=45, fillcolor=(255, 0, 0)),
# transforms.Grayscale(num_output_channels=3)], p=0.5),
# 3 RandomOrder
# transforms.RandomOrder([transforms.RandomRotation(15),
# transforms.Pad(padding=32),
# transforms.RandomAffine(degrees=0, translate=(0.01, 0.1), scale=(0.9, 1.1))]),
AddPepperNoise(0.9, p=0.5),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
path_img=os.path.join(rmb_split_dir, "train", "100","0A4DSPGE.jpg")
img = Image.open(path_img).convert('RGB') # 0~255
img=transforms.Resize((224, 224))(img)
img_tensor = train_transform(img)
## 展示单张图片
# 这里把转换后的 tensor 再转换为图片
convert_img=transform_invert(img_tensor, train_transform)
plt.subplot(1, 2, 1)
plt.imshow(img)
plt.subplot(1, 2, 2)
plt.imshow(convert_img)
plt.show()
plt.pause(0.5)
plt.close()
## 展示 FiveCrop 和 TenCrop 的图片
# ncrops, c, h, w = img_tensor.shape
# columns=2 # 两列
# rows= math.ceil(ncrops/2) # 计算多少行
# # 把每个 tensor ([c,h,w]) 转换为 image
# for i in range(ncrops):
# img = transform_invert(img_tensor[i], train_transform)
# plt.subplot(rows, columns, i+1)
# plt.imshow(img)
# plt.show()
数据增强实战应用
数据增强的原则是需要我们观察训练集和测试集之间的差异,然后应用有效的数增强,使得训练集和测试集更加接近。
比如下图中的数据集,训练集中的猫是居中,而测试集中的猫可能是偏左、偏上等位置的。这时可以使用平移来做训练集数据增强。
在下图的数据集中,训练集中白猫比较多,测试集中黑猫比较多,这时可以对训练集的数做色彩方面的增强。而猫的姿态各异,所以可从仿射变换上做数据增强。还可以采用遮挡、填充等数据增强。
我们在上个人民币二分类实验中,使用的是第四套人民币。但是在这个数据集上训练的模型不能够很准确地对第五套人民币进行分类。下图是 3 种图片的对比,第四套 1 元人民币和第五套 100 元人民币都比较偏红,因此容易把第五套 100 元人民币分类成 1 元人民币。
而实际测试中,训练完的模型在第五套 100 元人民币上错误率高,第五套 100 元人民币分类成 1 元人民币。
在 transforms中添加了灰度变换transforms.RandomGrayscale(p=0.9),把所有图片变灰,减少整体颜色带来的偏差,准确率有所上升。
整理不易🚀🚀,关注和收藏后拿走📌📌欢迎留言🧐👋📣✨
快来关注我的公众号🔎AdaCoding 和 GitHub🔎 AdaCoding123

















 3419
3419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









