







Llama-3.1-Nemotron-Nano-4B-v1.1 是一个大型语言模型(LLM),它是 nvidia/Llama-3.1-Minitron-4B-Width-Base 的衍生版本,而后者是通过我们的 LLM 压缩技术从 Llama 3.1 8B 创建的,并在模型准确性和效率方面提供了改进。它是一个推理模型,经过后训练以增强推理能力、人类聊天偏好以及任务处理能力,例如 RAG 和工具调用。
Llama-3.1-Nemotron-Nano-4B-v1.1 是一个在模型准确性和效率之间提供了良好平衡的模型。该模型可以适配到单个 RTX GPU 上,并可以在本地使用。该模型支持 128K 的上下文长度。
该模型经历了多阶段的后训练过程,以增强其推理和非推理能力。这包括针对数学、代码、推理和工具调用的监督微调阶段,以及使用奖励感知偏好优化(RPO)算法进行的多个强化学习(RL)阶段,用于聊天和指令跟随。最终模型检查点是在合并最终的 SFT 和 RPO 检查点后获得的。
该模型是Llama Nemotron系列的一部分。您可以在此处找到该系列中的其他模型:
该模型已准备好用于商业用途。
参考文献
- [2408.11796] LLM Pruning and Distillation in Practice: The Minitron Approach
- [2502.00203] Reward-aware Preference Optimization: A Unified Mathematical Framework for Model Alignment
- [2505.00949] Llama-Nemotron: Efficient Reasoning Models
Llama-3.1-Nemotron-Nano-4B-v1.1 是一个通用的推理和聊天模型,旨在用于英语和编程语言。还支持其他非英语语言(德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语)。
输入:
- 输入类型:文本
- 输入格式:字符串
- 输入参数:一维(1D)
- 与输入相关的其他属性:上下文长度最多为 131,072 个标记
输出:
- 输出类型:文本
- 输出格式:字符串
- 输出参数:一维(1D)
- 与输出相关的其他属性:上下文长度最多为 131,072 个标记
快速开始和使用建议:
- 推理模式(开启/关闭)通过系统提示控制,必须按照以下示例进行设置。所有指令应包含在用户提示中
- 我们建议在推理开启模式下,将温度设置为0.6,Top P设置为0.95
- 我们建议在推理关闭模式下使用贪婪解码
- 我们为每个需要特定模板的基准测试提供了用于评估的提示列表
请参阅以下代码片段以使用Hugging Face Transformers库。推理模式(开启/关闭)通过系统提示控制。请参见以下示例。我们的代码要求transformers包的版本为4.44.2或更高。
“Reasoning On:”例子
import torch
import transformers
model_id = "nvidia/Llama-3.1-Nemotron-Nano-4B-v1.1"
model_kwargs = {"torch_dtype": torch.bfloat16, "device_map": "auto"}
tokenizer = transformers.AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token_id = tokenizer.eos_token_id
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
tokenizer=tokenizer,
max_new_tokens=32768,
temperature=0.6,
top_p=0.95,
**model_kwargs
)
# Thinking can be "on" or "off"
thinking = "on"
print(pipeline([{"role": "system", "content": f"detailed thinking {thinking}"}, {"role": "user", "content": "Solve x*(sin(x)+2)=0"}]))
“Reasoning Off:”
import torch
import transformers
model_id = "nvidia/Llama-3.1-Nemotron-Nano-4B-v1"
