









写在前面
本文主要针对使用GD(兆易创新)系列的FLASH做启动配置片时,遇到的相关问题进行简单整理复盘,避免后人踩坑。
本人操作固化芯片型号为:ZYNQ7045、690T(复旦微替代型号V7 690T)。
7系列FPGA固化
由于GD SPI Flash器件和进口器件的厂家ID不一致,而Vivado软件又不支持跳过ID检查,导致使用GD Flash做FPGA配置片时,无法通过Vivado软件直接烧录。
常见方法有两个,一个是通过TCL脚本加自定义桥接位流的方式,另外一个是通过ISE的IMPACT调过核查ID的操作。
通过TCL脚本加自定义桥接位流的方式,在Vivado平台上实现对FLASH配置片的直接烧录。该方法工作量较大,且不同国产芯片的相关修改配置不同,很难做到兼容处理,且需要相关公司的技术部门对相关操作(如烧写FLASH的相关文件进行替换)进行完善处理,操作难度较大。
通过ISE的IMPACT跳过核查ID的操作,只需要安装ISE版本(推荐安装14.7)的软件,添加环境变量进行固化操作即可。
添加跳过IDCODE核查环境变量
安装xilinx ISE14.7后,打开电脑的环境变量,配置IMPACT跳过ID核查,变量名输入:XIL_IMPACT_SKIPIDCODECHECK,变量值设置为1。
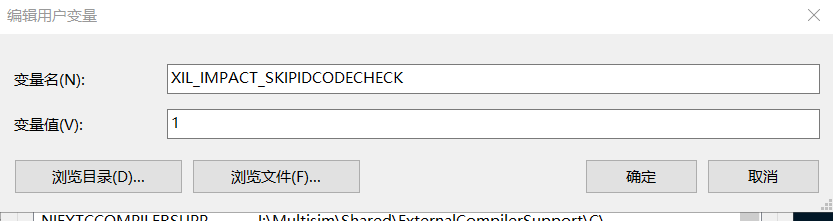
完成设置后重启电脑即可生效。
制作MCS文件
找到ISE的IMPACT,双击创建PROM文件,如选择SPI器件,如图示操作进行选择FLASH固化文件的配置。
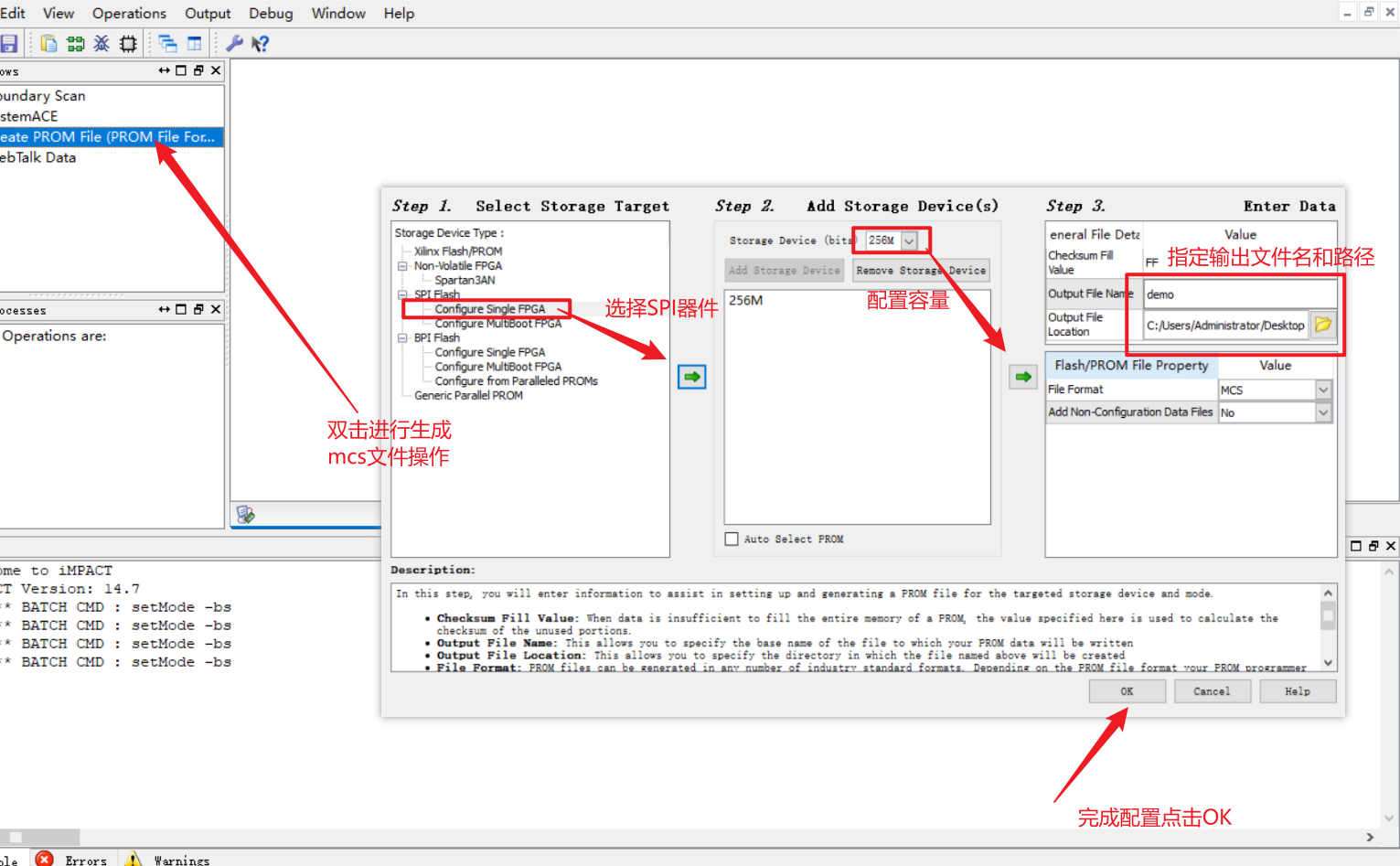
点击OK后弹出以下界面。
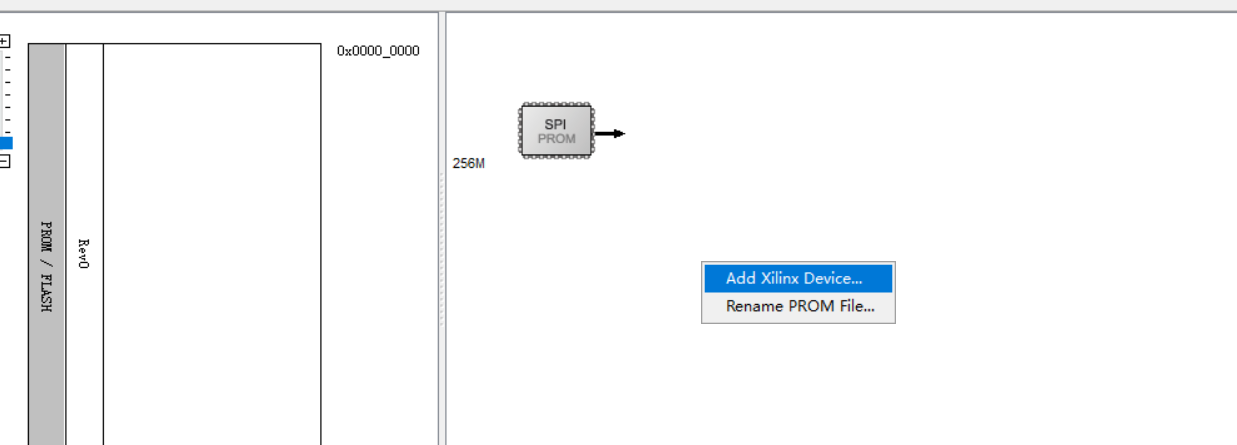
