






YOLOV7源码复现教程
1. 代码下载:
源码位置: https://github.com/WongKinYiu/yolov7,直接下载并解压
或可使用git复制代码: 'git clone https://gitee.com/YFwinston/yolov7.git'
2. 创建虚拟环境:
(1)Anaconda创建Yolo虚拟环境:
(2)安装需要的包: pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple。
此处需要注意CUDA和Pytorch的版本对应关系,否则会出错。
Previous PyTorch Versions | PyTorch。
本人电脑CUDA版本:10.2,对应下载Pytorch版本:
pip install torch==1.10.0+cu102 torchvision==0.11.0+cu102 torchaudio==0.10.0 -f https://download.pytorch.org/whl/torch_stable.html -i https://pypi.tuna.tsinghua.edu.cn/simple/
3. 验证环境配置是否成功:
(1)README文件中有对应的权重,可直接下载,放在weights文件夹下。
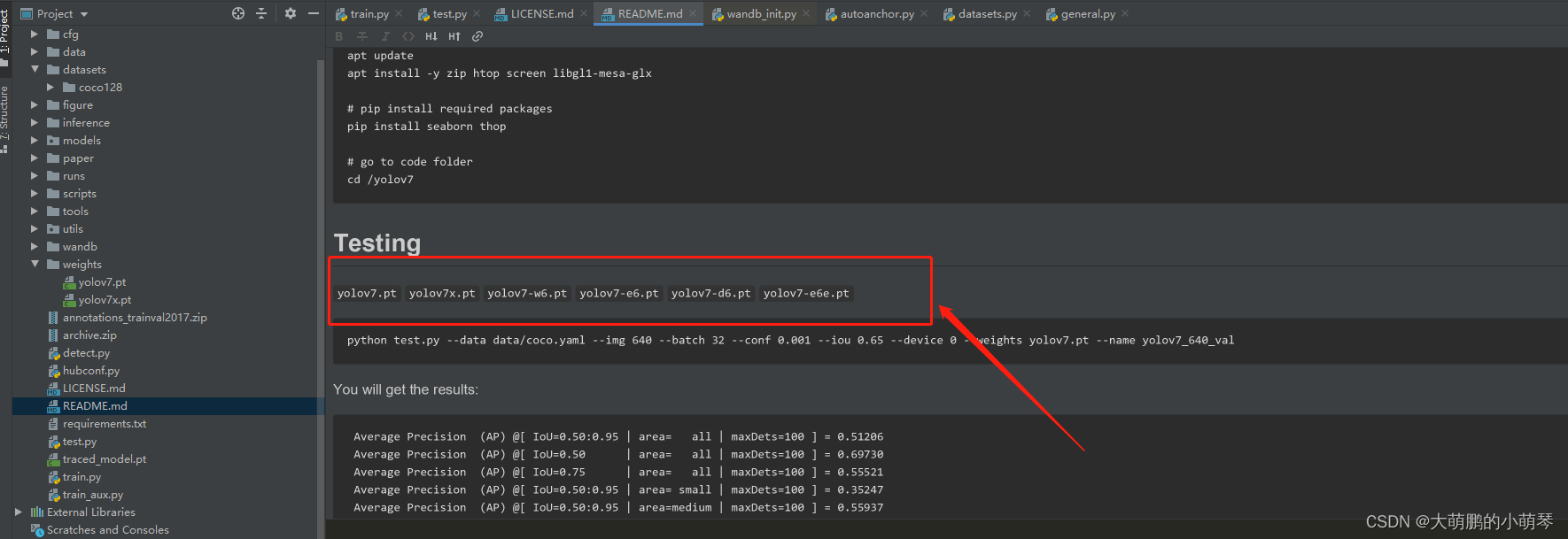
(2)运行脚本detect.py, 在某张图片上进行推理,得到的可视化结果保存在runs/detect中。其中需确认验证图片的路径是否正确。
python detect.py --weights weights/yolov7.pt --conf 0.25 --img-size 640 --source data/bdd100k/images/val/b1c66a42-6f7d68ca/b1c66a42-6f7d68ca-0000001.jpg
推理成功可生成runs文件夹,并保存图片到如下位置。说明可进行下一步工作。
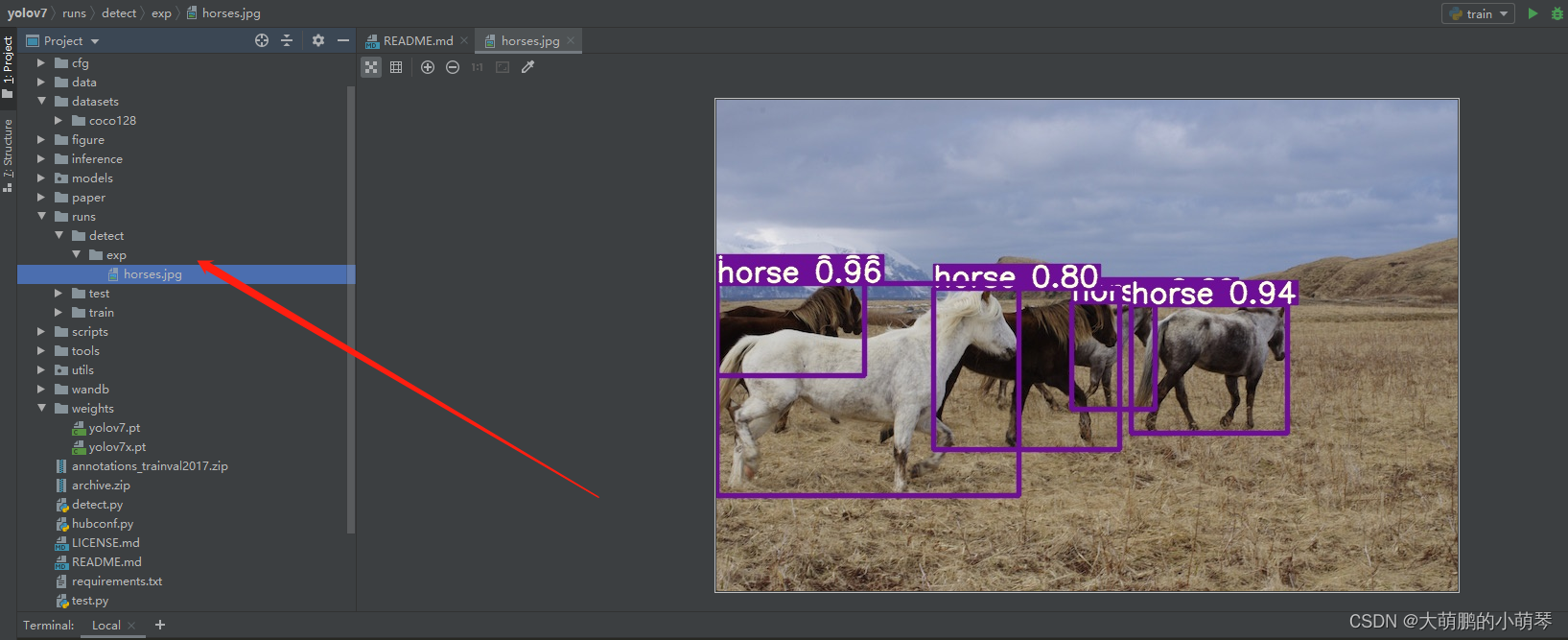
3.数据集准备:
数据集需要为Yolo数据格式
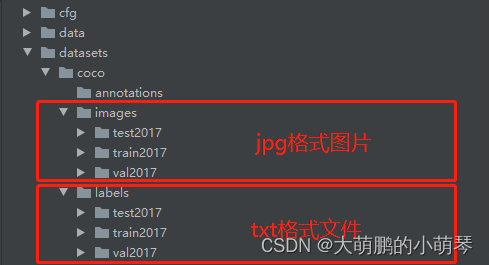
