







简介
在快速发展的人工智能领域,语言模型变得越来越复杂,不断挑战着机器所能理解和生成的极限。在这些进步中,INTELLECT-1 是一项开创性的成就。INTELLECT-1 由 Prime Intellect 和贡献者社区共同开发,是首个协作训练的 100 亿参数语言模型,是自然语言处理领域的一个重要里程碑。
训练方法
INTELLECT-1 是在一个包含 1 万亿个英文文本和代码的庞大语料库上从头开始训练的,以确保对语言及其细微差别的全面理解。训练过程分布在 3 个大洲的 14 个并发节点上,充分利用了 30 个独立社区贡献者的计算能力。这种合作方式不仅加快了培训进程,还引入了不同的视角和专业知识。
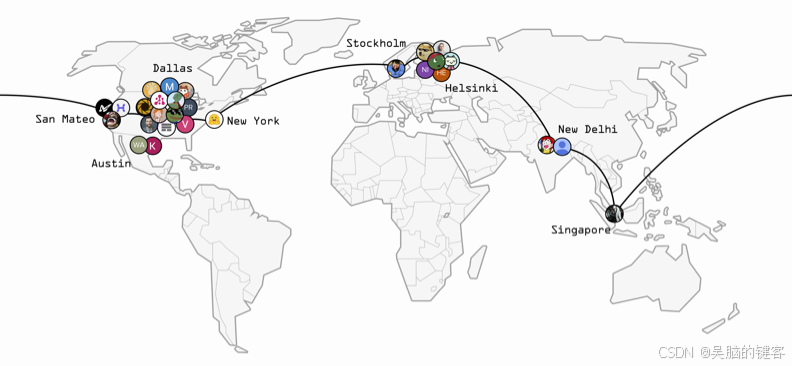
培训代码采用了 prime 框架,这是一个可扩展的分布式培训框架,专为在不可靠的全球分布式工作者上进行容错、动态扩展和高性能培训而设计。实现动态扩展的关键在于 ElasticDeviceMesh,它可以管理动态的全局进程组,用于互联网上的容错通信,也可以管理本地进程组,用于节点内的通信。
技术规格
INTELLECT-1 拥有令人印象深刻的技术规格,包括 10B 的参数大小、42 层、32 个注意头、4096 的隐藏大小、8192 的上下文长度和 128256 的词汇量。这些技术指标有助于提高模型处理和生成复杂语言结构的能力。
| Parameter | Value |
|---|---|
| Parameter Size | 10B |
| Number of Layers | 42 |
| Number of Attention Heads | 32 |
| Hidden Size | 4096 |
| Context Length | 8192 |
| Vocabulary Size | 128256 |
训练细节
INTELLECT-1 的训练数据集经过精心设计,包括 55% 的 fineweb-edu、10% 的 fineweb、20% 的 Stack V1、10% 的 dclm-baseline 和 5% 的 open-web-math。这种多样化的数据集确保了模型能接触到广泛的语言模式和语境。训练过程使用了 DiLoCo 算法的 100 个内部步骤,并使用定制的 int8 all-reduce 内核执行全局 all-reduce,以显著减少通信开销。
代码
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
torch.set_default_device("cuda")
model = AutoModelForCausalLM.from_pretrained("PrimeIntellect/INTELLECT-1")
tokenizer = AutoTokenizer.from_pretrained("PrimeIntellect/INTELLECT-1")
input_text = "What is the Metamorphosis of Prime Intellect about?"
input_ids = tokenizer.encode(input_text, return_tensors="pt")
output_ids = model.generate(input_ids, max_length=50, num_return_sequences=1)
output_text = tokenizer.decode(output_ids[0], skip_special_tokens=True)
print(output_text)
文本生成Pipeline
import torch
from transformers import pipeline
torch.set_default_device("cuda")
pipe = pipeline("text-generation", model="PrimeIntellect/INTELLECT-1")
print(pipe("What is prime intellect ?"))
性能和基准测试
INTELLECT-1 在 MMLU、GPQA、GSM8K、ARC-C 和 Hellaswag 等各种基准测试中都表现出了卓越的性能。该模型理解和生成连贯文本的能力已经过广泛的测试和验证,展示了其在广泛应用中的潜力。
Base
| Model | Size | Tokens | MMLU | GPQA | GSM8K | ARC-C | Hellaswag |
|---|---|---|---|---|---|---|---|
| INTELLECT | 10B | 1T | 37.5 | 26.12 | 8.1 | 52.13 | 72.26 |
| MPT-7B | 7B | 1T | 26.8 | 25.67 | 8.3 | 46.67 | 77.41 |
| Falcon-7B | 7B | 1.5T | 26.2 | 23.66 | 4.9 | 47.61 | 78.23 |
| Pythia-12B | 12B | 300B | 26.5 | 24.33 | 4.09 | 40.61 | 68.83 |
| LLM360-Amber | 7B | 1.3T | 24.5 | 27.01 | 4.32 | 42.75 | 74.08 |
| LLaMA-7B | 7B | 1T | 35.1 | 23.21 | 9.7 | 50.43 | 78.19 |
| LLaMA-13B | 13B | 1T | 46.9 | 26.34 | 17.3 | 56.14 | 81.05 |
| LLaMA2-7B | 7B | 2T | 45.3 | 25.89 | 13.5 | 54.10 | 78.64 |
| LLaMA2-13B | 13B | 2T | 54.8 | 25.67 | 24.3 | 59.81 | 82.58 |
Instruction
| Model | Size | Tokens | MMLU | GPQA | GSM8K | ARC-C | Hellaswag |
|---|---|---|---|---|---|---|---|
| INTELLECT-Instruct | 10B | 1T | 49.89 | 28.32 | 38.58 | 54.52 | 71.42 |
| MPT-7B-Chat | 7B | 1T | 36.29 | 26.79 | 8.26 | 51.02 | 75.88 |
| Falcon-7B-Instruct | 7B | 1.5T | 25.21 | 26.34 | 4.93 | 45.82 | 70.61 |
| LLM360-AmberChat | 7B | 1.4T | 36.02 | 27.23 | 6.14 | 43.94 | 73.94 |
| LLaMA2-7B-Chat | 7B | 2T | 47.20 | 28.57 | 23.96 | 53.33 | 78.69 |
| LLaMA2-13B-Chat | 13B | 2T | 53.51 | 28.35 | 37.15 | 59.73 | 82.47 |
结论
INTELLECT-1 代表了语言模型开发领域的一次重大飞跃,展示了协作训练和分布式计算的强大威力。其令人印象深刻的技术指标和在各种基准测试中的表现,使其成为研究人员、开发人员和企业利用先进语言模型潜力的宝贵工具。随着自然语言处理领域的不断发展,INTELLECT-1 无疑将在塑造人机交互的未来方面发挥关键作用。

















 1062
1062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









