







1、FGSM原理
论文 Explaining and harnessing adversarial examples. 这篇论文由Goodfellow等人发表在ICLR2015会议上,是对抗样本生成领域的经典论文。
- FGSM(fast gradient sign method)是一种基于梯度生成对抗样本的算法,属于对抗攻击中的无目标攻击(即不要求对抗样本经过model预测指定的类别,只要与原样本预测的不一样即可)
- 我们在理解简单的dp网络结构的时候,在求损失函数最小值,我们会沿着梯度的反方向移动,使用减号,也就是所谓的梯度下降算法;而FGSM可以理解为梯度上升算法,也就是使用加号,使得损失函数最大化。先看下图效果,goodfellow等人通过对一个大熊猫照片加入一定的扰动(即噪音点),输入model之后就被判断为长臂猿。

公式
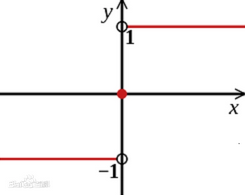
- 如下图,其中 x 是原始样本,θ 是模型的权重参数(即w),y是x的真实类别。输入原始样本,权重参数以及真实类别,通过 J 损失函数求得神经网络的损失值,∇x 表示对 x 求偏导,即损失函数 J 对 x 样本求偏导。sign是符号函数,即sign(-2),sign(-1.5)等都等于 -1;sign(3),sign(4.7)等都等于 1。sign函数图如下。
- ϵ(epsilon)的值通常是人为设定 ,可以理解为学习率,一旦扰动值超出阈值,该对抗样本会被人眼识别。

- 之后,原始图像x + 扰动值 η = 对抗样本 x + η 。
- 理解公式后,感觉FGSM并不难。其思想也和dp神经网络类似,但它更像是一个逆过程。我们机器学习算法中无论如何都希望损失函数能越小越好;那对抗样本就不一样了,它本身就是搞破坏的东西,当然是希望损失值越大越好,这样算法就预测不出来,就会失效。
2、pytorch实现
声明:代码来源于pytorch官网,跳转;你要是想看官网直接跳转即可,但是以下的内容我会讲解代码以及自己的理解。
-
下面代码需要下载预训练模型,将其放在如下代码指定文件夹下,预训练模型下载
-
pytorch不会 ?见 pytorch从基础到实战,做学术可离不开它勒。
2.1 建立模型
from __future__ import print_function
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import numpy as np
import matplotlib.pyplot as plt
# 这里的epsilon先设定为几个值,到时候后面可视化展示它的影响如何
epsilons = [0, .05, .1, .15, .2, .25, .3]
# 这个预训练的模型需要提前下载,放在如下url的指定位置,下载链接如上
pretrained_model = "data/lenet_mnist_model.pth"
use_cuda=True
# 就是一个简单的模型结构
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1338
1338

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