model_kwargs = {"torch_dtype": torch.bfloat16, "device_map": "auto"}
tokenizer = transformers.AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token_id = tokenizer.eos_token_id
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
tokenizer=tokenizer,
max_new_tokens=32768,
do_sample=False,
**model_kwargs
)
# Thinking can be "on" or "off"
thinking = "off"
print(pipeline([{"role": "system", "content": f"detailed thinking {thinking}"}, {"role": "user", "content": "Solve x*(sin(x)+2)=0"}]))
对于一些提示,即使禁用了思考功能,模型仍会自发地倾向于在回答前进行思考。但如果需要,用户可以通过预先填充助手的回答来防止这种情况。
import torch
import transformers
model_id = "nvidia/Llama-3.1-Nemotron-Nano-4B-v1.1"
model_kwargs = {"torch_dtype": torch.bfloat16, "device_map": "auto"}
tokenizer = transformers.AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token_id = tokenizer.eos_token_id
# Thinking can be "on" or "off"
thinking = "off"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
tokenizer=tokenizer,
max_new_tokens=32768,
do_sample=False,
**model_kwargs
)
print(pipeline([{"role": "system", "content": f"detailed thinking {thinking}"}, {"role": "user", "content": "Solve x*(sin(x)+2)=0"}, {"role":"assistant", "content":"<think>\n</think>"}]))
运行支持工具调用的 vLLM 服务器
Llama-3.1-Nemotron-Nano-4B-v1.1 支持工具调用。此 HF 仓库托管了一个工具调用解析器以及一个 Jinja 聊天模板,可用于启动 vLLM 服务器。
以下是一个启动支持工具调用的 vLLM 服务器的 shell 脚本示例。vllm/vllm-openai:v0.6.6 或更新版本应支持该模型。
#!/bin/bash
CWD=$(pwd)
PORT=5000
git clone https://huggingface.co/nvidia/Llama-3.1-Nemotron-Nano-4B-v1.1
docker run -it --rm \
--runtime=nvidia \
--gpus all \
--shm-size=16GB \
-p ${PORT}:${PORT} \
-v ${CWD}:${CWD} \
vllm/vllm-openai:v0.6.6 \
--model $CWD/Llama-3.1-Nemotron-Nano-4B-v1.1 \
--trust-remote-code \
--seed 1 \
--host "0.0.0.0" \
--port $PORT \
--served-model-name "Llama-Nemotron-Nano-4B-v1.1" \
--tensor-parallel-size 1 \
--max-model-len 131072 \
--gpu-memory-utilization 0.95 \
--enforce-eager \
--enable-auto-tool-choice \
--tool-parser-plugin "${CWD}/Llama-3.1-Nemotron-Nano-4B-v1.1/llama_nemotron_nano_toolcall_parser.py" \
