







SmolVLM 是一个紧凑的开放式多模态模型,可接受任意序列的图像和文本输入,从而生成文本输出。 SmolVLM 专为提高效率而设计,它可以回答有关图像的问题、描述视觉内容、创建基于多幅图像的故事,或者作为一个纯粹的语言模型在没有视觉输入的情况下发挥作用。 其轻量级架构使其适用于设备应用,同时在多模态任务中保持强劲的性能。

模型概要
- 开发者: Hugging Face 🤗
- 模型类型: 多模态模型(图像+文本)
- 语言 (NLP): 英语
- 许可协议: Apache 2.0
- 架构: 基于 Idefics3(参见技术摘要)
使用
SmolVLM 可用于多模态(图像 + 文本)任务的推理,其中输入包括文本查询和一张或多张图像。 文本和图像可以任意交错,从而实现图像字幕、视觉问题解答和基于视觉内容的故事讲述等任务。 该模型不支持图像生成。
要在特定任务中对 SmolVLM 进行微调,您可以参考微调教程。
技术摘要
SmolVLM 利用轻量级 SmolLM2 语言模型,提供紧凑而强大的多模态体验。 与之前的 Idefics 模型相比,它引入了若干变化:
- 图像压缩:与 Idefics3 相比,我们对图像进行了更彻底的压缩,从而使模型能够更快地推断并使用更少的 RAM。
- 视觉标记编码: SmolVLM 使用 81 个视觉标记对大小为 384×384 的图像片段进行编码。 较大的图像被分割成不同的片段,每个片段单独编码,从而在不影响性能的情况下提高了效率。
有关培训和架构的更多详情,请参阅我们的技术报告。
如何开始
您可以使用变压器来加载、推断和微调 SmolVLM。
import torch
from PIL import Image
from transformers import AutoProcessor, AutoModelForVision2Seq
from transformers.image_utils import load_image
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
# Load images
image1 = load_image("https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg")
image2 = load_image("https://huggingface.co/spaces/merve/chameleon-7b/resolve/main/bee.jpg")
# Initialize processor and model
processor = AutoProcessor.from_pretrained("HuggingFaceTB/SmolVLM-Instruct")
model = AutoModelForVision2Seq.from_pretrained(
"HuggingFaceTB/SmolVLM-Instruct",
torch_dtype=torch.bfloat16,
_attn_implementation="flash_attention_2" if DEVICE == "cuda" else "eager",
).to(DEVICE)
# Create input messages
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "image"},
{"type": "text", "text": "Can you describe the two images?"}
]
},
]
# Prepare inputs
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, images=[image1, image2], return_tensors="pt")
inputs = inputs.to(DEVICE)
# Generate outputs
generated_ids = model.generate(**inputs, max_new_tokens=500)
generated_texts = processor.batch_decode(
generated_ids,
skip_special_tokens=True,
)
print(generated_texts[0])
"""
Assistant: The first image shows a green statue of the Statue of Liberty standing on a stone pedestal in front of a body of water.