(1)将下载的coco数据集放在创建的datasets文件夹下,如下图所示。
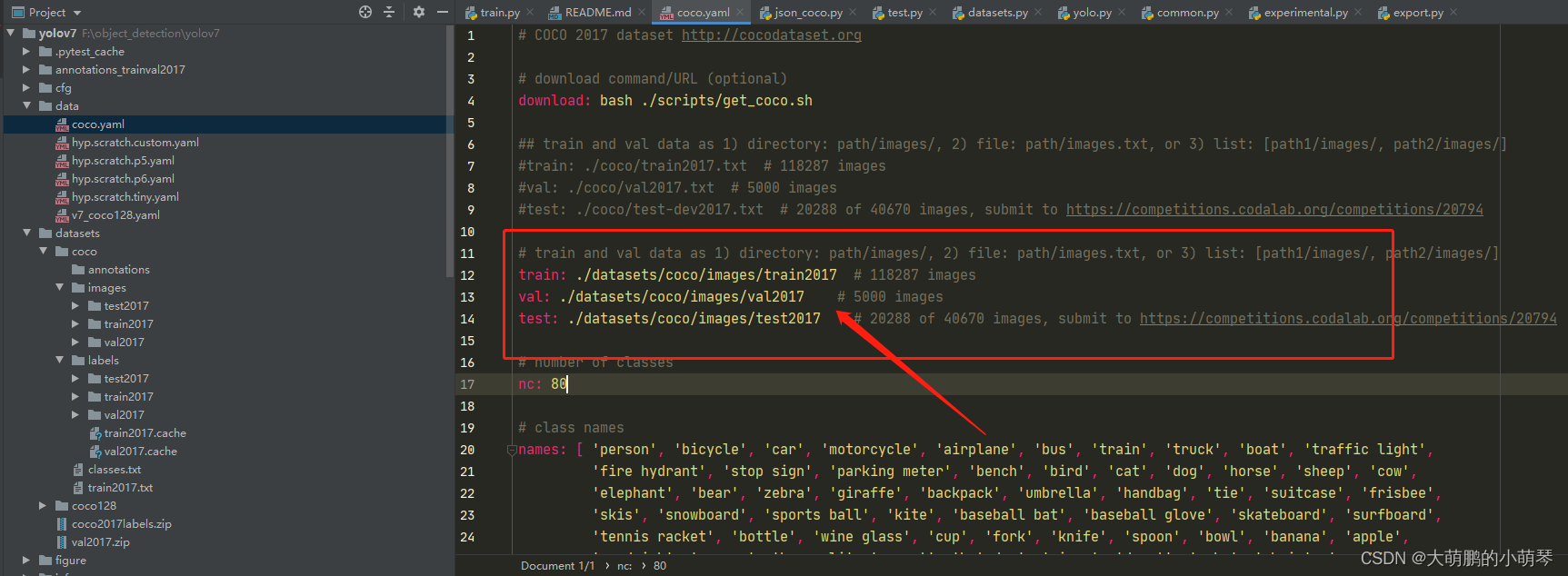
(2)在data文件夹下找到coco.yaml,将路径修改为自己的数据集的文件夹路径。
(3)修改train.py文件:需注意路径及文件名称。
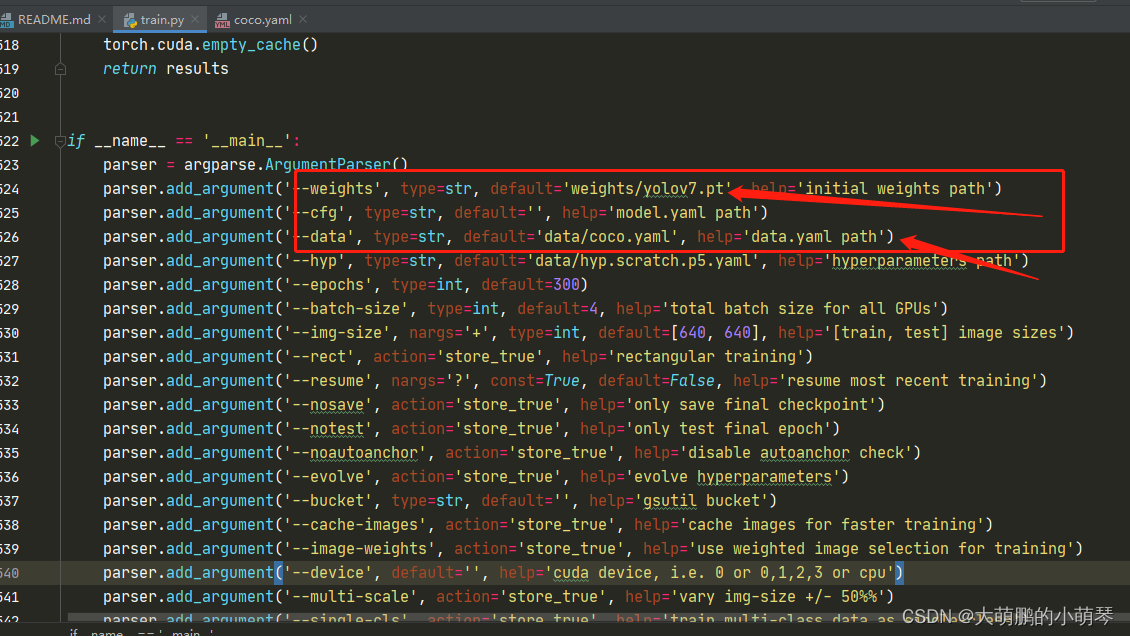
(4)接下来即可进行训练,但运行之后发现会有关wandb的报错。
UsageError: api_key not configured (no-tty). call wandb.login(key=[your_api_key])
这个报错一般是由于没有配置API key导致的,你需要按照以下步骤解决问题:
首先,登录到wandb网站并创建一个帐户:wandb注册登录 ,创建完用户并登录之后会跳转到以下页面,在该页面中复制API KEY的内容

其次,打开终端安装wandb: pip install wandb
安装好之后,输入以下代码:wandb login your_api_key