添加XILINX器件,添加固化所需要的bit文件,右键点击生成文件。
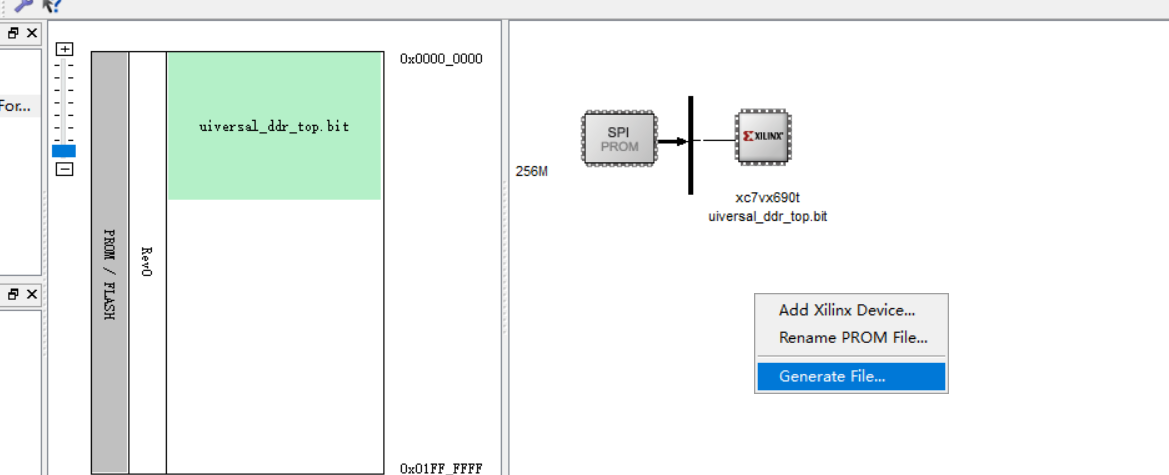
生成成功。
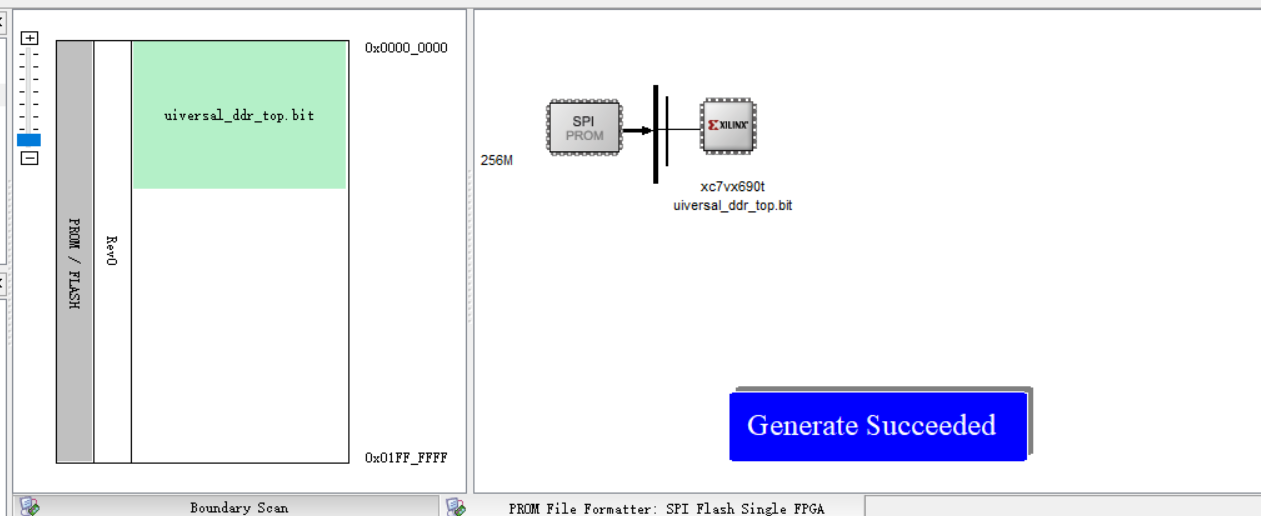
连接板卡后,选择初始化链路,添加xilinx器件,和固化的SPI或者BPI FLASH,操作步骤同ISE固化步骤。
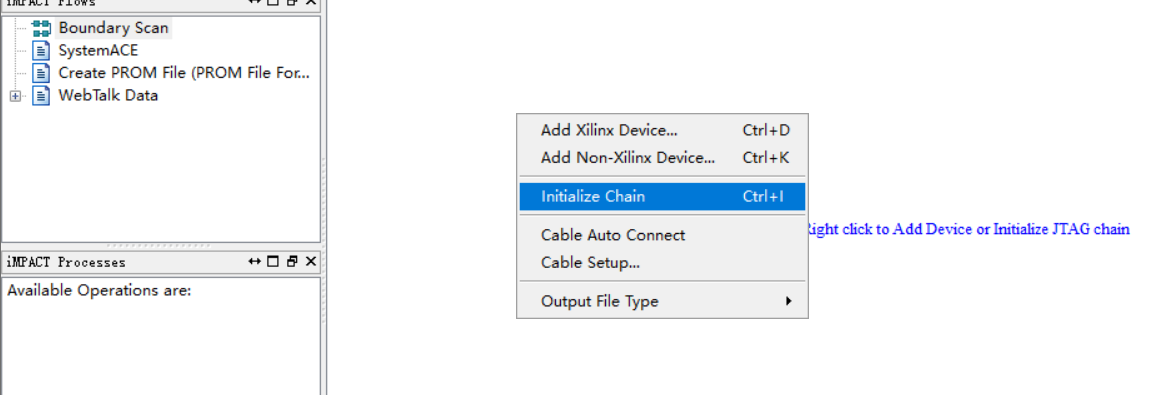
选择下载固化的mcs文件,点击烧写固化。
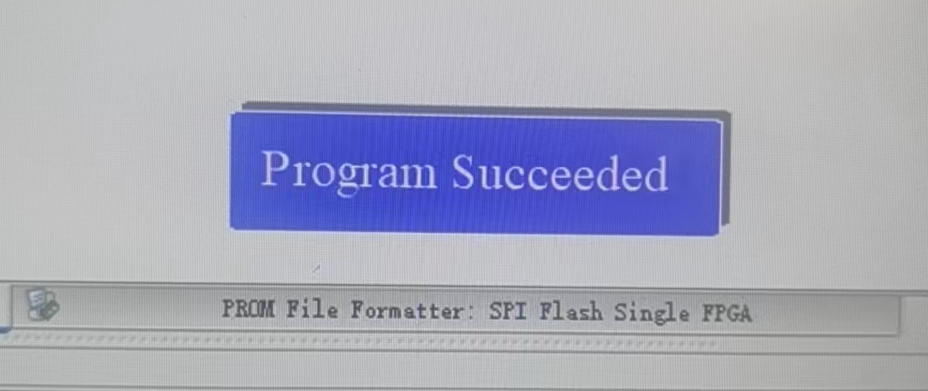
固化成功后应显示如下界面:
ZYNQ固化
ZYNQ固化参考提供的GD固化指导文件,将软件路径下的Uboot文件夹下的zynq_qspi_xx_xxxx.bin文件进行替换,本质应还是修改BIN文件后调过器件ID核查。