The statue is holding a torch in its right hand and a tablet in its left hand. The water is calm and there are no boats or other objects visible.
The sky is clear and there are no clouds. The second image shows a bee on a pink flower.
The bee is black and yellow and is collecting pollen from the flower. The flower is surrounded by green leaves.
"""
模型优化
精度: 如果硬件支持半精度(torch.float16 或 torch.bfloat16),则以半精度加载和运行模型,以获得更好的性能。
from transformers import AutoModelForVision2Seq
import torch
model = AutoModelForVision2Seq.from_pretrained(
"HuggingFaceTB/SmolVLM-Instruct",
torch_dtype=torch.bfloat16
).to("cuda")
您也可以使用 bitsandbytes、torchao 或 Quanto 以 4/8 位量化方式加载 SmolVLM。 有关其他选项,请参阅本页。
from transformers import AutoModelForVision2Seq, BitsAndBytesConfig
import torch
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
model = AutoModelForVision2Seq.from_pretrained(
"HuggingFaceTB/SmolVLM-Instruct",
quantization_config=quantization_config,
)
视觉编码器效率: 在初始化处理器时,通过设置 size={“longest_edge”: N*384},其中 N 为所需值。 默认的 N=4 效果很好,可以生成 1536×1536 尺寸的输入图像。 对于文档,N=5 可能会有好处。 减少 N 可以节省 GPU 内存,适用于低分辨率图像。 如果想对视频进行微调,这也很有用。
误用和超范围使用
SmolVLM 不适用于影响个人福祉或生计的高风险情景或关键决策过程。 该模型可能会生成看似真实但可能并不准确的内容。 滥用包括但不限于
- 禁止用途:
- 对个人进行评估或评分(如在就业、教育、信贷方面)
- 关键的自动决策
- 生成不可靠的事实内容
- 恶意活动:
- 制作垃圾邮件
- 制造虚假信息
- 骚扰或虐待
- 未经授权的监视
训练详情
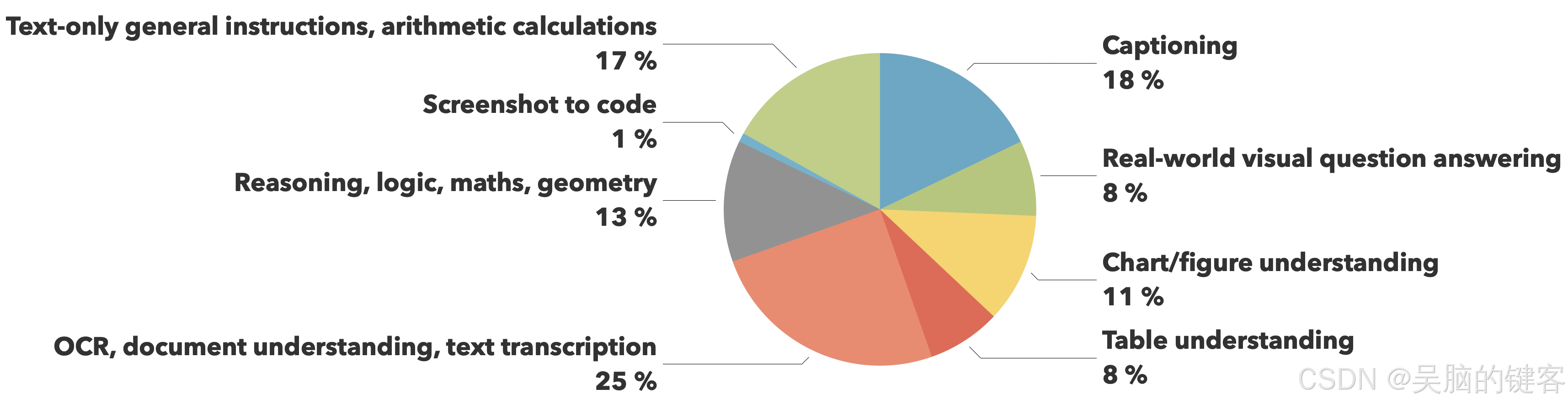
训练数据来自 The Cauldron 和 Docmatix 数据集,重点是文档理解(25%)和图像标题(18%),同时保持其他关键能力(如视觉推理、图表理解和一般指令遵循)的均衡覆盖。
评估
| Model | MMMU (val) | MathVista (testmini) | MMStar (val) | DocVQA (test) | TextVQA (val) | Min GPU RAM required (GB) |
|---|---|---|---|---|---|---|
| SmolVLM | 38.8 | 44.6 | 42.1 | 81.6 | 72.7 | 5.02 |
| Qwen-VL 2B | 41.1 | 47.8 | 47.5 | 90.1 | 79.7 | 13.70 |
| InternVL2 2B | 34.3 | 46.3 | 49.8 | 86.9 | 73.4 | 10.52 |
| PaliGemma 3B 448px | 34.9 | 28.7 | 48.3 | 32.2 | 56.0 | 6.72 |
| moondream2 | 32.4 | 24.3 | 40.3 | 70.5 | 65.2 | 3.87 |
| MiniCPM-V-2 | 38.2 | 39.8 | 39.1 | 71.9 | 74.1 | 7.88 |
| MM1.5 1B | 35.8 | 37.2 | 0.0 | 81.0 | 72.5 | NaN |
资源
- 演示:SmolVLM 演示
- 博客:博文


















 111
111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