接着按ctrl+V粘贴上述在页面中复制的API KEY并回车。(注意:粘贴的内容不会在命令行显示,粘贴后直接回车即可)
以上完成即可进行训练。
4.训练及测试:
训练结果展示:
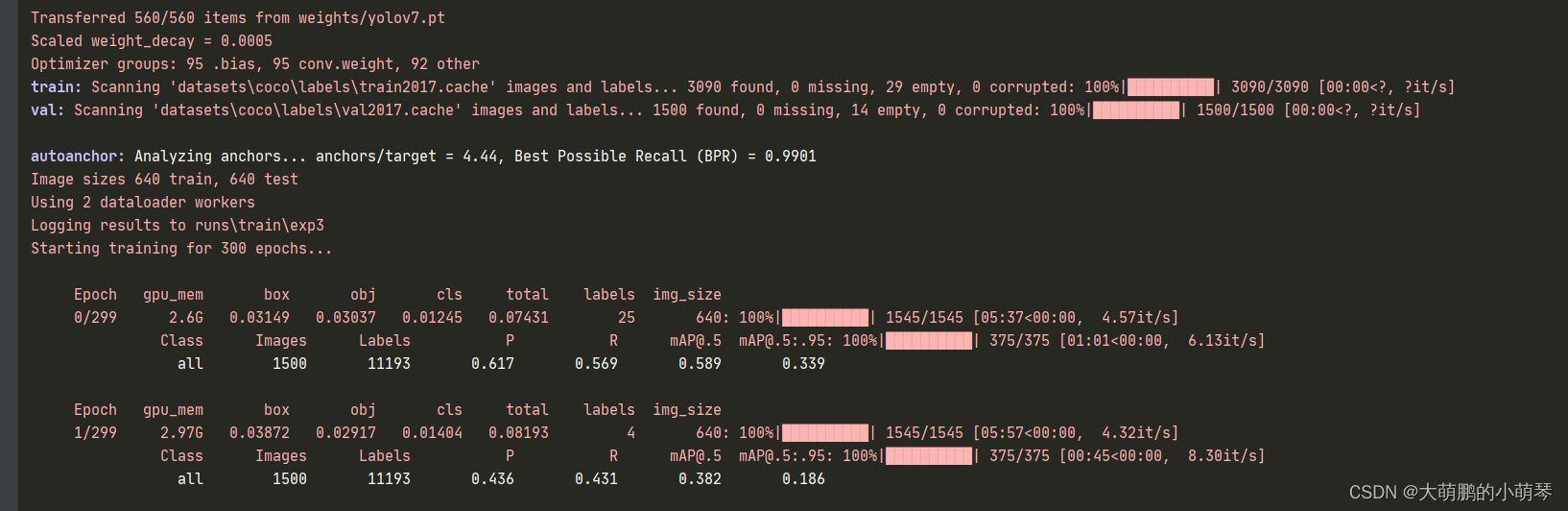
P:精度(找对的正类/所有找到的正类);
R:召回率(找对的正类/所有本应该被找对的正类);
mAP: 是用Precision和Recall作为两轴作图后围成的面积,m表示平均,@后面的数表示判定iou为正负样本的阈值。
mAP@.5 :将IoU设为0.5时,计算每一类的所有图片的AP,然后所有类别求平均,即mAP
mAP@.5:.95:表示在不同IoU阈值(从0.5到0.95,步长0.05)(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的平均mAP。















 2990
2990











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