由于ZYNQ可以使用vivado进行固化,也可以使用SDK进行固化(高版本叫vitis,道理相同),所以根据使用软件替换掉相应的BIN文件,即可完成ZYNQ芯片的固化。
FSBL文件以及ZYNQ的镜像文件按正常步骤进行操作生成,无需进行额外修改。
找到软件安装路径,找到uboot文件夹,路径如下:
../../Xilinx/Vivado/2021.1/data/xicom/cfgmem/uboot
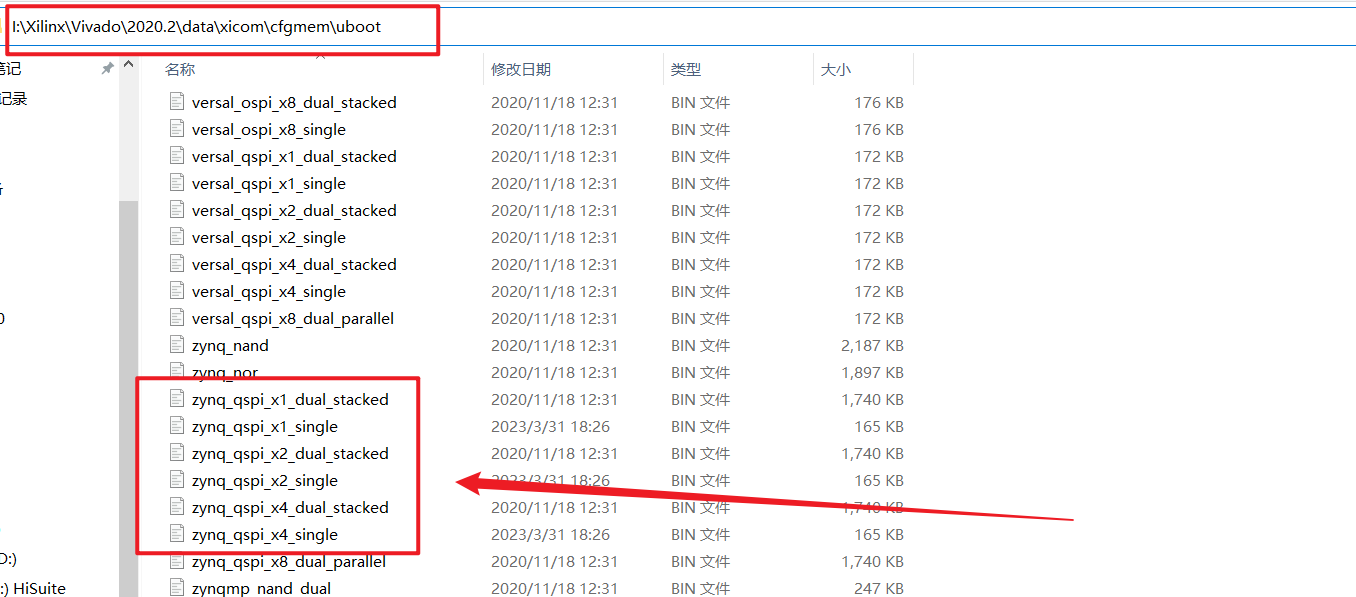
使用GD提供的qspi.bin文件替换掉软件自带的bin文件。
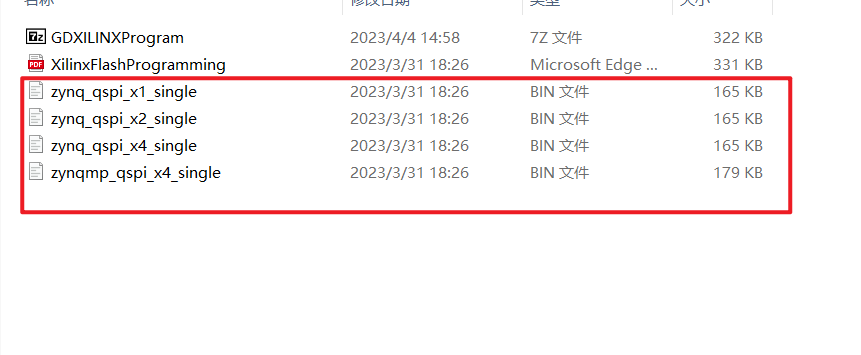
依据GD建议选择的MX型号的FLASH,选择相应容量的FLASH进行固化,即可。
如果使用SDK或者Vitis,选择相应版本的软件找到uboot路径,
Vitis路径如下:
../../Xilinx/Vitis/2021.1/data/xicom/cfgmem/uboot
SDK路径如下:
../../Xilinx/SDK/2018.3/data/xicom/cfgmem/uboot
完成替换后,使用SDK固化(vitis固化)操作同常规操作。
小结
GD系列FPGA和ZYNQ固化所需文件:https://download.csdn.net/download/weixin_41445387/90523735?spm=1001.2014.3001.5503。



















 7756
7756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











