







❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发非常感兴趣,我会每日跟你分享最新的 AI 资讯和开源应用,也会不定期分享自己的想法和开源实例,欢迎关注我哦!
🥦 微信公众号|搜一搜:蚝油菜花 🥦
🚀 快速阅读
模型简介:SmolVLM是Hugging Face推出的轻量级视觉语言模型,专为设备端推理设计,具有高效内存占用和快速处理速度。
主要功能:提供设备端推理、微调能力、优化的架构设计、处理长文本和多张图像、低内存占用和高吞吐量。
应用场景:视频分析、视觉语言处理、本地部署和AI普及化。
正文(附运行示例)
SmolVLM 是什么
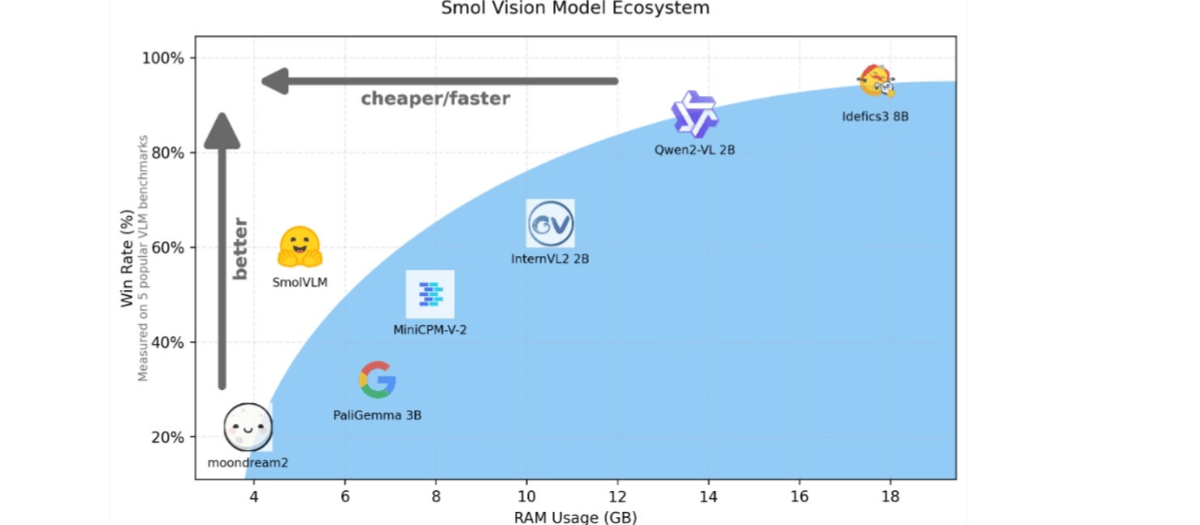
SmolVLM是Hugging Face推出的轻量级视觉语言模型,专为设备端推理设计。以20亿参数量,实现了高效内存占用和快速处理速度。SmolVLM提供了三个版本以满足不同需求:SmolVLM-Base:适用于下游任务的微调。SmolVLM-Synthetic:基于合成数据进行微调。SmolVLM-Instruct:指令微调版本,可直接应用于交互式应用中。
模型借鉴Idefics3理念,采用SmolLM2 1.7B作为语言主干,通过像素混洗技术提升视觉信息压缩效率。在Cauldron和Docmatix数据集上训练,优化了图像编码和文本处理能力。
SmolVLM 的主要功能
- 设备端推理:SmolVLM专为设备端推理设计,能在笔记本电脑、消费级GPU或移动设备等资源有限的环境下有效运行。
- 微调能力:模型提供三个版本以满足不同需求:SmolVLM-Base用于下游任务的微调;SmolVLM-Synthetic基于合成数据进行微调;SmolVLM-Instruct指令微调版本,可直接应用于交互式应用中。
- 优化的架构设计:借鉴Idefics3的理念,使用SmolLM2 1.7B作为语言主干,通过像素混洗策略提高视觉信息的压缩率,实现更高效的视觉信息处理。
- 处理长文本和多张图像:训练数据集包括Cauldron和Docmatix,对SmolLM2进行上下文扩展,能处理更长的文本序列和多张图像。
- 内存占用低:SmolVLM将384×384像素的图像块编码为81个tokens,相比之下,Qwen2-VL需要1.6万个tokens,显著降低了内存占用。
- 高吞吐量:在多个基准测试中,SmolVLM的预填充吞吐量比Qwen2-VL快3.3到4.5倍,生成吞吐量快7.5到16倍。
SmolVLM 的技术原理
- 架构设计:借鉴Idefics3的架构,使用SmolLM2 1.7B作为语言主干,通过像素混洗策略提高视觉信息的压缩率。
- 图像编码:将384×384像素的图像块编码为81个tokens,显著降低内存占用。
- 上下文扩展:通过扩展上下文窗口至16k tokens,支持处理更长的文本序列和多张图像。
如何运行 SmolVLM
以下是一个简单的代码示例,展示如何使用SmolVLM进行图像和文本的交互式处理。
from transformers import AutoProcessor, AutoModelForVision2Seq
import torch
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
processor = AutoProcessor.from_pretrained("HuggingFaceTB/SmolVLM-Instruct")
model = AutoModelForVision2Seq.from_pretrained("HuggingFaceTB/SmolVLM-Instruct",
torch_dtype=torch.bfloat16,
_attn_implementation="flash_attention_2" if DEVICE == "cuda" else "eager").to(DEVICE)
from PIL import Image
from transformers.image_utils import load_image
# Load images
image1 = load_image("https://huggingface.co/spaces/HuggingFaceTB/SmolVLM/resolve/main/example_images/rococo.jpg")
image2 = load_image("https://huggingface.co/spaces/HuggingFaceTB/SmolVLM/blob/main/example_images/rococo_1.jpg")
# Create input messages
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "image"},
{"type": "text", "text": "Can you describe the two images?"}
]
},
]
# Prepare inputs
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, images=[image1, image2], return_tensors="pt")
inputs = inputs.to(DEVICE)
# Generate outputs
generated_ids = model.generate(**inputs, max_new_tokens=500)
generated_texts = processor.batch_decode(
generated_ids,
skip_special_tokens=True,
)
print(generated_texts[0])
资源
- 项目官网:https://huggingface.co/blog/smolvlm
- GitHub 仓库:https://github.com/huggingface/blog/blob/main/smolvlm.md
- HuggingFace 模型库:https://huggingface.co/blog/smolvlm
- 在线体验 Demo:https://huggingface.co/spaces/HuggingFaceTB/SmolVLM
- 数据集完整列表:https://huggingface.co/HuggingFaceTB/SmolVLM-Instruct/blob/main/smolvlm-data.pdf
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发非常感兴趣,我会每日跟你分享最新的 AI 资讯和开源应用,也会不定期分享自己的想法和开源实例,欢迎关注我哦!
🥦 微信公众号|搜一搜:蚝油菜花 🥦

















 1192
1192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









