







 文章介绍了FC-CLIP模型在解决少样本视觉检测和分割任务中的优势,特别是在数据不足情况下,其基于CNN的结构使得模型在大尺度输入和部署效率上优于Transformer。FC-CLIP在ADE20k上的表现超越了其他大模型,且在业务数据集上展现了显著效果。
文章介绍了FC-CLIP模型在解决少样本视觉检测和分割任务中的优势,特别是在数据不足情况下,其基于CNN的结构使得模型在大尺度输入和部署效率上优于Transformer。FC-CLIP在ADE20k上的表现超越了其他大模型,且在业务数据集上展现了显著效果。
概要
传统的检测网络和分割网络, 在开源数据集上效果很好,依赖于大量的有label的数据集。然而,实际视觉项目中,数据集不足或数据集难获取是一种常态,少样本的视觉检测分割方法显得尤为重要。 视觉大模型可以很好的解决这一问题,视觉大模型可以用很少的数据量达到很好的效果。 在分割任务方面,FC-CLIP模型相比SAM系列有明显的性能及效果优势,作者详细介绍一下FC-CLIP模型。
Convolutions Die Hard: Open-Vocabulary Segmentation with Single Frozen Convolutional CLIP
FC-CLIP论文链接:https://arxiv.org/abs/2308.02487
FC-CLIP官方github代码:https://github.com/bytedance/fc-clip
整体架构流程
首先看一下网络结构图
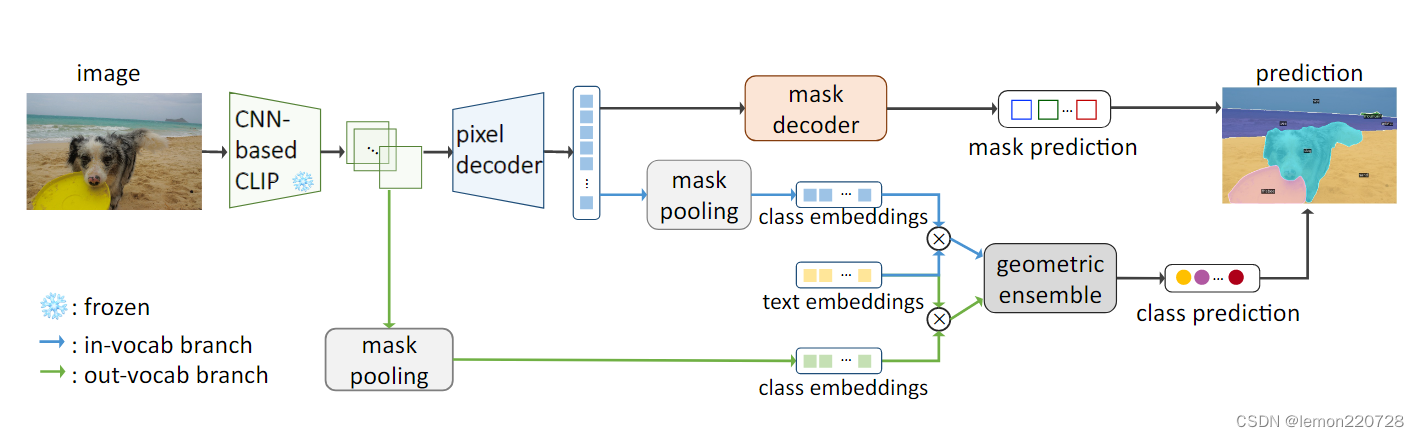
-
论文给出的网络结构图是训练和推理合在一起的网络结构图。
训练的时候out-vocab branch是不参与的, 只有in-vocab branch参与。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