--tool-call-parser "llama_nemotron_json" \
--chat-template "${CWD}/Llama-3.1-Nemotron-Nano-4B-v1.1/llama_nemotron_nano_generic_tool_calling.jinja"
或者,你可以使用虚拟环境来启动一个vLLM服务器,如下所示。
$ git clone https://huggingface.co/nvidia/Llama-3.1-Nemotron-Nano-4B-v1.1
$ conda create -n vllm python=3.12 -y
$ conda activate vllm
$ python -m vllm.entrypoints.openai.api_server \
--model Llama-3.1-Nemotron-Nano-4B-v1.1 \
--trust-remote-code \
--seed 1 \
--host "0.0.0.0" \
--port 5000 \
--served-model-name "Llama-Nemotron-Nano-4B-v1.1" \
--tensor-parallel-size 1 \
--max-model-len 131072 \
--gpu-memory-utilization 0.95 \
--enforce-eager \
--enable-auto-tool-choice \
--tool-parser-plugin "Llama-3.1-Nemotron-Nano-4B-v1.1/llama_nemotron_nano_toolcall_parser.py" \
--tool-call-parser "llama_nemotron_json" \
--chat-template "Llama-3.1-Nemotron-Nano-4B-v1.1/llama_nemotron_nano_generic_tool_calling.jinja"
启动 vLLM 服务器后,您可以使用如下所示的 Python 脚本调用支持工具调用的服务器。
from openai import OpenAI
client = OpenAI(
completion = client.chat.completions.create(
completion.choices[0].message.content
completion.choices[0].message.tool_calls
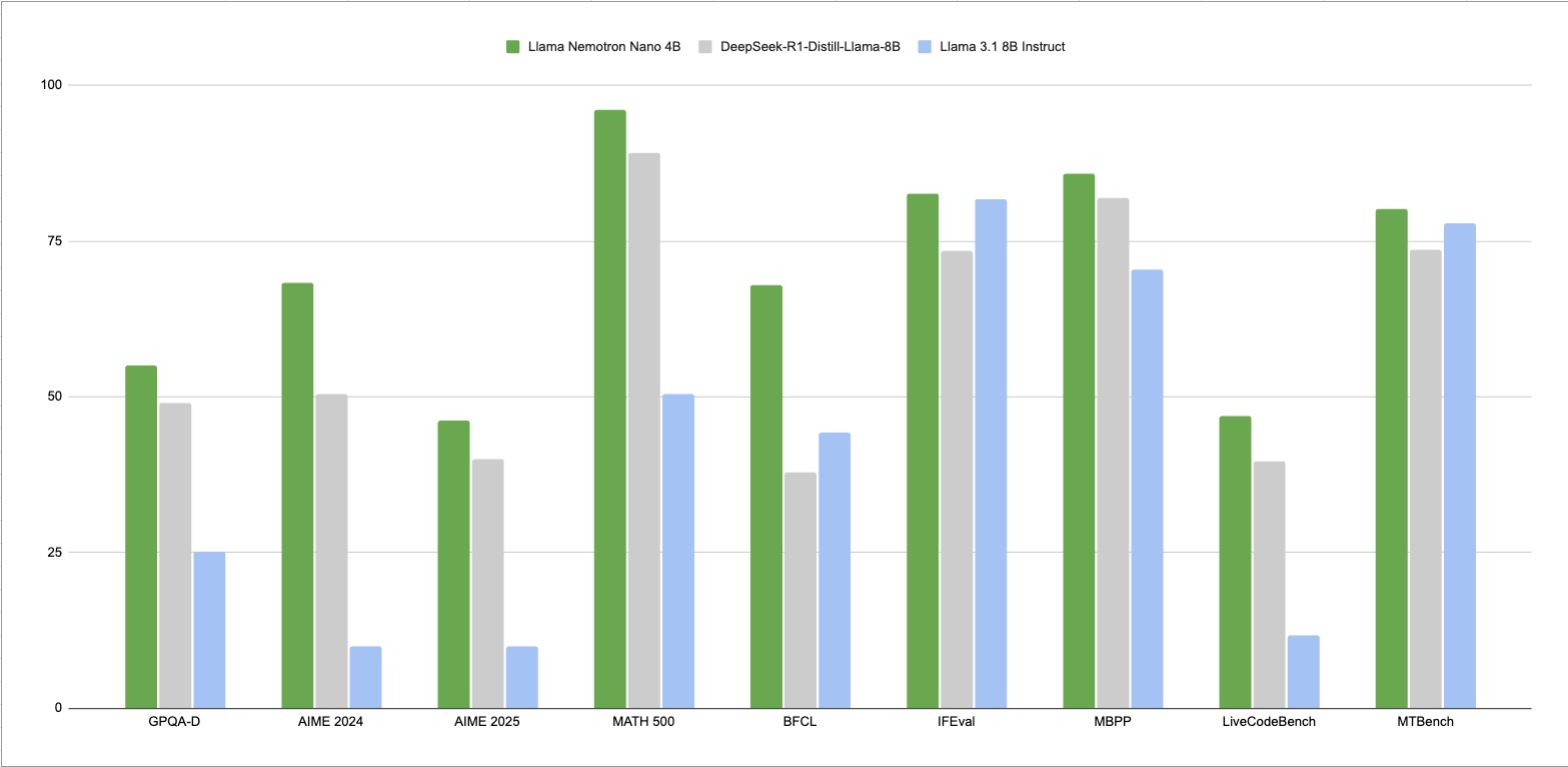
性能
MT-Bench
| Reasoning Mode | Score |
|---|---|
| Reasoning Off | 7.4 |
| Reasoning On | 8.0 |
MATH500
| Reasoning Mode | pass@1 |
|---|---|
| Reasoning Off | 71.8% |
| Reasoning On | 96.2% |
AIME25
| Reasoning Mode | pass@1 |
|---|---|
| Reasoning Off | 13.3% |
| Reasoning On | 46.3% |
GPQA-D
| Reasoning Mode | pass@1 |
|---|---|
| Reasoning Off | 33.8% |
| Reasoning On | 55.1% |
IFEval
| Reasoning Mode | Strict:Prompt | Strict:Instruction |
|---|---|---|
| Reasoning Off | 70.1% | 78.5% |
| Reasoning On | 75.5% | 82.6% |
BFCL v2 Live
| Reasoning Mode | Score |
|---|---|
| Reasoning Off | 63.6% |
| Reasoning On | 67.9% |
MBPP 0-shot
| Reasoning Mode | pass@1 |
|---|---|
| Reasoning Off | 61.9% |
| Reasoning On | 85.8% |


















 710
710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









